
【论文阅读】How Machine Learning Is Solving the Binary Function Similarity Problem
**时间:**2022.8
**作者:**Andrea Marcelli, Mariano Graziano , Xabier Ugarte-Pedrero, Yanick Fratantonio , Mohamad Mansouri and Davide Balzarotti(思科,欧洲电信学院)
**会议:**usenix 2022
ABSTRACT
人们会期望到现在为止,对于二进制相似性问题的研究,其有可能回答一些研究问题,这些问题超出了论文中提出的非常具体的技术,可以推广到整个研究领域。不幸的是,这个目标受到许多挑战,从可重复性问题到研究结果的不透明性,阻碍了研究有意义和有效地进展。
在本文,我们开始着手于对state-of-the-art做这个领域的第一个测试性研究。
- 首先,我们系统化了现存的研究成果;
- 我们选定了一些相关方法,这些方法代表了三个不同研究社区最近提出的各种解决方案;
- 针对现有的方案,我们重构了方法并构建了新的数据集,以便实现更为公平的对比效果。
INTRODUCTION
**Binary function similarity:**将一对函数的二进制表示作为输入,它们之间的相似性值作为输出。
Binary function similarity技术面临的挑战:
实际情况下,软件会被不同编译器、链接工具以及优化器编译;
特殊情况下,例如IoT,软件会被编译为不同架构的指令;
Binary function similarity的作用:
在系统安全研究领域,许多研究问题需要以Binary function similarity作为核心构件。
**节省逆向时间。**在逆向工程中经常需要处理静态链接的stripped binaries,Binary function similarity可用于将一个未知的函数与先前生成的数据库中的(有标签的)函数进行匹配,对应到先前生成的数据库中,从而节省大量的时间;
(stripped binaries:编译后的二进制文件可以包含调试信息,这些信息对于程序的执行是没有必要的,相反,它对于调试和发现程序中的问题或漏洞是很有用的。剥离的二进制文件(stripped binaries)是一个没有这些调试符号的二进制文件,因此体积较小,而且可能比没有剥离的二进制文件有更好的性能。剥离后的二进制文件很难被反汇编或逆向工程,这也使其难以发现程序中的问题或漏洞。)
**用于高校检索第三方库中的漏洞函数。**给定一个有问题的函数,Binary function similarity可用于在第三方库中快速检索相似函数;
用于软件分析以及恶意软件分类。
提出问题:
- 在使用相同评估标准、相同数据集的前提下,不同的方法如何比较?
- 与简单的模糊哈希算法相比,原创的机器学习算法的主要贡献在哪?
- 不同特征集的作用是什么?
- 不同的方法在不同的任务中是否效果更好?
- 相较于同一架构指令下,不同架构指令编译的二进制的比较是否更困难?
- 是否有任何具体的研究方向看起来更有希望成为设计新技术的未来方向?
很遗憾,我们发现目前的研究并不能回答上述问题。
现有研究存在的不足:
实验方法、实验结果不透明,难复现。实验所需的工具、超参数以及数据集通常都是不公开的,一些工作的横向比较太少甚至跟自己以前发的文章比;
**现有工作的评估方法往往也是模糊不清的。**不同的论文中,任务目标、环境设置、概念、颗粒度、数据集的大小和特性以及评估方法往往都不同,因此,即使是论文中最基础的图像也基本不能直接比较。所以,当新的工作声称比旧工作表现更好时,这个优越性是否仅仅是针对某个特殊的领域不得而知。更糟糕的是,一些工作函数对的选择方法以及训练集的构成并没有详细说明,使得复现变得更加困难。一个方法结果更优秀的原因是因为其原创性还是其他因素不得而知;
**领域整体较为混乱。**每个新的解决方案都采用了更复杂的技术,或多种技术的新组合。新方法的成功很难确定是由较简单的方法的实际局限性导致的,还是其创新性。现有几十种方法存在,但是并不能确定哪些方法在哪些环境设置下是有效的,而哪些不行。
“每个人都声称他们的方法最好。”
本文贡献:
实现了在本领域第一个系统化的评估。在相同的工具框架下复现了10个有代表性的方法(及其变种方法),并使用新定义的同一数据集测试。
一些结论:
- 简单的方法(例如模糊哈希)在简单的环境下表现很好,但难以应对复杂的环境;
- GNN几乎在所有任务里都取得了最好的成绩;
- 许多最近发表的论文在同一数据集上测试时,都有非常相似的准确性,尽管他们之中的一些声称自己有了提高。
Measuring Function Similarity(领域基础知识)
1. 函数相似度评估方法
1.1 直接评估(Direct Comparsion):
用机器学习/深度学习模型做相似性函数,通过对模型的训练来使其输入两个函数,输出两个函数的相似性。
1.1 间接评估(Indirect Comparsion):
间接评估将输入函数的特征压缩到低维度表示,这些表示可以使用简单的距离测量方法评估相似度,例如欧氏距离或余弦距离。
Fuzzy hashes:一个很典型的低维度特征表示方法就是哈希模糊。特殊的fuzzy hashes,如ssdeep,用于判断两个文件是否近似的hash。如果一个文件比另一个文件多一个空格,普通的hash是会完全不同,而模糊hash 可能会很相似或者完全一样。
**Code embedding:**代码嵌入,应用NLP的方法,将汇编看做文本,对每个代码块或者指令做embedding。
Graph embedding: 图嵌入,使用代码图结构,通过传统方法或者GNN来生成embedding。
2. 函数表示方法
- 直接使用raw bytes;
- 使用通过raw bytes反编译得到的汇编代码;
- Normalized assembly,将汇编代码中的常数等替换,减轻操作数与操作之间的联系;
- Intermediate representations,中间表示;
- 图结构,例如CFG,DFG等;
- 动态分析,通过运行中的函数来比较;
- Symbolic execution,通过符号执行分析;
筛选现有方法
尽管现有数百篇的论文,但其中的很多方法都是对某个技术做微调,故该领域的原创方法并不是很多。
1. 筛选标准
- Scalability and real-world applicability(可扩展性和现实世界的适用性):不关注天生速度较慢的方法,只关注诸如那些基于动态分析、符号执行或高复杂度图相关算法的方法;
- Focus on representative approaches and not on specifific papers:只关注有代表性的方法;
- Cover different communities:在我们的评估中,我们希望包括来自系统安全、编程语言分析和机器学习社区的代表性研究。为了完整性,我们还考虑了行业提出的方法;
- Prioritize latest trends:考虑最新的,尤其是AI方法。
2. 筛选方法
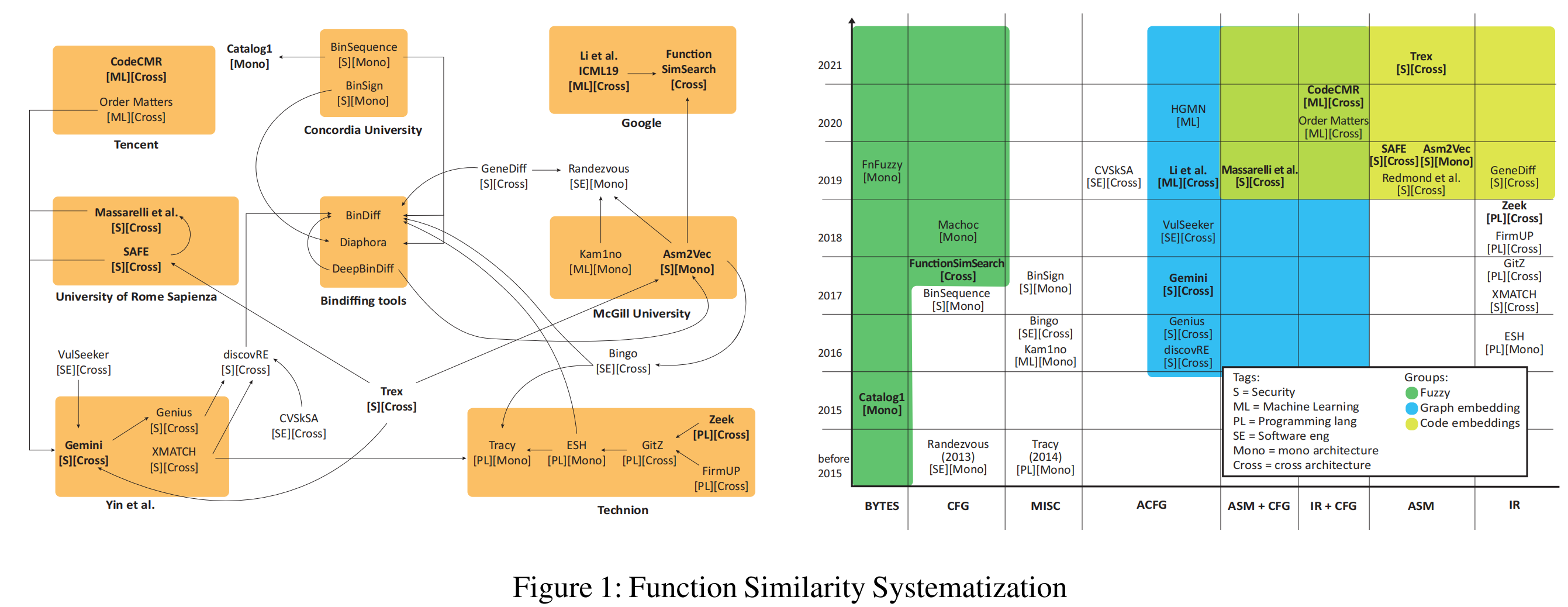
上图选定了30个方法,接着我们会从这30个方法中筛选出10个最有代表性的方法来测试。
该图的左侧对不同研究机构提出的方法进行了分类,由学术界和工业界(腾讯、谷歌),箭头代表了指向的一方拿被指向一方的结果进行了比较;
该图的右侧Y轴代表出版时间,X轴代表函数的输入形式,不同的色块代表不同的相似度计算方式;
中括号[]代表的tag标注了不同的研究群体,例如S代表Security,SE代表Software eng。
从该图中可以得出:
左图中间的二进制比较工具都是为直接比较两个完整二进制文件而设计的(例如,它们使用图结构),并且它们都是针对单指令集结构的。但是一些做了跨指令集和函数比较的paper仍拿这些方法来比较,显然会得出不正确的结论;
从左图可以得出,不同研究机构之间很少跨领域比较;
从右图可以看出,随着时间推移,算法的复杂性以及AI算法的使用比例都在增加。
3. 筛选结果
| 方法类型 | 方法/作者名称 |
|---|---|
| Bytes fuzzy hashing | Catalog1 |
| CFG fuzzy hashing | FunctionSimSearch |
| Attributed CFG and GNN | Gemini |
| Attributed CFG, GNN, and GMN | Li et al. 2019 |
| IR, data flflow analysis and neural network | Zeek |
| Assembly code embedding | Asm2Vec |
| Assembly code embedding and self-attentive encoder | SAFE |
| Assembly code embedding, CFG and GNN | Massarelli et al.2019 |
| CodeCMR | BinaryAI |
| hierarchical transformer and micro-traces | Trex |
测试
1. 复现方法
复现的几个阶段:binary analysis,the feature extraction,the machine-learning implementations.
二进制分析以及特征提取使用的是IDA Pro 7.3以及其Python接口。
有关我们所有实现的其他技术细节,以及有关我们努力联系相应作者的信息以及有关使用预训练模型的注意事项,请参见:
How Machine Learning Is Solving the Binary Function Similarity Problem — Artifacts and Additional Technical Details. https://github.com/Cisco-Talos/binary_function_similarity.
2. 数据集
为了与现实世界的复杂性与变数相匹配,我们创建了两个新的数据集Dataset-1和Dataset-2,其包含了二进制检测领域的问题:
- 多种编译器和版本;
- 多种编译优化器;
- 多种指令集架构和bitness(32位还是64位);
- 不同种类的代码(命令行 or GUI);
Dataset-1用于训练,Dataset-1和Dataset-2用于测试。
3. 实验环境设置
3.1 定义6个检测任务
| 序号 | 任务名称 | 作用 |
|---|---|---|
| 1 | XO | 待测函数对仅优化器不同,编译器,编译器版本、指令集架构和bitness都相同 |
| 2 | XC | 待测函数对优化器,编译器和编译器版本不同,指令集架构和bitness相同 |
| 3 | XC+XB | 待测函数对优化器,编译器和编译器版本以及bitness不同,指令集架构相同 |
| 4 | XA | 待测函数对指令集架构和bitness不同,其他相同 |
| 5 | XA+XO | 待测函数对指令集架构、bitness和优化器不用,其他相同 |
| 6 | XM | 待测函数对所有性质都可能不同 |
3.2 测试方法
每种方法的测试包含两个过程:
- AUC和ROC图;
- MRR和Recall@K。
4. 模糊哈希方法比较结果
比较了两个方法:Catalog1和FunctionSimSearch。
4.1 首先每次只变动一个变量:
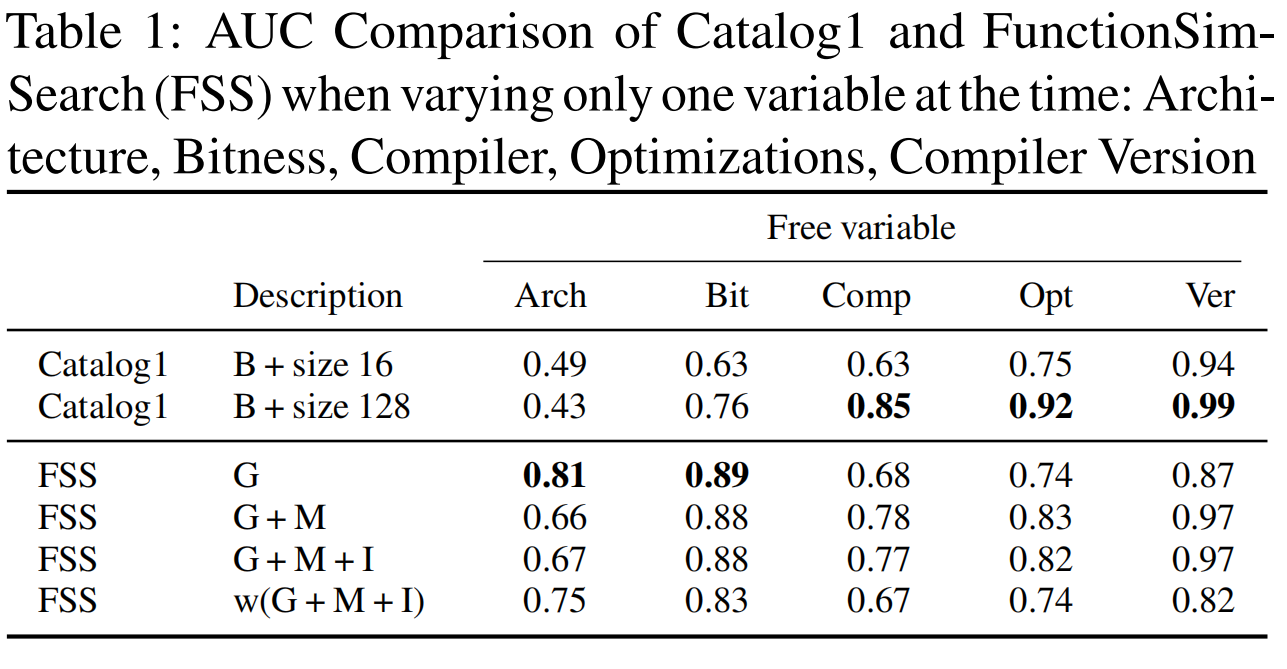
B:Row Bytes;G:graphlets,连通图结构; M: mnemonics;符号 I:immediates 。
由图可知,在单指令集架构的条件下即使简单的row bytes输入也能取得较好效果,在多指令集架构下代码图结构明显更好。
4.2 测试3.1中的6个任务
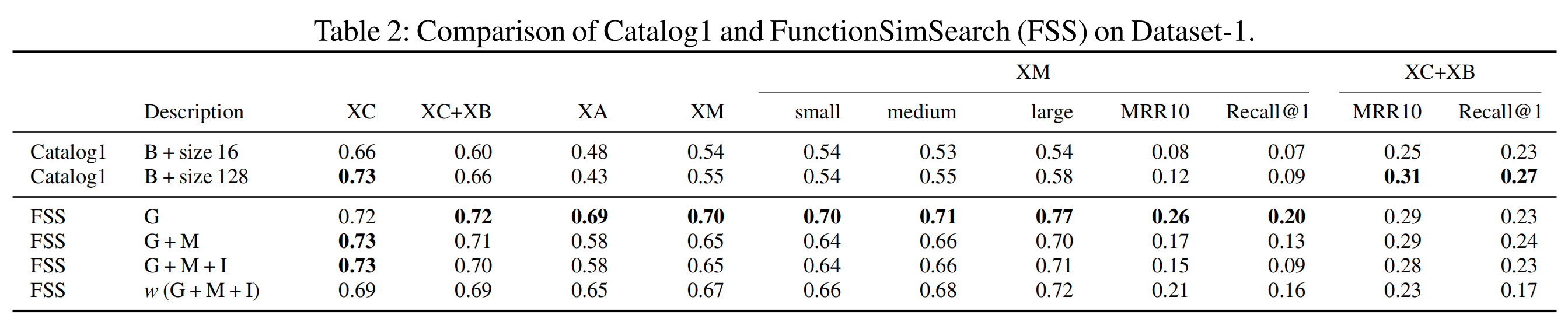
可以看到:
当面对多变量不同的任务时简单的方法开始变得不奏效了,同时FSS在面对大函数时可能由于其图结构的输入也更为有效;
同时,GMI的三个特征引入并没有比最基础的G配置输入更为有效;
Catalog1速度更快,因为FSS的特征提取更耗时。
5. 机器学习方法比较结果
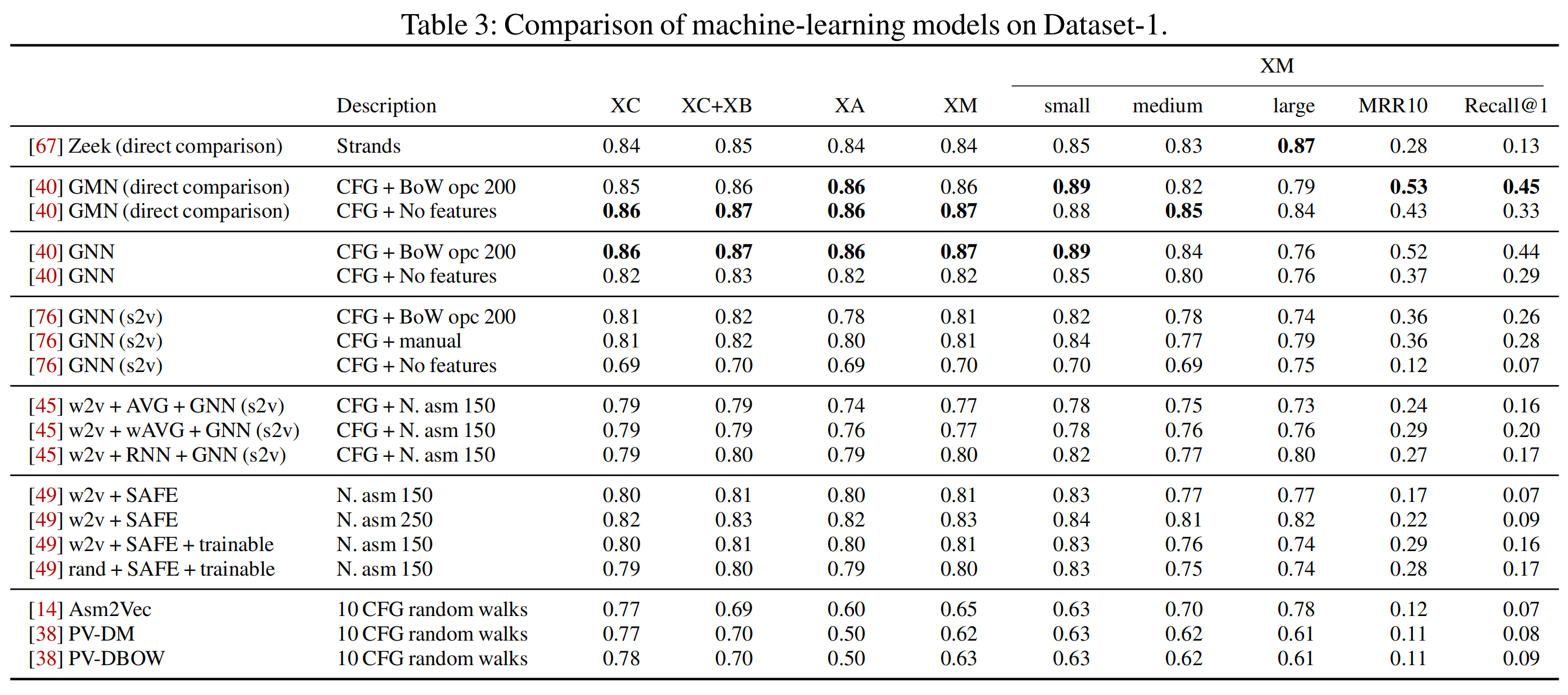
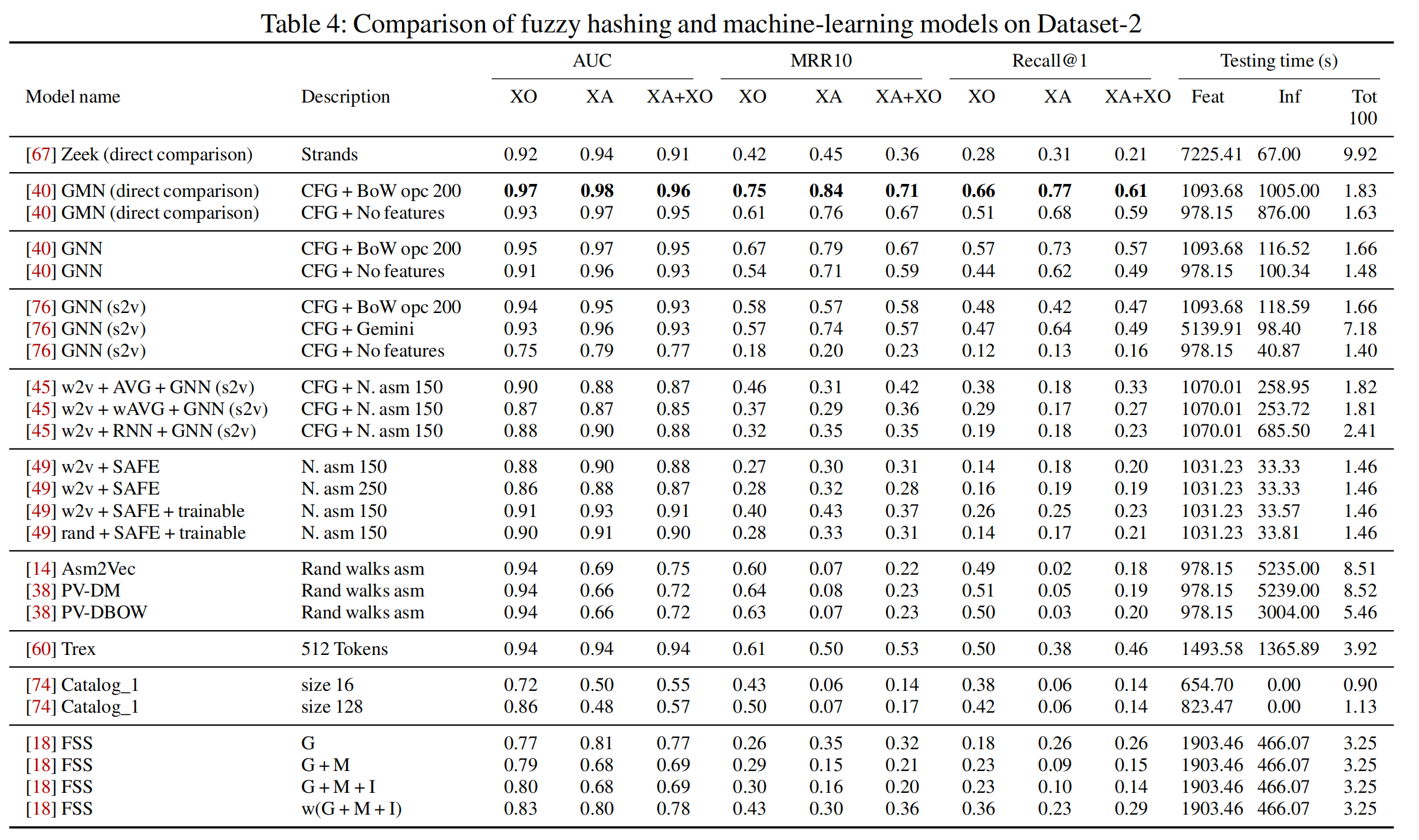

结论:
- GMN几乎在所有的测试下表现都最好,而且运行时间也很短;
- 语言模型相关的方法在同一指令集架构下的表现都很不错,transformer在跨指令集架构的表现也不错;
- 由Li等人提出的GNN变式相较于GNN(s2v)的表现有明显提升;
- GNN(s2v)相关的实验表明更复杂的特征提取不一定更有效,且使用instruction embedding也不一定效果更好;
- 相较于GNN,使用了编码器的SAFE在小函数上的表现更好,但其存在OOV问题;
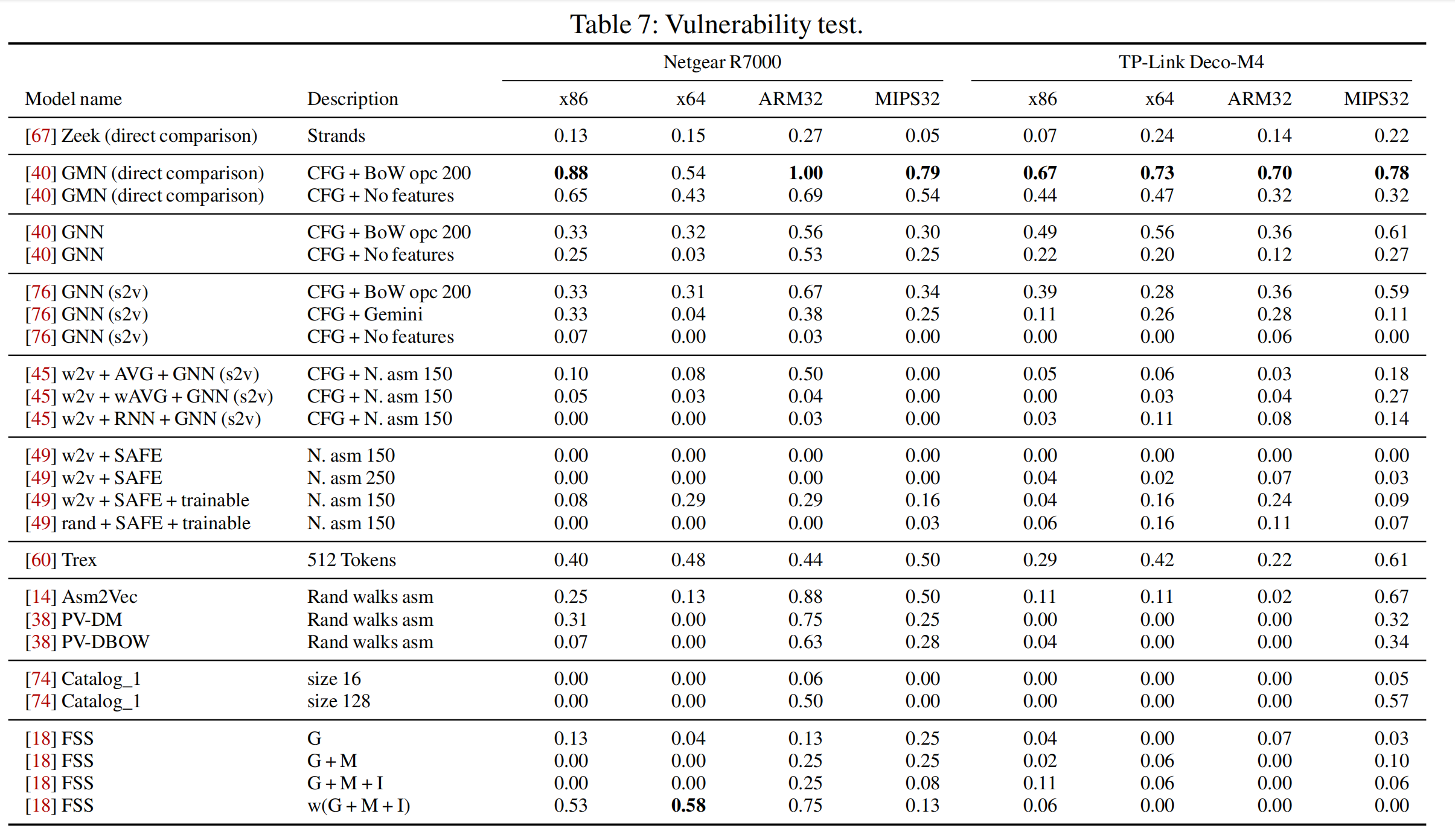
6. 漏洞发掘的样例
问题
- 测试的时候使用的Ranking measures(MRR10与Recall@K)的作用?