【论文阅读】Learning Multiagent Communication with Backpropagation
作者: Sainbayar Sukhbaatar,Rob Fergus, Arthur Szlam(纽约大学,FacebookAI)
**时间:**2016
**出版社:**NIPS
Abstract
在AI领域许多任务都需要智能体之间的同心合作,一般地,代理之间的通信协议是人为指定的,其并不在训练过程中改变。在这篇文章中,我们提出了一个简单的神经模型CommNet,其使用持续不断的通信来完成完全合作的任务。该模型由许多代理组成,他们之间的通信基于设定的策略学习,我们将此模型应用于一系列不同的任务中,显示了代理学会相互通信的能力,从而比非通信代理的模型和baselines有更好的性能。
1. Introduction
虽然控制每个代理的模型是通过强化学习来学习的,但通信的规范和格式通常是预定的。
在本工作中,每个代理单元都被一个深度前馈神经网络控制,这个网络接入了一个携带连续向量的通信信道。在这个通信信道中每个代理传输的内容不是被指定的,而是通过学习得来的。因为communication是连续的,因此模型可以通过反向传播训练得到。这样就可以结合标准的单智能体RL算法或者监督学习。此外,该模型允许代理的数量和类型在运行时动态变化,这在移动汽车之间的通信等应用中很重要。
我们考虑的是我们有J个代理的环境,所有的合作都是为了在某些环境中最大化报酬R。我们简化了代理人之间充分合作的假设,从而每个代理人收到R独立于他们的贡献。在此设置中,每个代理都有自己的控制器,或者将它们看作控制所有代理的更大模型的一部分,这两者之间没有区别。从后一个角度来看,我们的控制器是一个大型的前馈神经网络,它将所有Agent的输入映射到它们的动作上,每个Agent占据一个单元的子集。
我们在两种任务下探索这个模型,在有些情况下,对每项行动都提供监督,而对另一些行动则零星地给予监督。在前一种情况,每个代理单元的控制器通过在连接模型中反向传播错误信号来学习;在后一种情况下,强化学习必须被作为一个额外的外部循环使用,为了给每个时间步骤提供训练信号。
2. Communication Model
我们现在描述一个模型,用来计算在给定时间t (省略时间指标)下动作p ( a ( t ) | s ( t ),θ )的分布。
Sj 表示第j个代理单元所观测到的环境信息,将所有Sj合并就成了控制器的输入S = {S1,S2…… SJ}。
控制器的输出a = {a1,a2…… aJ},表示各个代理单元会做出的动作。

该框架中所有灰色模块部分的参数均是所有智能体共享的,这一定程度上提升了算法的可扩展性。从上图可以看出,算法接收所有智能体的局部观察作为输入,然后输出所有智能体的决策。
本算法采用的信息传递方式是采用广播的方式,文中认为可以对算法做出些许修改,让每个智能体只接收其相邻k个智能体的信息。
拿上图中间的框架图来说明,即上层网络每个模块的输入,不再都是所有智能体消息的平均,而是每个模块只接受满足条件的下层消息的输出,这个条件即下层模块对应的智能体位于其领域范围内。这样通过增加网络层数,即可增大智能体的感受野(借用计算机视觉的术语),从而间接了解全局的信息。
除此之外,文中还提出了两种对上述算法可以采取的改进方式:
- 可以对上图中间的结构加上 skip connection,类似于 ResNet。这样可以使得智能体在学习的过程中同时考虑局部信息以及全局信息,类似于计算机视觉领域 multi-scale 的思想
- 可以将灰色模块的网络结构换成 RNN-like,例如 LSTM 或者 GRU 等等,这是为了处理局部观察所带来的 POMDP 问题。
3. Related Work
4. Experiments
4.1 Baselines(3个):
**Independent controller: **每个代理单元都被独立控制,他们之间相互没有通信。这个模型的好处是智能体可以自由加入或者离开队伍,但是很难将智能体学会合作。
**Fully-connected: **创建一个全连接层的多代理神经网络,这个模型运行智能体之间互相通信,但是这个模型不够灵活,也就是说智能体的数目必须固定。
Discrete communication: 通过在训练中学习到的symbols来通信。因为在这个模型中存在离散的操作,并且这个操作不可微分,这种情况一般使用强化学习。
4.2 Simple Demonstration with a Lever Pulling Task
任务:一共有m个杆子,N个智能体。在每个回合,m个智能体从N个智能体中随机取出,然后他们要选择拉动的杆子。他们的目标是尽可能的拉动不同的杆子,他们的奖励正比于拉动的不同杆子的数量。
测试结果:
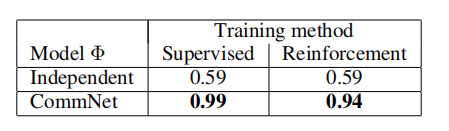
可以看出,CommNet的结果非常好。
4.3 Multi-turn Games
任务:
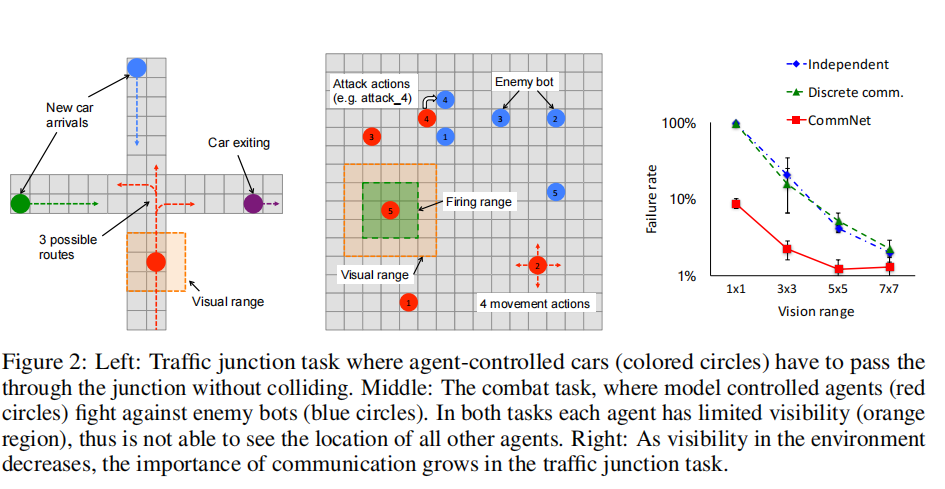
**Traffic Junction: **控制车辆通过交通枢纽,使流量最大的同时保证不发生碰撞;
**Combat Task: ** 多个智能体攻击其他多个敌方单位。