
参考资料:
- Reinforcement Learining. Second Edition. Sutton.Page 180-193
- 白板推导–强化学习.shuhuai008.Bilibili
- Easy RL.Qi Wang.Yang Yiyuan.Ji Jiang
Planning at Decision Time(决策时规划)
规划(Planning)至少有两种使用方式。
①一种在DP和Dyna中已经讨论过,通过从一个model(不论是sample model或是distribution model )中获取模拟经验(simulated experience)的基础上来使用规划来逐渐提升一个policy或一个value function。
然后,选择动作是一个比较当前状态的动作value问题,该value是在之前优化的表格中获取的;或者通过使用书中Part 2中考虑的近似方法来评估数学表达式。
对于任意状态St,在为其选择一个动作之前,其整个表格条目(例如Dyna-Q中的Q表)已经通过规划来优化过了。使用这种方式,规划并不是仅仅聚焦于当前的状态,我们称这种规划为background planning,后台规划。
②另一种使用规划的方法就是在遇到每个新的状态St后再开始一个完整的规划过程,其为每个当前状态选择一个动作At,到下一个状态St+1就选择一个动作At+1,以此类推。
一个使用这种规划最简单的例子:当state values可用时,通过比较当前model对执行每个动作后到达的新状态的value来选择一个动作。
当然,更普遍的说,这种规划的用法可以比仅仅往后看一步(上面的例子就是)看得更深,评估动作的选择导致许多不同预测状态和奖励轨迹。
不同于第一种用法,在这里,规划聚焦于一个特定的状态,我们称之为decision-time planning,决策时规划。
这两种规划的方式可以用一种自然而有趣的方式结合在一起,不过一般二者被分开研究。
如同background planning,我们仍可以将决策时规划看作一个从模拟经验中更新values,最后到更新policy的过程。只是基于当前状态所生成的values和policy会在做完动作选择决策后被丢弃,在很多应用场景中这么做并不算一个很大的损失,因为有非常多的状态存在,且不太可能在短时间内回到同一个状态,故重复计算导致的资源浪费会很少。
一般来说,人们可能希望将两者结合起来:规划当前状态,并将规划的结果存储起来,以便在以后回到相同的状态时能走得更远。
Decision-time Planning,(决策时规划)在不需要快速反应的应用场景中作用最为显著。
决策时规划的常用算法有Heuristic Search(启发式搜索)、Rollout Algorithms(Rollout 算法)和Monte Carlo Tree Search(MCTS 蒙特卡洛树搜索)三种。
Heuristic Search(启发式搜索)
在AI中一个经典的状态空间规划方法是decision-time planning方法,统称为Heuristic Search(启发式搜索)。
在启发式搜索中,对每个遇到的状态都会生成一颗延续的搜索树,近似的value function会被在叶节点应用,然后反向传播到根节点。反向传播在当前状态停止。一旦这些节点的值被计算出来,就会选择其中最好的一个作为当前的行动,然后所有的值就会被丢弃。
在传统的启发式搜索中,计算出的backed-up values并不会被通过修改近似value function来保存。实际上,价值函数一般都是由人设计的,绝不会因为搜索而改变。然而,一个自然而然的想法就是考虑改进value function,使用启发式搜索计算出的backed-up value或者其他方法。从某种意义上说,我们一直都采取这种方法。
Greedy,ε-greedy和UCB动作选择方法与启发式搜索没什么不同,尽管是在一个更小的范围内。举个例子,为了计算greedy策略的state-value function,我们必须向前概览每个可能的动作,到达每个可能的下一个状态,考虑他们的reward和评估值,然后选择一个最好的动作。这就如同传统的启发式搜索,计算所有可能动作的backed-up values,但是不去保存他们。因此,启发式搜索可以被看作greedy策略在单步范围外的一种扩展。
搜索的更深是为了获得更好的动作选择策略。假设我们有一个完美的model和一个不完美的action-value function,如果一路搜索到底,那么不完美的value function的影响就会被消除。通过这种方式的搜索必须是optimal的。若搜索步骤k足够多,导致 γ^k^ 足够小,那么动作就会近似达到optimal。从另一个角度讲,搜索的越深所需的算力资源也越多,响应就越慢。
**一个优秀的例子是是Tesauro提出的大师级双陆棋算法,TD-Gammon。**该算法使用TD learning,通过与自己对弈来学习value function,其使用启发式搜索来选择动作。Tesauro发现启发式搜索的越深,TD-Gammon就会选择越好的动作,但是每走一步花的时间也越多。
在更深入的搜索中观察到的性能改善并不是由于使用多步骤更新本身。相反,它是由于更新的重点集中在当前状态的下游的状态和行动上。通过投入大量与候选行动具体相关的计算,决策时规划可以产生比依靠无重点的更新所产生的更好的决策。
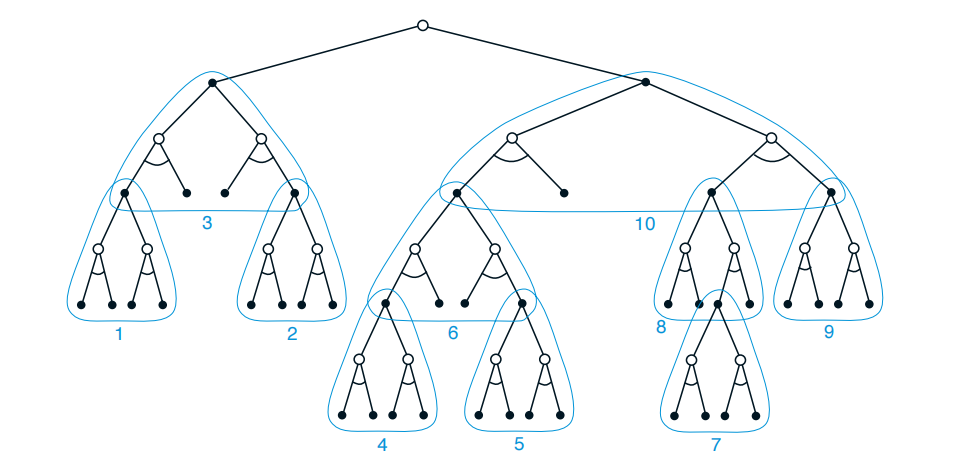
如上图所示,白圆点表示状态,黑圆点表示动作。以当前状态为根节点,遍历每一层所有的可能性,然后计算每个非叶节点的Q(s,a)。具体计算方法如下,将树按深度优先遍历,每个非叶节点使用公式:
$$
Q(s,a) = \sum_{s’,r}{p(s’,r|s,a)(r + γmax_{a’}Q(s’,a’))}
$$
故按照图中的数字顺序(1->2->3->4->5……)依次计算**q*的期望更新**,得到当前状态(根节点)每个可能动作a’的对应的Q(s,a’),选择一个最好的即可。当然,在使用算法的过程中搜索层数K是可以控制的,故叶节点并不一定是终结状态ST。
Rollout Algorithms(Rollout 算法)
Rollout算法是基于蒙特卡洛控制的决策时规划算法,其应用于从当前状态开始的一些模拟轨迹。对给定的policy进行动作评估的方式是将许多从各个可能的动作开始的模拟轨迹的返回值平均化。当action-value评估被认为足够准确了,被给分最高的动作就会被执行,之后,该过程(Rollout)将从产生的下一个状态重新进行。
不同于蒙特卡洛控制算法,Rollout算法的目标不是评估一个最优的q*或qπ,而是根据一个给定的一般叫rollout policy的策略,来为每个当前状态生成蒙特卡洛评估。作为一个决策时规划算法,Rollout算法在当即使用这些action-value评估值之后就丢弃他们。这使得Rollout算法的实现相对较为简单,因为不都需要对每个<s , a>键值对都采样,并且不需要对状态空间或状态-动作空间拟合一个近似函数。
Rollout算法什么时候停止?策略改进定理告诉我们给定两个几乎相同的策略π和π’,他们不同是对同一个状态S有:
$$
π’(s) = a ≠ π(s)
$$
如果:
$$
q_{π}(s,a)\geq v_{π}(s)
$$
那么策略π’就优于或等于策略π。
在Rollout算法中,对状态s的每个可能的动作a’都计算其若干条模拟轨迹的平均返回值,得到$q_π(s,a’)$。接着选取评估值最大的那个action,随后的状态都继续遵循策略π,这就是一个很好的在π上的策略改进。
换句话说,Rollout算法的目标就是在rollout policy上不断做改进,而不是去寻找一个最优策略。经验表明Rollout算法的效果非常惊艳。例如Tesauro和Galperin(1997)就表明rollout算法对于双陆西洋棋的提升效果非常显著。在一些应用中,即使rollout policy是完全随机的Rollout算法也可以有好的表现。但是policy的改进依靠rollout policy的性能和MC值评估得出的action排名。直觉表明,rollout policy越好、评估值越准确,Rollout算法给出的策略就越好。
这其中包含了重要的权衡,因为一般来说越好的rollout policy意味着需要越多的时间来模拟足够的轨迹,以得到好的value评估效果。作为一个决策时评估方法,Rollout算法一般都会有严格的时间限制,其计算所需时间由待评估动作的数量、模拟轨迹中的步长、rollout policy做决策的时间和模拟轨迹的数量共同决定。
虽然存在一些方法可以减轻这一难题,但在任何Rollout算法的应用中平衡这些因素都是很重要的。因为MC评估是相互独立的,故并行做这些评估是可能的。另外一种方法是可以缩减模拟轨迹的长度。
简单来说,不同于启发式搜索往下遍历所有的可行性然后进行q*期望更新,Rollout对每个可能的action进行若干条MC采样,以这些采样的平均值来评估这个aciton的好坏。
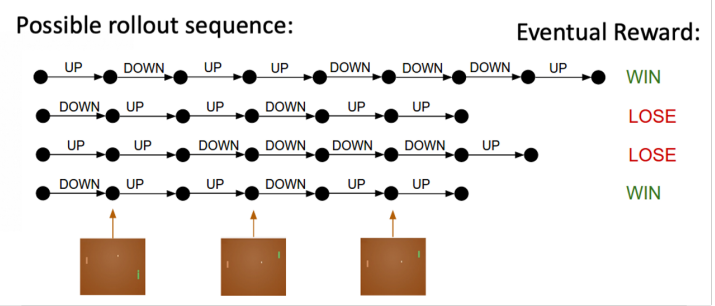
Rollout 的意思是从当前帧去生成很多局的游戏。
Monte Carlo Tree Search(MCTS 蒙特卡洛树搜索)
Monte Carlo Tree Search (MCTS),蒙特卡洛树搜索,是一个近年来非常成功的决策时规划算法。MCTS是一个rollout改进算法,其在Rollout的基础上增加了累计从MC模拟轨迹中获得value的方法,以便于模拟到有更高reward的轨迹。
MCTS是近年来AI围棋从一个入门者(2005)发展到一个宗师级棋手(2015)的重要原因,2016年AlphaGo程序战胜了世界围棋冠军选手。MCTS被证明在许多竞争领域有显著效果,包括一般的游戏,但不局限于此。若环境model足够简单,可以进快速多步模拟,它对单智能体序列决策问题就非常有效。
MCTS的核心思想是从以往的模拟中,扩展初始部分已经获得高回报的轨迹,让算力聚焦于更可能获得高回报的模拟路线。
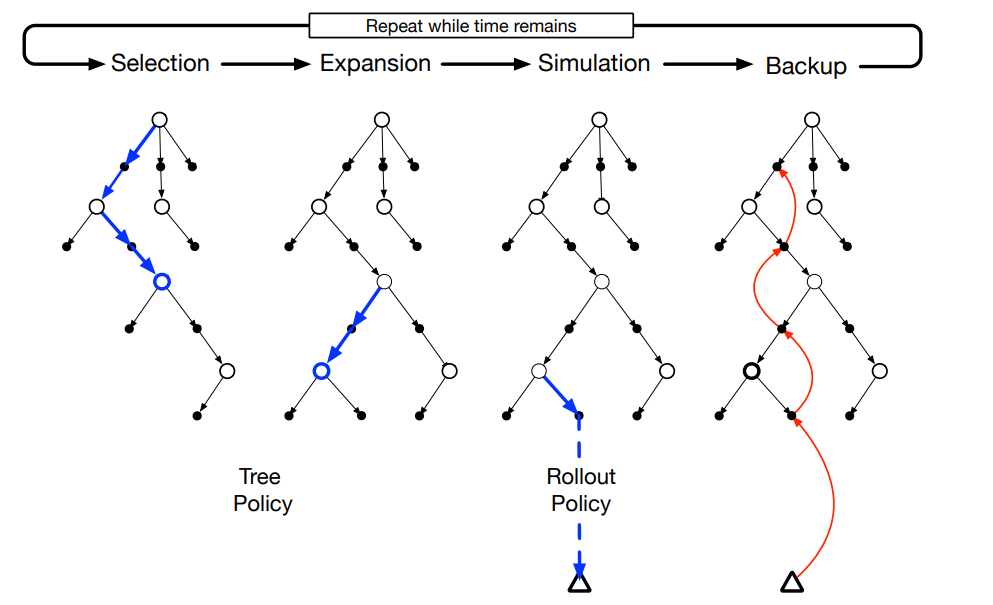
在任何MC评估方法中,<s,a>键值对的评估值就是多对模拟轨迹的平均返回值,在这里,只保留最有可能在几步内达到的<s,a>对的MC估计值(算出来的q(s,a))。我们称这些节点加上根节点组成一个tree,使用一个tree policy遍历这个tree来选择一个用来扩展的叶子结点,构建一个tree帮助我们能选择一个更好的节点用来rollout而不是对每个节点都进行模拟。
总的来说,MCTS总共分为四步:Selection,Expansion,Simulation和Backup。
- Selection就是用tree policy(例如ε-greedy)来选择一个叶节点,用于后续扩展;
- Expansion就是使用选择好的节点,用一些未使用过的actions来扩展一个或几个孩子节点;
- Simulation就是从选择的节点/扩展的节点上用rollout policy进行模拟,同rollout算法;
- Backup就是通过模拟得出的值来反向更新对应的action.
在一个时间步骤内,MCTS反复做这四步,直到时间不够了或者其他计算资源不够了。然后,通过某种方法来为当前状态选择一个动作。例如,选择value最大的动作,或是,选择visit次数最多的动作来避免选到异常值。当到达下一个状态后,新一轮的MCTS又开始了。有时新一轮的MCTS从一个孤立的节点开始,但大多数情况下会从上一次MCTS中还留存的、有些后代的tree开始。
MCTS最初被提出用于为一些双人竞技游戏选择动作,例如围棋。每个模拟过程都是一个完整的游戏过程,双方选手通过tree和rollout policy来选择动作。
相关概念解释:
1. Distribution model and Sample model
参考《Reinforcement Learning》Page159,Chapter 8,原文解释的很清楚:
“By a model of the environment we mean anything that an agent can use to predict how the environment will respond to its actions. Given a state and an action, a model produces a prediction of the resultant next state and next reward. ”
“我们所指的环境的model是一个agent可以用其预测环境会如何对其action作出反应的东西。给出一个state和一个action,model给出下一个state和返回的reward。”
“If the model is stochastic, then there are several possible next states and next rewards, each with some probability of occurring. ”
“如果model是随机的,那么下一个state与reward就有许多可能的情况,每个情况都有一定概率发生。”
“Some models produce a description of all possibilities and their probabilities; these we call distribution models. Other models produce just one of the possibilities, sampled according to the probabilities; these we call sample models.”
“一些models提供了一个对所有事件发生的可能性以及其概率的描述,这些models我们称其为distribution models(分布模型);另外一些models仅提供这些可能发生的事件的其中一种,这些models我们称其为sample models(样本模型)”
“ For example, consider modeling the sum of a dozen dice. A distribution model would produce all possible sums and their probabilities of occurring, whereas a sample model would produce an individual sum drawn according to this probability distribution.”
“例如,考虑对一打骰子(dozen dice)的和进行建模,一个 distribution model 会产生所有可能的和,以及它们发生的概率,而一个 sample model 会根据这个概率分布产生一个单独的和。”
例如,MDP中的$p(s^{‘},r|s,a)$就是一个典型的分布模型。在很多应用中,获取 sample models 比获取 distribution models 容易得多。dozen dice 就是这样一个例子。很容易写一个电脑程序仿真掷骰、返回和的过程,但是计算所有可能的和以及对应的概率很难,且容易出错。