
【论文阅读】IFAttn-Binary code similarity analysis based on interpretable features with attention
时间:2021
作者:Shuai Jianga , Cai Fua , Yekui Qian(华科)
期刊:Computers & Security(中科院三区)
1.ABSTRACT
二进制代码相似性分析(Binary code similarity analysis ,BCSA)是一项有意义的软件安全分析技术,包括漏洞挖掘、代码克隆检测和恶意代码检测。
尽管近年来出现了很多基于神经网络的很多BCSA研究成果,仍有一些问题未被解决。首先,大多数方法更聚焦于function pair similarity detection task (FPSDT),而忽略了function search task (FST),后者对漏洞挖掘更为重要。还有,现有方法为了提高FPSDT的准确率使用了一些无法解释的神经网络;最后,大多数现有方法无法抵抗BCSA中的交叉优化和交叉混淆。
为了解决这些问题,我们首次提出了一个结合了可解释特征工程和可学习注意力机制的适应性BCSA架构。我们设计了一个具有适应性的、富有可解释性特征的模型。测试结果表明对于FPSDT和FST的效果比state-of-the-art效果更好。
另外,我们还发现注意机制在功能语义表达方面具有突出的优势。
评估表明我们的方法可以显著提升FST在cross-architecture, cross-optimization, cross-obfuscation and cross-compiler binaries上的表现。
为了提高开发效率,开发者通常会使用开源代码来开发新软件。如果一个开发者使用了一个存在漏洞的函数,则这个漏洞就会被继承且很难被发现。代码克隆这种现象对软件的安全可靠性造成了很大影响。
不幸的是,直接对二进制代码使用同源性分析并不够直接明了,二进制代码缺乏语义抽象,很难从函数中提取语义信息来做同源性分析。另外,分割函数的边界也是个问题。
所以在代码克隆、恶意样本追踪、库函数发掘和漏洞发掘领域对二进制代码做同源性分析一直是个重要的方向。
根据已有方法的颗粒度分类,现存成果可以分为:
- 基于基本静态特征的方法;
- 基于代码图结构(例如CFG)的方法;
- 基于代码张量的方法;
- 基于深度学习生成函数嵌入的方法;
现有方法存在的问题:
大多数方法更聚焦于function pair similarity detection task (FPSDT),而忽略了function search task (FST),后者对漏洞挖掘更为重要;
FPSDT指对比两个函数的相似度,FST指在函数库中寻找与某个函数最相似的函数。
现有方法为了提高FPSDT的准确率使用了一些无法解释的神经网络,设计一个复杂的分析过程;
因为编译器的优化和混淆会显著修改代码结构,大多数方法在这些条件下表现不佳。
我们的方法解决的:
如何利用可解释的基本特征来生成二进制代码的语义特征;
用注意力机制来聚焦于在不同编译环境下仍起作用的特征,学习基本特征之间的联系。
如何设计一个适应不同编译选项的通用BCSA模型框架。
我们重新设计了Transformer的编码部分,使用孪生神经网络来判断两个函数的相似度,在attention layer使用KFM来处理不动的编译选项。
注意力机制的优点:
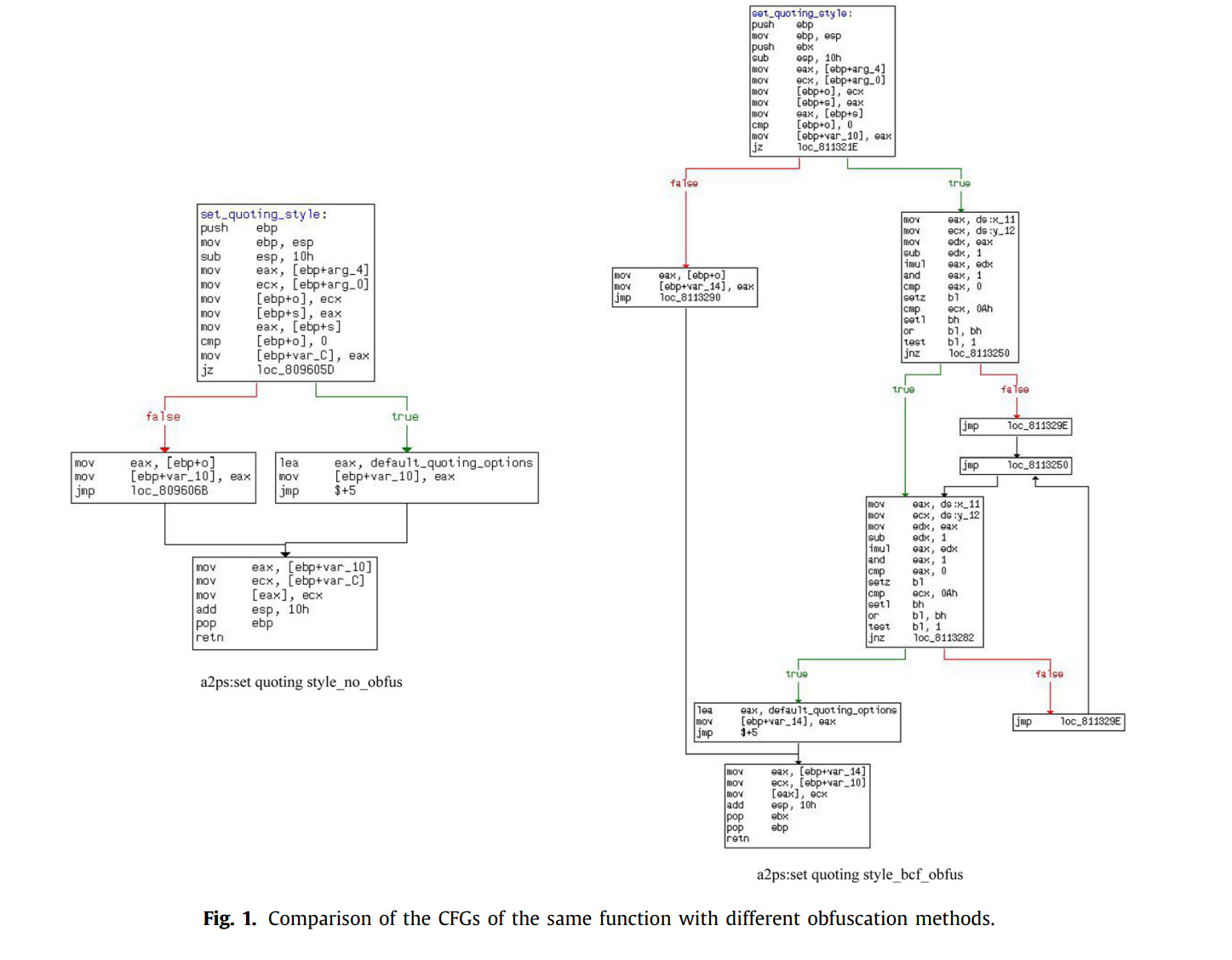
下图是同一个函数在同一个编译选项(X86_32_00)下通过混淆技术BCF前后的CFG图:
下图是TIKNIB和IFAttn两个模型在对同一个函数混淆前后抓取的特征向量值:
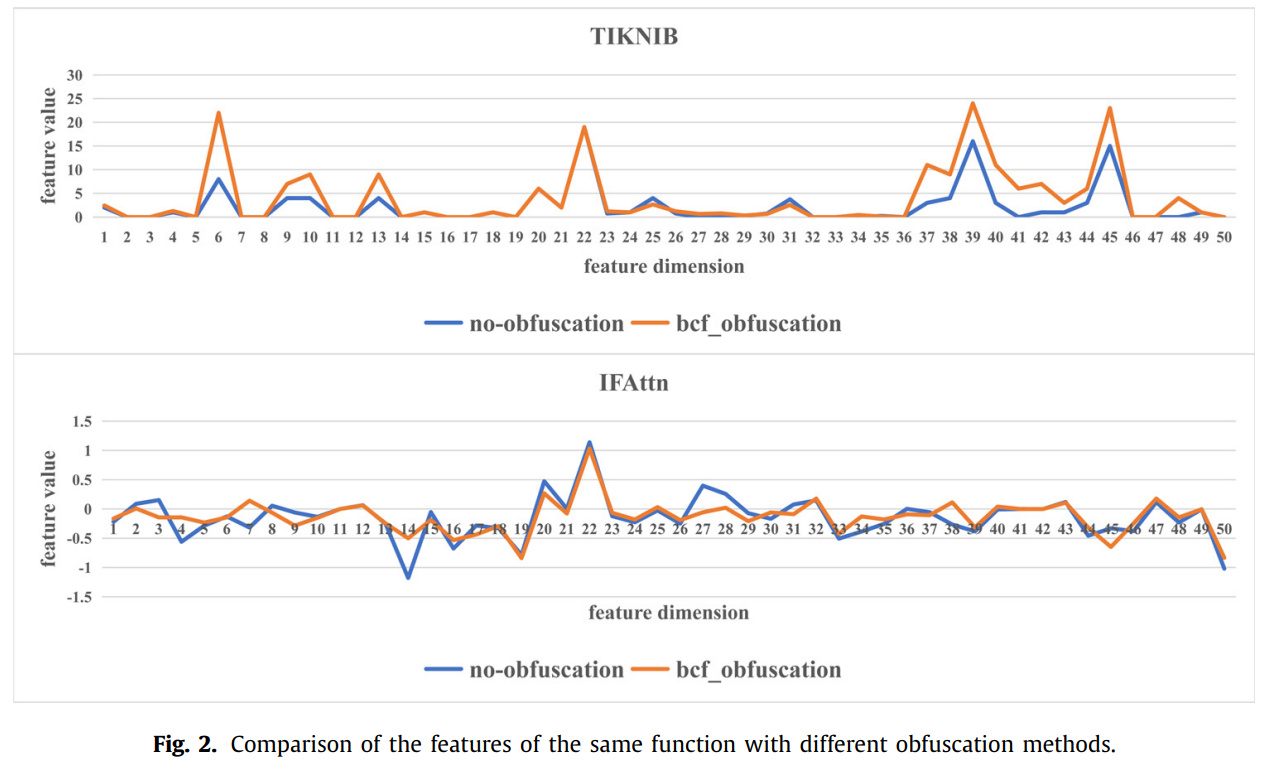
可以看到,在混淆前后basic features有明显不同,而semantic features则总体上更为稳定。
下图表明了TIKNIB和IFAttn在对不同函数,一个混淆一个不混淆的前提下提取到的特征向量值:
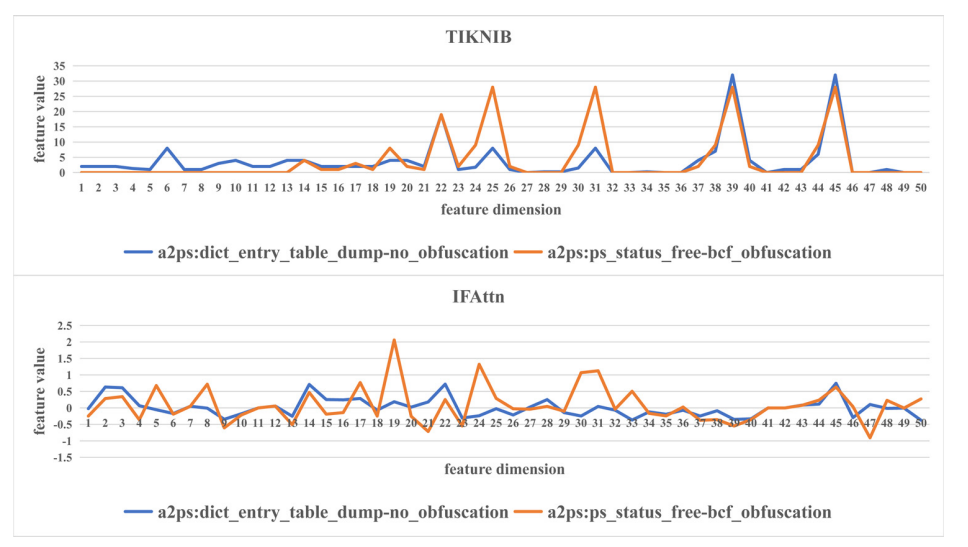
可以看到,与之前相反,在混淆前后basic features较为稳定,而semantic features变化更大。
semantic features更能体现函数本身语义,而不受混淆技术的影响。
一些定义:
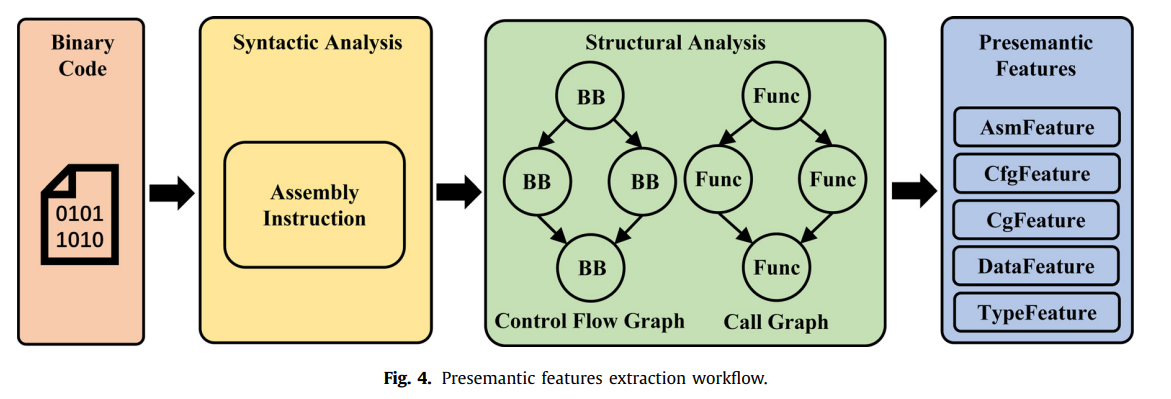
- **Presemantic features:**直接或间接从代码语法和结构分析出的特征;
- **Semantic features:**本文通过注意机制分析了base feature形成的内在关联,并将base feature融合生成语义嵌入
- KFM scaled dot-product attention:
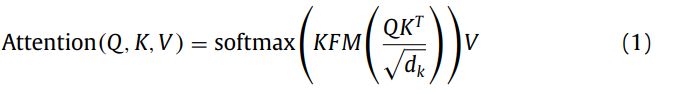
- **Multi-head attention:**Transformer的一种注意力机制。
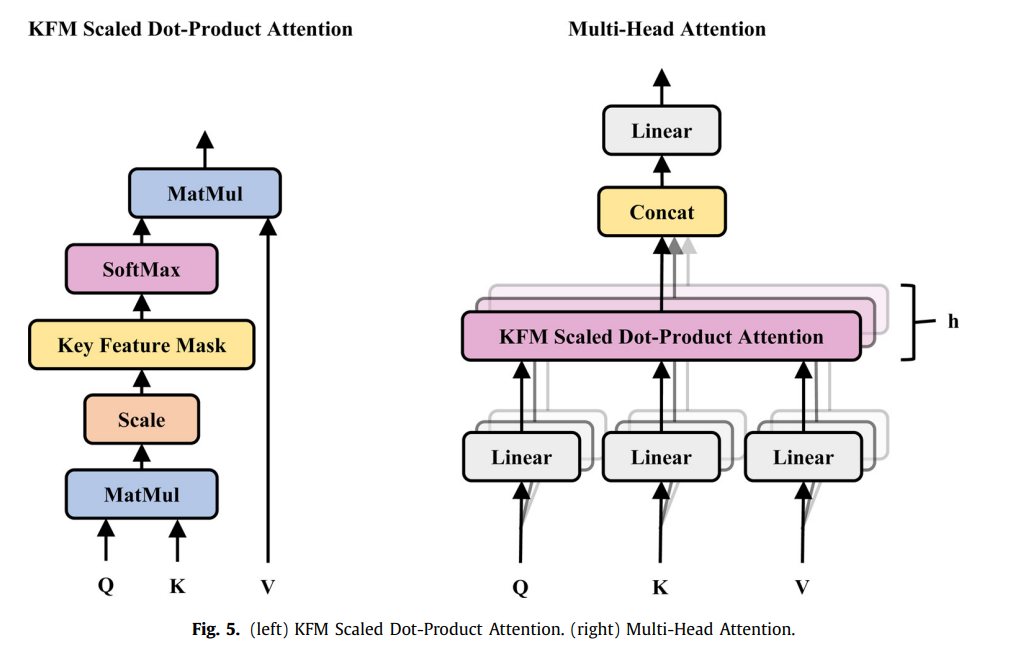
**系统结构:**IFAttn (Interpretable Features with Attention)
测试结果:
数据集:

测试结果:
