
【论文阅读】Learning to Communicate with Deep Multi-Agent Reinforcement Learning
作者:Jakob N. Foerster ,Yannis M. Assael ,Nando de Freitas,Shimon Whiteson(哈佛大学,Google Deepmind)
时间:2017
Abstract:
我们考虑这样一个问题:多个智能体在环境中通过感知和行动来最大化他们的分享能力。在这些环境中, 智能体必须学习共同协议以此来分享解决问题的必要信息。通过引入深度神经网络,我们可以成功地演示在复杂的环境中的端对端协议学习。我们提出了两种在这个领域学习的方法:**Reinforced Inter-Agent Learning (RIAL) **和 Differentiable Inter-Agent Learning (DIAL)。
前者使用深度Q-learning,后者揭示了在学习过程中智能体可以通过communication channels反向传播错误的梯度,因此,这种方法使用集中学习(centralised learning),分散执行(decentralised execution)。
我们的实验介绍了用于学习通信协议的新环境,展示了一系列工程上的创新。
PS:
1. 端对端(end-to-end,e2e), 将多步骤/模块的任务用一个步骤/模型解决的模型。
可以理解为从输入端到输出端中间只用一个步骤或模块,比如神经网络训练的过程就是一个典型的端对端学习,我们只能知道输入端与输出端的信息,中间的训练过程就是一个黑盒,我们知晓中间的训练过程。
2.centralised learning* but *decentralised execution,中心化学习但是分散执行。
1. Introduction
1.1 回答的问题:
1. 智能体之间如何使用机器学习来自动地发现符合他们需求的通信规则?
2. 深度学习也可以吗?
3. 我们能从智能体之间学习成功或者失败的经验中学到什么?
1.2 研究思路:
- 提出一系列经典需要交流的多智能体任务,每个智能体可以采取行动来影响环境,也可以通过一个离散的有限带宽的通道来跟其它有限的智能体进行通信;
- 为1中的任务制定几个学习算法,由于每个智能体的观察范围有限,同时通信通道能力有限,所有智能体必须找到一个可以在此限制下帮助他们完成任务的通信规则;
- 分析这些算法如何学习通讯规则,或者如何失败的。
1.3 主要贡献:
提出两个方法,**reinforced inter-agent learning(RIAL)**和 differentiable inter-agent learning (DIAL)
结果表明,这两种方法在MNIST数据集上可以很好的解决问题,并且智能体们学到的通信协议往往十分优雅。
结果同样指出深度学习更好的利用了中心化学习的优点,是一个学习这样通信协议的有力工具。
2. Related Work
3. Background
3.1 Deep Q-Networks(DQN)
Deep Learning + Q-Learning,在游戏领域应用广泛。
3.2 Independent DQN·
3.3 Deep Recurrent Q-Networks
4. Setting
在强化学习的背景下,每个智能体的观察能力有限。
所有智能体的共同目标就是最大化同一个折算后的总奖赏Rt,但同时,没有智能体可以观察到当前环境隐藏的马尔科夫状态St,每个智能体a分别接收到一个与St相关的观察值相关联的值$O^{a}_{t}$。
在每一步t,每个智能体选择一个environment action $u^{a}{t}$来影响环境,同时选择一个communication action $m^{a}{t}$来被其他智能体观察,但$m^{a}_{t}$对环境没有直接影响。
没有通信协议被预先给定,智能体们需要自己学习。
由于协议是从动作观测历史到消息序列的映射,所以协议的空间维度是非常高的。自动地在这个空间发现有效的通信协议是非常困难的,这体现在智能体需要协调发送消息和解释消息。举个例子,如果一个智能体发送了一个有效的信息,它只有在接受方正确解释并回应的情况下才会受到正反馈,如果没有,反而会打击其发送有效信息的积极性。
因此,积极的reward是稀少的,只有在发送和解释协调操作时才会发生,这通过随机探索很难实现。
在这里,我们聚焦于centralised learning* but *decentralised execution的情况,在学习的时候智能体之间的通信没有限制,在实施过程时,智能体之间仅仅能通过一条带宽有限的通道通信。
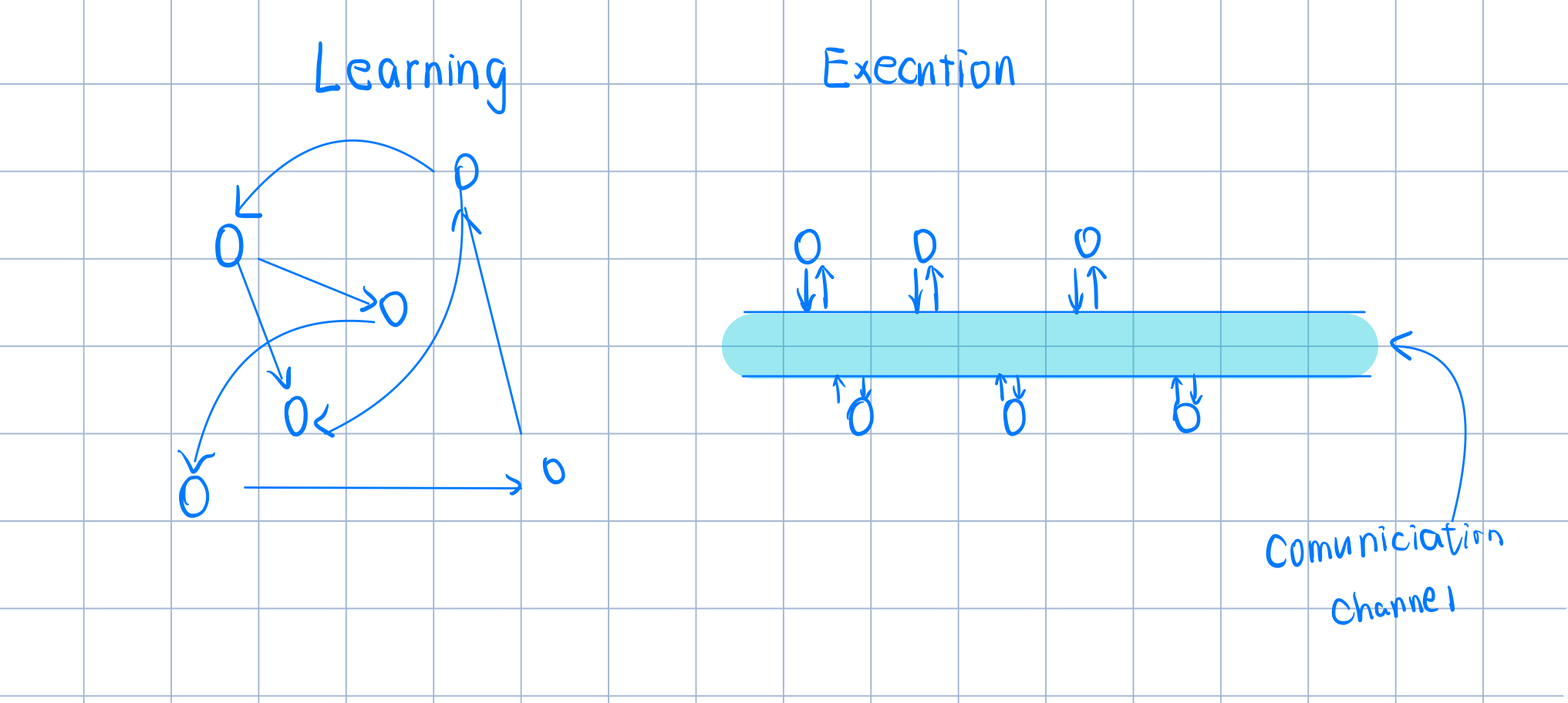
5. Methods
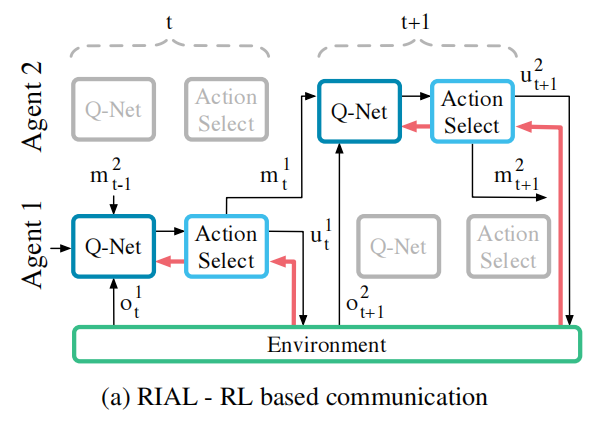
5.1 RIAL(Reinforced Inter-Agent Learning)
简单直接的说,RIAL就是将DRQN(Deep Recurrent Q-Learning)与Q-learning相结合来进行action(影响环境)与communication(与其它智能体通信)选择的方法。
每个智能体的Q-network可以表示为:$Q^{a}(o^{a}{t},m^{a^{,}}{t-1},h^{a}_{t-1},u^{a})$。
四个参数分别代表:环境观察值,其它智能体上一步传来的消息,智能体自己的隐藏状态,选择的action。
如果直接学习输出最终的Q表,得到的输出将有|U||M|大小。为了避免输出过大,将Q-network拆分为两个$Q^{a}{u}$与$Q^{a}{m}$,分别表示影响环境的action与同智能体的通信(communication),学习方式使用ε-贪心算法。
$Q^{a}{u}$与$Q^{a}{m}$都使用DQN训练方法,但所使用的DQN有以下两点改进:
- 禁止experience replay;
- 为了考虑部分可观测性,我们将每个智能体所采取的操作u和m作为下一步的输入;
RIAL可以扩展到通过在智能体之间之间共享参数来利用集中学习,在这种情况下,由于智能体观察不同,因此也进化出了不同的隐藏状态。参数共享大大减少了必须学习的参数数量,从而加快了学习速度。
在参数共享情况下,智能体学习两个Q函数$Q_{u}(o^{a}{t},m^{a^{,}}{t-1},h^{a}{t-1},u^{a}{t-1},m^{a}{t-1},a,u^{a}{t})$与$Q_{m}(o^{a}{t},m^{a^{,}}{t-1},h^{a}{t-1},u^{a}{t-1},m^{a}{t-1},a,u^{a}{t})$。
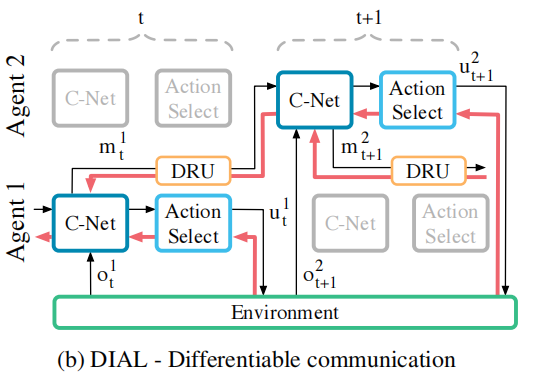
5.1 DIAL(Differentiable Inter-Agent Learning)
虽然RIAL可以进行参数共享,但其仍不能在通信过程中给其他智能反馈。
打个比方,在人类通信活动中,listener即使不说话也会给出及时,丰富的反馈来表明listener对谈话的兴趣和理解程度,而RIAL反而缺少了这个反馈机制,仿佛对着一个面无表情的人在说话,显然,这个方式存在缺点。
DIAL就是为了解决这个问题而存在的,通过结合centralised learning与Q-networks,不仅可以共享参数,而且可以通过通信信道将梯度从一个Agent推向另一个Agent。
6. Experiments
在测试中,我们评估了RIAL与DIAL在有无参数共享的情况下进行多智能体任务的情况,并跟一个无交流,参数共享的基准方法进行比较。
在整个过程中,奖励是通过访问真实状态( Oracle )所能获得的最高平均奖励来规范的。
我们使用ε-贪心算法(ε = 0.05)。
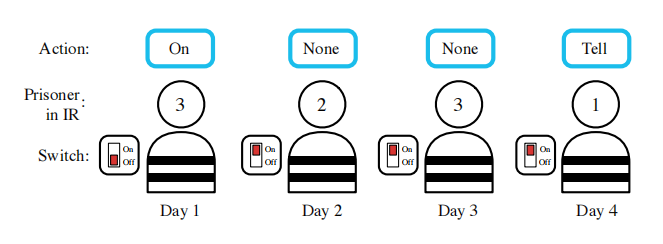
6.1 Switch Riddles(开关谜题)
一百名囚犯入狱。典狱长告诉他们,从明天开始,每个人都会被安置在一个孤立的牢房里,无法相互交流。每天,监狱长都会随意统一挑选其中一名被替换的犯人,并将其安置在中央审讯室,室内只装有一个带有切换开关的灯泡。囚犯将能够观察灯泡的当前状态。如果他愿意,他可以拨动灯泡的开关。他还可以宣布,他相信所有的囚犯都已经访问了审讯室。如果这个公告是真的,那么所有囚犯都被释放,但如果是假的,所有囚犯都被处死。
6.2 Results1
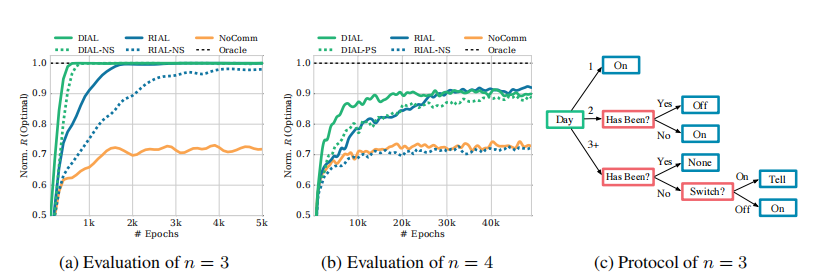
(a)可以看到,在n=3时四种方法的效果都比Baseline的效果好,参数共享加速了算法。
(b)在n=4时,参数共享的DIAL方法最好。不带参数共享的RIAL没有baseline效果好。可以看出,智能体们独立的学习出相同的策略是很难的。
(c)n=3时智能体使用DIAL学习到的策略。
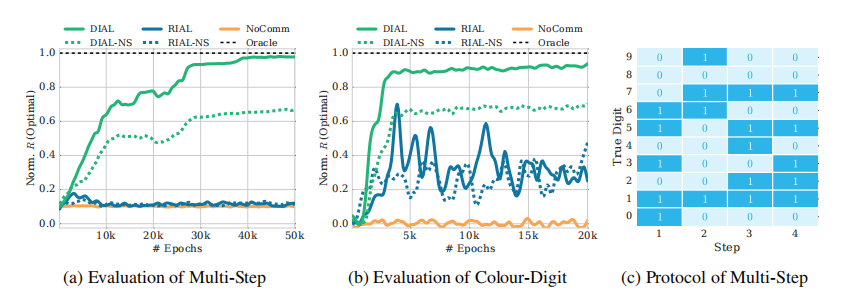
6.3 Colour-Digit MNIST
6.4 Effect of Channel Noise
这里没太看懂