【论文阅读】Function-level obfuscation detection method based on Graph Convolutional Networks
时间:2021
作者:Shuai Jiang , Yao Hong, Cai Fu(华科)
期刊:Journal of Information Security and Applications(中科院三区)
1.ABSTRACT
在恶意样本检测中代码混淆检测技术是一个重要的辅助手段,对于安全从业者来说,其可以在人工逆向分析前来实施自动化混淆检测,这有助于逆向工程师更具体地进行逆向分析。
目前存在的混淆检测方法主要作用于Android应用,并基于传统的机器学习方法。其检测颗粒度很差,总体效果不佳。为了解决这些问题,在本篇文章,我们提出了一个应用于X86汇编和Android应用的、function level的、基于GCN的混淆检测方法。
1. 首先,我们的方法是function-level的。我们提取每个函数的CFG作为其特征(包括邻接矩阵和基本代码块的特征矩阵);
2. 我们构建一个GCN-LSTM神经网络作为混淆检测模型;
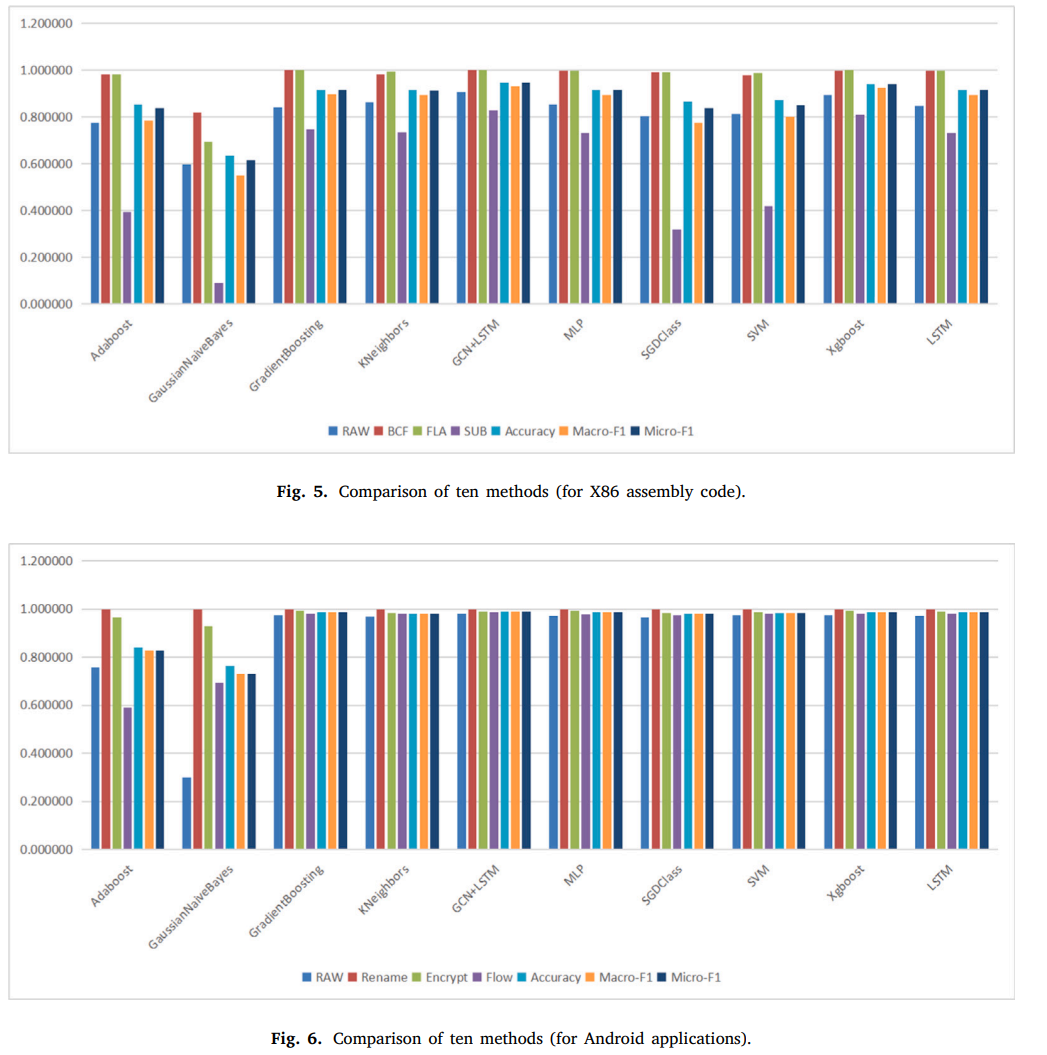
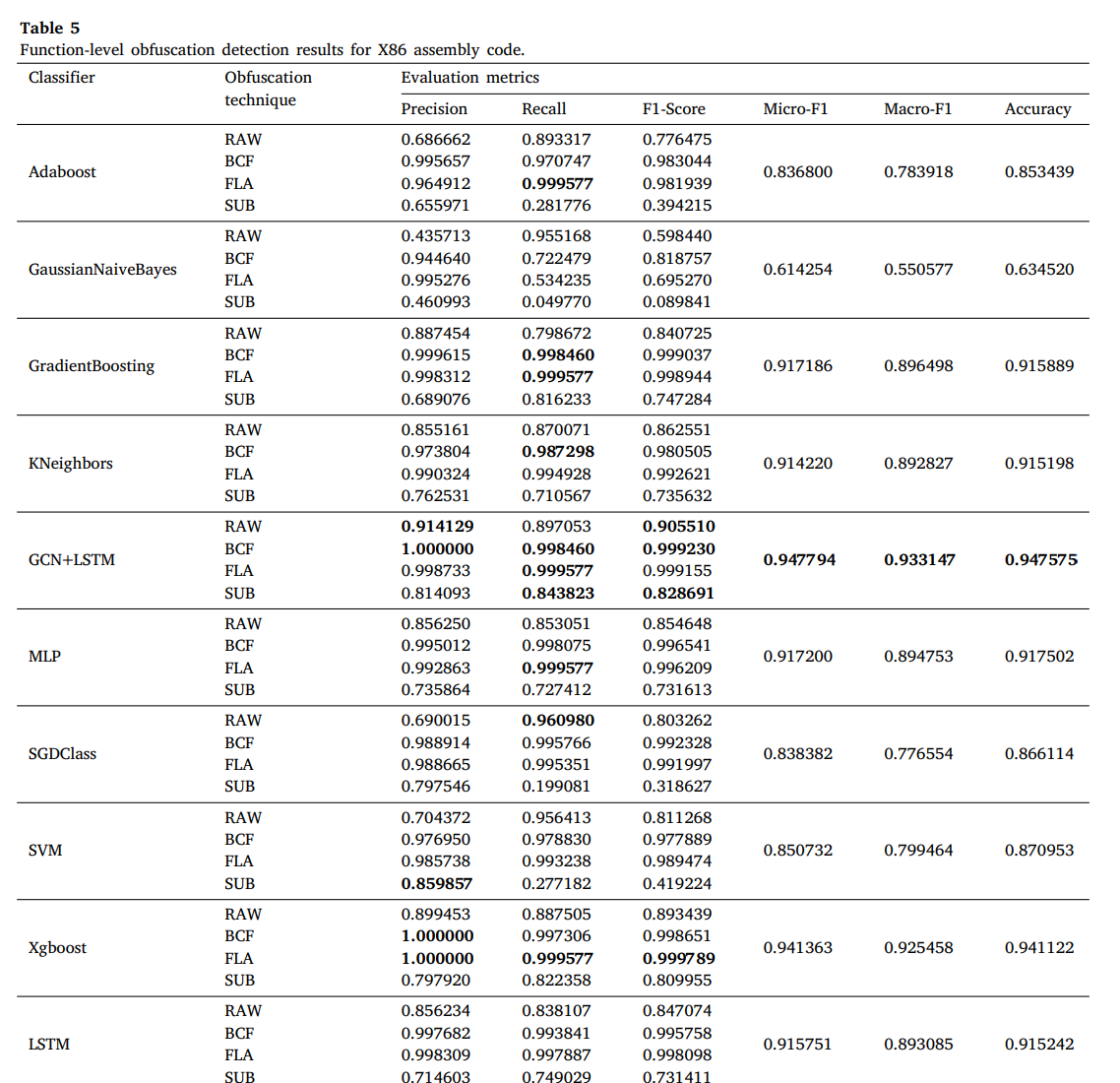
3. 最后,对于function-level的检测我们的方法准确率是94.7575%(X86汇编)和98.9457%(安卓应用),比baseline方法好。实验证明我们的方法不论是在function-levle还是APK-level上的检测准确率都好于baseline。
2. INTRODUCTION
2.1 Obfuscation–代码混淆
代码保护技术,用于增加逆向难度,防止代码篡改,最开始用于版权保护,后被用于恶意代码的躲避检测。
由于动态检测恶意代码的高昂成本,主流的恶意样本检测技术仍在提取代码的静态特征。然而由于混淆技术的发展,恶意样本的编写者经常在保留其恶意功能的同时通过使用混淆技术来修改其静态特征。经过混淆的恶意代码可以规避相关工具的检测。
最近混淆检测技术开始出现,在此领域有一些工作:
1. [2018]Alessandro等人:使用静态分析和机器学习分类算法来分析Android应用是否被混淆的技术( http://dx.doi.org/10.1145/3230833.3232823);
2. [2020]Crincoli等人:利用weak bisimulation来检测代码是否被code reordering(http://dx.doi.org/10.1007/978-3-030-44041-1_116);
3. [2020]Caijun Sun等人:一个Android打包检测框架DroidPDF( http://dx.doi.org/10.1109/ACCESS.2020.3010588);
4. [2019]Omid等人:AndrODet,一个检测三种Android混淆技术的检测机制(重命名、字符串加密和控制流混淆)( http://dx.doi.org/10.1016/j.future.2018.07.066);
5. [2019]Alireza等人:Android字符串混淆检测技术( http://dx.doi.org/10.1145/3338501.3357373);
2.2 目前方法的缺点:
1. 检测颗粒度不够,检测对象往往是一个APK包,缺乏可行性;
2. 检测效果不佳,从样本中提取的特征相对简单,只有统计学特征和opcode语句被提取。大多数使用简单的机器学习方法,表现一般;
3. 缺乏可用性和适应性,传统方法往往会为不同的混淆方法提取不同的特征,或者为每个混淆方法训练一个二分类器,枯燥且不便。同时若需要添加新数据,模型经常需要重头训练。
2.3 我们的方法:
- 从开源平台获取一些未经混淆的代码(X86汇编和Android),通过混淆器生成混淆后程序;
- 逆向这些程序,用邻接矩阵和基本代码块特征矩阵的形式提取每个函数的CFG;
- 根据我们提取到的特征,构建GCN-LSTM。这个模型同时服务于X86汇编和Android,但他们分别训练和测试;
3. METHOD OVERVIEW
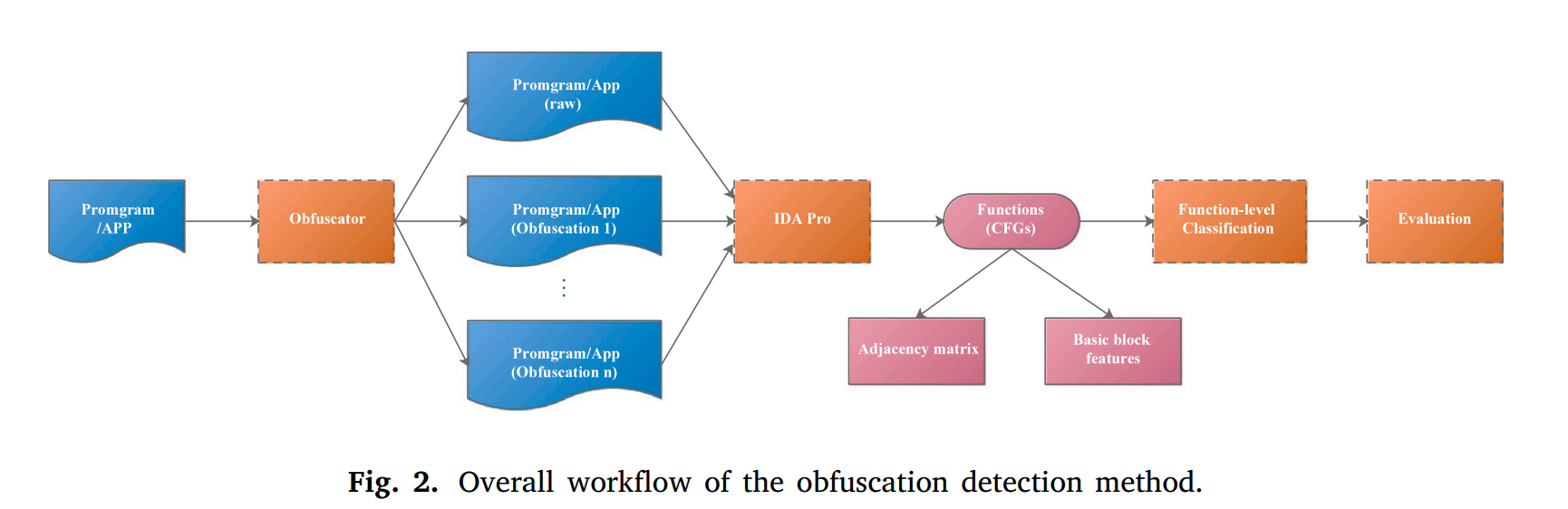
1. X86的混淆器:OLLVM;Android的混淆器:Obfuscapk;
2. 逆向工具:IDA PRO;由于X86与Android指令集与混淆技术不同,二者被分别提取CFG;
3. 多分类问题,检测出混淆技术种类,故使用传统多分类评估方法来评估检测效果。
4. OBFUSCATION DECTION METHOD
4.1 OLLVM
OLLVM包括以下三种混淆技术:
- Instructions Substitution (SUB),指令替换。将简单指令替换为同语义的复杂指令,特别是二进制加减乘除。这项技术会增加算术指令但很少影响CFG;
- Bogus Control Flow (BCF),虚假控制流。在CFG中添加大量无关的随机代码块和分支,并分割、融合、重排原始代码块,在其中插入随机选择的无用指令。这项技术破坏了CFG和代码块的完整性,增加控制流复杂性;
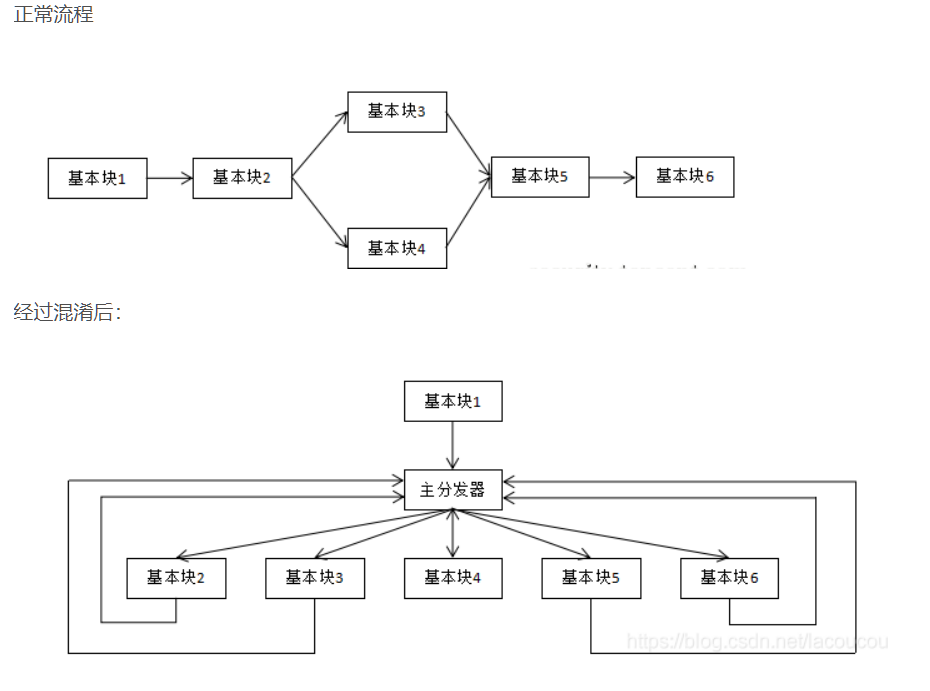
- Control Flow Flattening(FLA),控制流平坦化。简单来讲就是将代码块之间的关系打断,由一个分发器来控制代码块的跳转:
4.2 Obfuscapk
Obfuscapk包括以下三种混淆技术:
- Identifier Renaming,标识符重命名;
- String Encryption,字符串加密。字符串常量可以揭示很多代码敏感信息;
- Control Flow Obfuscation,控制流混淆。通过扩展或平坦化CFG来混淆,同样还有注入垃圾代码,扩展循环,添加无关操作等;
4.3 Feature extraction
提取的特征包括代码的结构化CFG信息和基本代码块特征:
- 对于邻接矩阵:
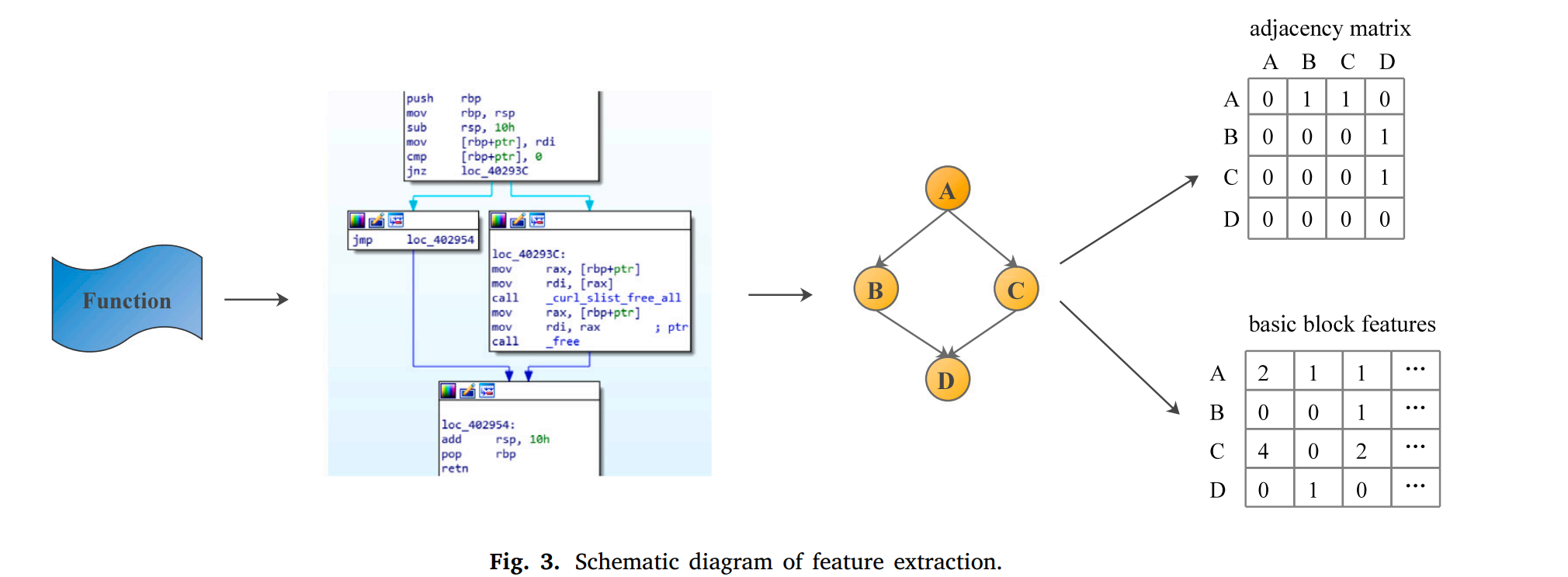 如图,邻接矩阵代码了不同代码块之间的转移关系。
如图,邻接矩阵代码了不同代码块之间的转移关系。
对于基本代码块特征:
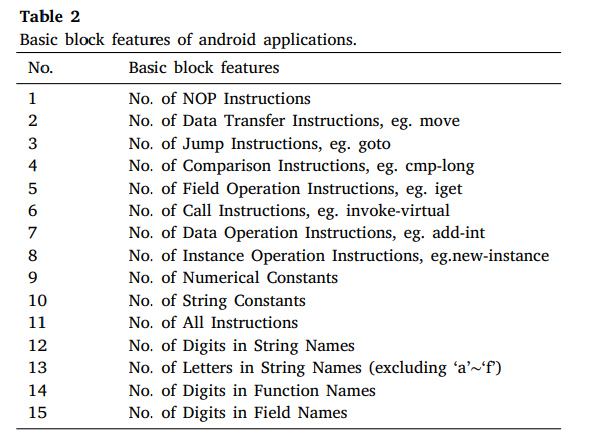
将X86汇编代码分为27类,对于一个代码块的特征向量就是27维。

将Dalvik指令分为15类,对于一个代码块的特征向量就是15维。
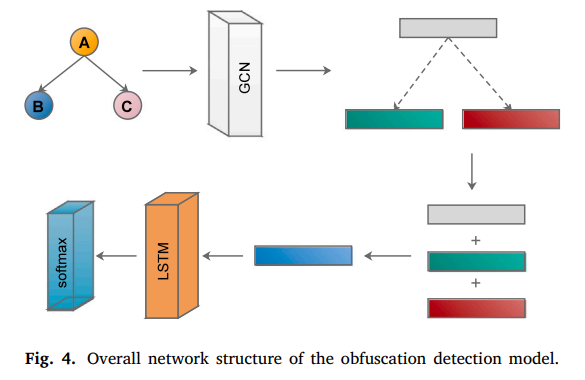
4.4 Obfuscation detection model
在得到CFG邻接矩阵和基本代码块特征矩阵后,构建GCN-LSTM。
5.EXPERIMENTAL EVALUATION
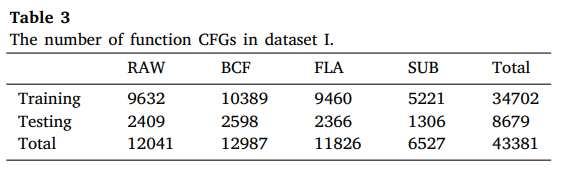
5.1 Datasets
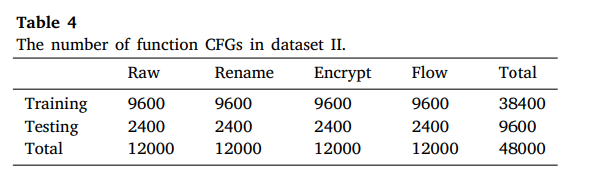
5.2 Baseline methods
function-level的baseline方法如下:
AdaBoost, GaussianNaiveBayes, GradientBoosting, KNeighbors, MLP, SGDClass, SVM, Xgboost and LSTM
5.3 Evaluation metrics