
【论文阅读】Deep Text Classifification Can be Fooled
**时间:**2017
**作者:**Bin Liang, Hongcheng Li, Miaoqiang Su, Pan Bian, Xirong Li and Wenchang Shi 中国人民大学
Abstract:
在这篇文章,我们提出了一种有效的生成文本对抗样本的方法,并且揭示了一个很重要但被低估的事实:基于DNN的文本分类器很容易被对抗样本攻击。
具体来说,面对不同的对抗场景,通过计算输入的代价梯度(白盒攻击)或生成一系列被遮挡的测试样本(黑盒攻击)来识别对分类重要的文本项。(这句不是很懂,什么叫’ the text items that are important for classifification‘?)
基于这些项目,我们设计了三种扰动策略,insertion,modification,removal,用于生成对抗样本。实验结果表明基于我们的方法生成的对抗样本可以成功地欺骗主流的在字符等级和单词等级的DNN文本分类器。
对抗样本可以被扰动到任意理想的类中而不降低其效率。(?)同时,被引入的扰动很难被察觉。
1. Introduction:
在文本中,即使很小的扰动也会使一个字母或者单词完全变化,这会导致句子不能被辨识。故如果直接将应用于多媒体(图片,音频)的算法应用到文本上,得到的对抗样本的原意就会改变,而且很大程度上变成人类无法理解的句子。
在这片论文里,我们提出了一种生成对抗样本的有效方法。与直接简单插入扰动相比,我们设计了三种扰动策略:insertion, modifification, and removal,并且引入了自然语言文本水印(natural language watermarking)技术用于生成对抗样本。
理论上,生成一个好的对抗样本很大程度上依赖于对目标分类模型的信息。在这里我们根据不同情形,使用了白盒攻击和黑盒攻击。
为了普遍性,我们使用了字符等级的模型和单词等级的模型作为受害者。我们的实验结果证明基于DNN的文本分类器在面对对抗样本攻击时是脆弱的。
2. Target Models and Datasets:
这里使用的文本分类器是Zhang et al. 2015《Character-level Convolutional Networks foe Text Classification》,数据集是Lehmann et al.2014的DBpedia ontology dataset(一个多语言知识库),里面包括560000个训练样本和70000个测试样本,涵盖14个high-level 类,比如公司类、建筑类、电影类等。
在把样本送进网络前,需要用独热编码法(one-hot representation)对每个字母编码成一个向量。通过网络的六个卷积层、三个全连接层,最终会被分到14个类中。
3. White-Box-Attacks:
3.1 FGSM算法:
FGSM是Goodfellow在2015年提出的对图片生成对抗样本的经典算法。使用类似的思路来在文本领域生成对抗样本结果并不好:

3.2 Idenfitying Classification-important Items:
在白盒攻击中,我们需要定位文本中对于分类器的分类结果起到很大作用的文本段(通过计算代价梯度)。在这里,我们使用**Hot Training Phrases (HTPs)**代表最常使用的短语:
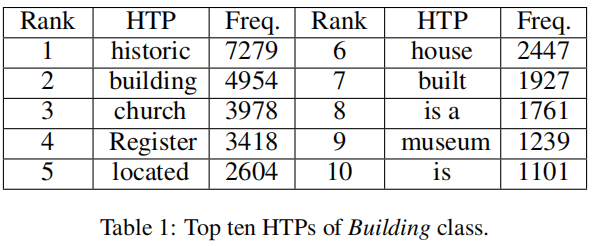
HTPS表明了用什么短语/词去做扰动,但是没有说在哪里做。在这里使用**Hot Sample Phrases (HSPs)**来表明在哪里做扰动。
3.3 Attacking Character-level DNN:
我们的方法是一种targeted攻击,可以指定对抗样本的误导类型。
3.3.1 Insertion Strategy(插入策略):
在某个HSP前插入一个HTP,就可以达到效果:

由上图可以看到,将某个HTP(historic)插入到HSP(principal stock exchange of Uganda. It was founded)之前,就可以使一个公司的分类文本变为对建筑的分类。
实际上,我们通常需要进行多次插入,但插入次数过多会影响样本的效用和可读性,为了解决这个问题,这里引入NL水印技术(Natural Language watermarking technique)。该技术可以通过语义或句法操作将所有权水印隐形地嵌入到普通文本中,虽然我们的攻击目标与NL水印有本质的不同,但我们可以借用它的思想来构造对抗样本。实际上,扰动可以看作是一种水印,并以类似的方式嵌入到样本中。
在这里,我们拓展这个思路,在样本中插入Presupposition(读者熟知的模糊短语)和 semantically empty phrases(可有可无的短语),有没有他们,在读者看来,原文的意思不会改变。
总的来说,我们考虑将各种HTPS组合成一个语法单元后再嵌入到文本中,新的单元可以是生成的可有可无的资料,或者甚至是不会改变文本原意的伪造的资料。

特别的,通过互联网搜索或者查找一些数据集,我们可以找到与插入点很相关的资料,包括一些期望的目标分类的HTPs。
由于我们不能总是找到合适的HTPs,所以提出一个新概念——伪造的事实(forged fact),也就是插入很难证伪的HTPs。例如:

此外,我们排除了伪造的事实,这些事实可以通过检索他们在网上的相反证据而被否认。
3.3.2 Modification Strategy(修改策略):
Moidfication就是轻微修改一些HSP。
为了让修改不被人类观察者发现,我们采用了typo-based watermarking 技术。具体的说,一个HSP可以通过两种方式来被修改:
1. 从相关的语料库中选择常见的拼写错误来替换它;
2. 把它的一些字符修改成类似的外观(例如小写字母’l’与阿拉伯数字‘1’很像)。

由上图可以看出,这种方式对分类结果的扰动是巨大的。
3.3.3 Removal Strategy(移除策略):
移除策略单独使用也许并不能足够有效地影响预测结果,但是可以很大程度上降低原始预测类型的置信度。
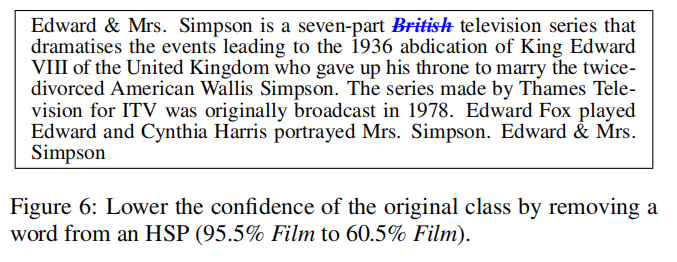
由上图可以看出,移除’British‘可以导致原始预测类型的置信度下降了35%。
3.3.4 Combination of Three Strategies:
如图6所示,单靠去除策略改变输出分类往往是困难的。但是,通过与其他策略相结合,可以避免对原文进行过多的修改或插入。在实践中,我们常常结合以上三种策略来制作微妙的对抗样本。

以图7为例,通过去除一个HSP、插入一个伪造事实和修改一个HSP,可以成功地改变输出分类,但单独应用上述任何扰动都失败。具体来说,删除、插入和修改仅使置信度分别下降27.3 %、17.5 %和10.1 %,保持预测类不变。
4. Black-Box-Attack:
暂略
5. Evaluation:
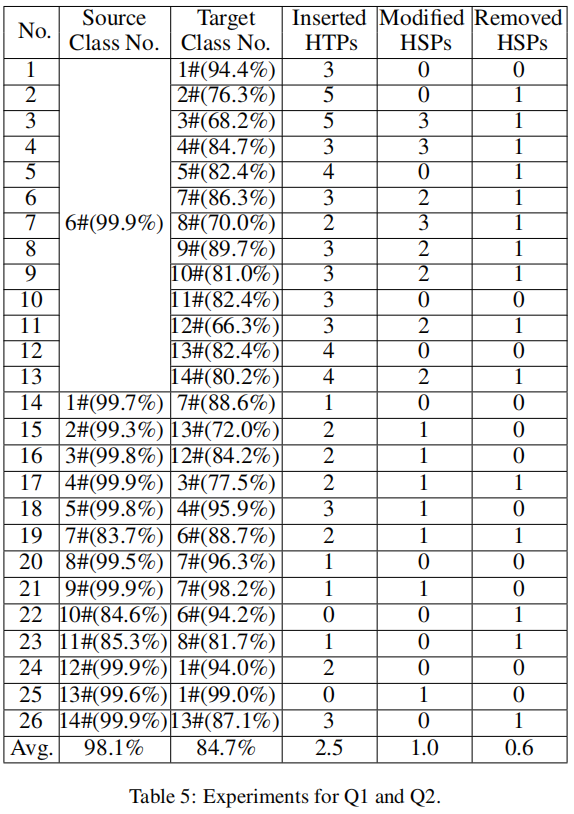
5.1 我们的方法能否执行有效的源/目标误分类攻击?
***答:***在众多测试集中,只有DBpedia ontology数据集是一个多分类数据集,故我们在其中随机选取了一些样本:
5.2 所生成的对抗样本能否避免被人类观察者认出来,并同时保持其功能性?
***答:***我们找了23个学生。他们对项目不了解,然后每个人给20个文本,其中一半是加扰的。让他们分到14个类中,如果他们觉得哪个文本不对劲,让他们指出来。
他们总的分类正确率是94.2%,10个对抗样本的正确率是94.8%。所以实用性还是有的。
他们标注出了240项修改处,其中12项符合真实的修改。但实际上我们做了594处修改。
5.3 我们的方法足够有效吗?
***答:***实验中计算梯度和找HTPs花了116小时。14个类的HTPs每个类花了8.29小时。对所有的adversarial示例只执行一次计算。制作一个对抗性的样品大约需要10到20分钟。对于对手来说,获得理想的对抗样本是可以接受的。实际上,她或他愿意花更多的时间来做这件事。
6. Realted Works:
**可以做的方向:**1.自动生成对抗样本;(然而,Papernot等人(Papernot et al. 2016a)提出了一种基于雅可比矩阵的数据集增强技术,该技术可以在不访问其模型、参数或训练数据的情况下,在有限对输入输出的基础上,为目标dnn提供替代模型。作者还表明,使用替代模型也可以有效地制作对抗样本,以攻击目标DNN。)2.迁移、黑盒攻击;