HydraText: Multi-objective Optimization for Adversarial Textual Attack
作者:Shengcai Liu,Ning Lu,Cheng Chen,Chao Qian,Ke Tang
时间:2021
ABSTRACT
文字(text)(word-level)对抗样本黑盒攻击。在这项工作中,同时考虑攻击效率+可辨认性,并提出一种新的具有可证明性能保证的多优化方法(称为HydraText ),以实现具有高隐蔽性的成功攻击。
为了测试HydraText的功效,我们在score-based 和decision-based的黑盒攻击下,使用5个NLP模型+5个数据集。
(PS:[论文总结] Boundary Attack - 知乎 (zhihu.com))
一项人类观察评价研究表明,Hydra Text制作的对抗样本很好地保持了有效性和自然性。最后,这些实例还表现出良好的可迁移性,可以通过对抗训练给目标模型带来显著的鲁棒性提升。
INTRODUCTION
我们仔细地设计了目标函数,并进一步构建了一个多目标优化问题(multi-objective optimization problem,MOP),该问题一旦被解决,将产生与原始文本相似度高的单个成功对抗样本。
然后我们原创了一个多目标优化方法( multi-objective optimization approach),叫做HydraText。这个名字的灵感来自于海蛇许德拉,这是一种神话动物,它使用多个头部攻击对手。它可以同时用在score-based 和decision-based的黑盒攻击下。
METHODS
基于word-level 的替换操作。每个单词有一个自己的候选表,然后将每个单词与候选表中被选中的词替换(也可以不选,原单词不变)。
但这样的方法有个问题,如下图:

如图所示,句子的语义与替换的单词数量是成反比的,上文需要考虑的准确率+可辨认性二者其实是互相矛盾的。为了解决这个问题,我们在生成的过程中也考虑Xadv的修改率,使用MOP来解决它。
1.The HydraText Approach

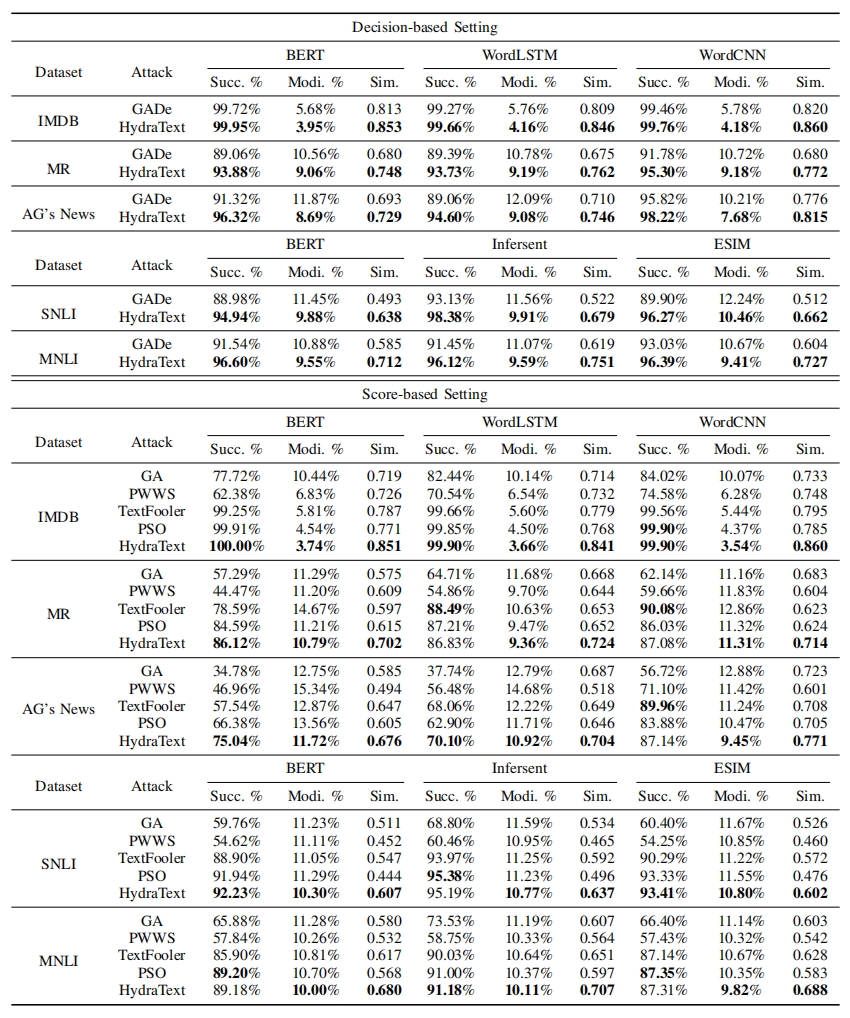
EXPERIMENTS
1. Datasets and Target Models
**模型种类:**文本分类和文本推理
三个数据集:AG News,IMDB , Movie Reviews,Stanford Natural Language Inference,multi-genre NLI corpus(前三个文本分类,后三个文本推理)
两个模型:WordCNN,WordLSTM,BERT base-uncased,ESIM ,Infersent ,BERT base-uncased(前三个文本分类,后三个文本推理)
2.Baselines and Algorithm
**攻击方法:**PSO,GA,TextFooler,PWWS,GADe(baseline)
3.Evaluation
以攻击成功的百分率来判定攻击能力。
以修改百分率和语义相似性来判定攻击的可辨识性。