
【论文阅读】Comparing One with Many — Solving Binary2source Function Matching Under Function Inlining
一、ABSTRACT
为了在函数内联下施行b2s函数匹配,我们提出了一个叫O2NMatcher的方法,通过其生成的Source function Sets (SFSs)作为匹配结果。
我们首先提出了一个模型EOOCJ48来预测内联的位置, 为了训练这个模型,我们利用可编译的开源软件(Open Source Software)生成一个带有标记的调用点(内联或不内联)的数据集,从调用点中提取几个特征,并通过检查不同编译之间的内联相关性来设计一个基于编译器-选项的多标签分类器。
然后,我们使用这个模型来预测不可编译的开源项目,得到带标记的函数调用图。接下来,我们将SFSs的构建视为一个子树生成问题,并设计根节点选择和边缘扩展规则来自动构建SFSs。最后,这些SFSs将被添加到源函数的语料库中,并与有内联的二进制函数进行比较。
我们对OSNMatcher进行了一些实验测试,结果表明我们的方法超过所有state-of-the-art,将结果提升了6%。
二、背景知识
**Function inlining:**函数内联。使用inline关键字,编译器将函数调用语句替换为函数代码本身(称为扩展的过程),然后编译整个代码。因此,**使用内联函数,编译器不必跳转到另一个位置来执行该函数,然后跳回。**因为被调用函数的代码已经可用于调用程序。
[Inlining Decisions in Visual Studio - C++ Team Blog (microsoft.com)](https://devblogs.microsoft.com/cppblog/inlining-decisions-in-visual-studio/#:~:text=Inlining is perhaps the most important optimization a,in either the caller or callee by themselves.)
Binary2source function matching,二进制到源码函数匹配:
- 1-to-1匹配:一个二进制函数与一个源码函数匹配;
- 1-to-n匹配:由于内联函数的存在,一个二进制函数匹配多个源码函数。
**Stripped binary:**不含调试符号信息的二进制可执行文件。
**Multi-Label Classification (MLC) problem:**多标签分类,一个样本有多个标签。
FCG :Function Call Graph,函数调用图。在FCG图中,点是函数,边是调用关系。
**Jaccard similaritie:**又称为Jaccard index,用于比较有限样本集合之间的相似性和差异性。其值越大说明相似性越高。
**Binary Relevance:**核心思想是将多标签分类问题进行分解,将其转换为q个二元分类问题,其中每个二元分类器对应一个待预测的标签。
**Classifier Chains:**核心思想是将多标签分类问题进行分解,将其转换成为一个二元分类器链的形式,其中链后的二元分类器的构建式在前面分类器预测结果的基础上的。在模型构建的时候,首先将标签顺序进行shuffle打乱排序操作,然后按照从头到尾分别构建每个标签对应的模型。
**Ensemble Method:**集成学习算法。
三、提出问题
B2S匹配的作用:
当前软件开发基本都会使用公共开源库中的代码,这就造成一个问题,若公共开源项目OSS中存在漏洞会传播非常快(例如一个OpenSSL中的漏洞就可以造成互联网上17%web服务存在漏洞)。
由于以上问题的存在,检测软件中对OSS的依赖就很重要,**Software Component Analysis (SCA)**就是用来检测软件对OSS的依赖问题的。当商业软件公司发布了自己的二进制可执行程序时,SCA服务商就会将此二进制文件与OSS文件相比较,检测其包含使用了哪些OSS文件。
binary2source function matching就是其应用场景。
内联函数带来的问题:
举例如下图所示,当将二进制函数中的dtls1_get_record函数与源码中的dtls1_get_record函数比较时,使用CodeCMR给出的相似性还不足60%,这显然是匹配失败的。
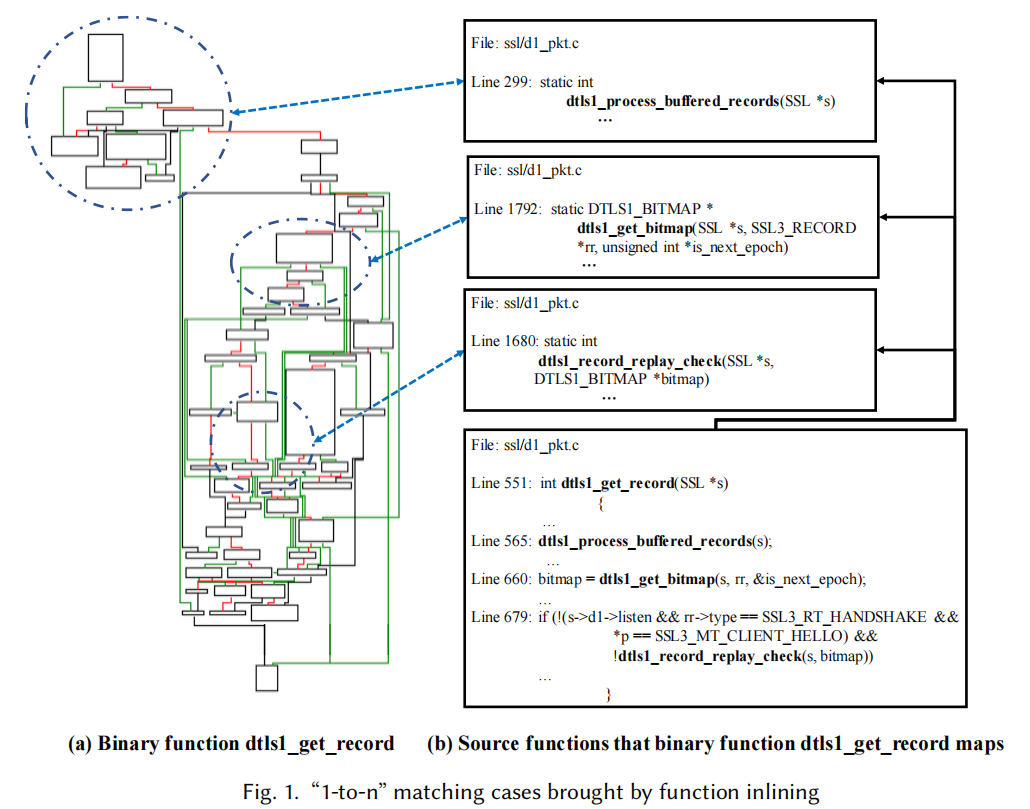
如果深入去看二进制函数dtls1_get_record的汇编代码就可以发现,这个函数在编译的时候内联了dtls1_process_buffered_records,dtls1_get_bitmap 和 dtls1_record_replay_check的函数代码,极大的改变了其函数的内部代码内容,故影响了函数的匹配结果。
有上述例子可以看出,由于内联函数的存在会改变函数的代码内容,故直接对其进行匹配的结果是不尽如人意的。
解决这个问题面临的挑战:
想要解决在内联函数下的B2S问题,还需面对以下挑战:
1) **OOD问题:**Out-of-domain,待检测二进制函数可能是由多个函数生成的,故OSS源码资料库中可能没有对应的二进制匹配;
2) **有些二进制文件不含调试信息:**对于许多不含调试信息的二进制文件,由于其没有标注内联点,故检测哪些函数是通过内联函数生成的和哪些源码函数被内联进了二进制函数中就更加困难;
3) **不同文件内联选择的不同:**对于不同的编译设置导致的不同内联函数的选择(对某个函数,是否选择内联),很难覆盖所有情况。
四、模型方法
我们的方法O2NMatcher就是为了解决上述挑战而生的。
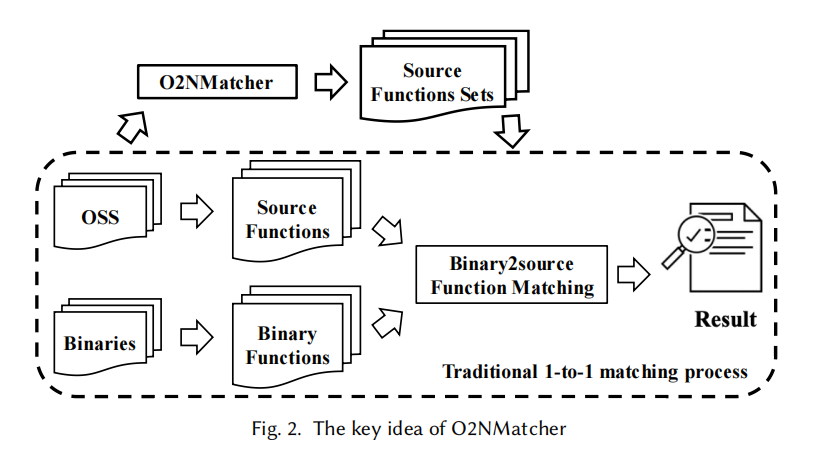
为了解决第一个挑战,我们生成了***Source Function Sets (SFSs)***来完善资料库,以此应对有内联函数的二进制函数查询匹配。
为了解决第二个挑战,我们使用可以编译的OSS项目训练了一个预测分类器来预测不可编译的OSS项目的内联位置。同时,我们提出了一个数据集自动化打标签的方法来生成数据。
为了解决第三个挑战,分类器被在多种不同的编译设置环境下训练,我们将其建模为多标签分类(MLC)问题,并根据不同编译设置下内联决策的相关性提出了基于编译器-选择的分类器。
通过给定的OSS生成SFSs,然后使用已有的“1-to-1”方法将这些SFSs与二进制函数相比较即可。
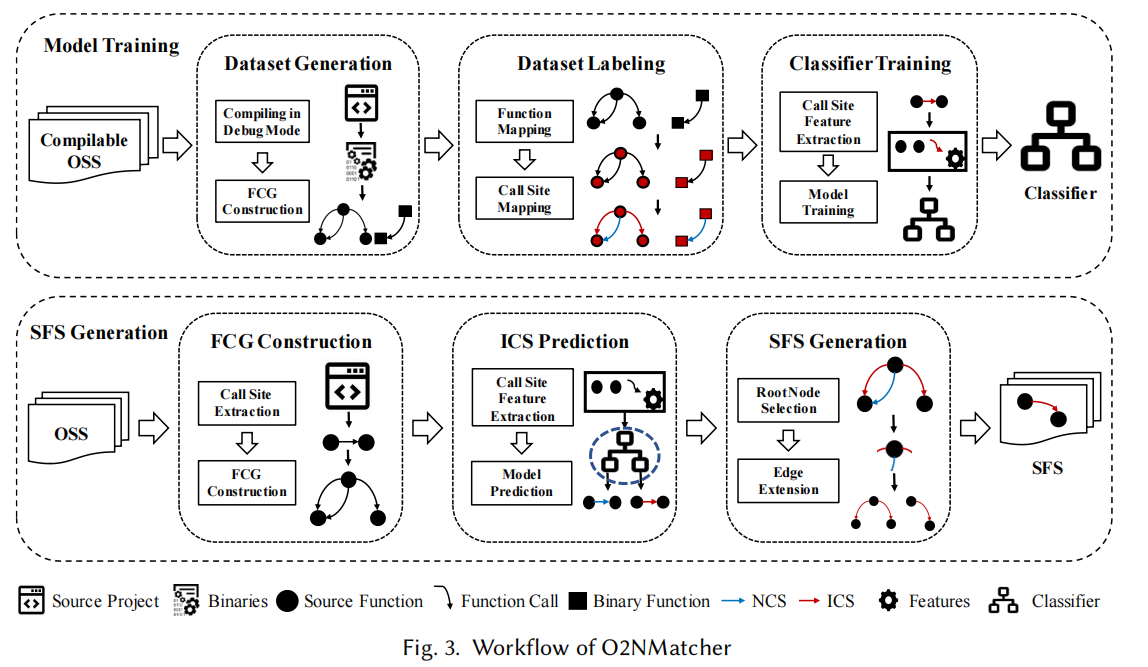
模型训练
1. 生成数据集
在生成数据集过程中,我们充分利用了编译过程生成的调试信息(用的都是可编译的OSS项目)。其会生成b2s行级别和函数级别的映射,并附带函数调用处的内联信息(是否内联)。
在开源项目编译时使用”-g”选项,可以使编译出的二进制文件附带从二进制地址到源文件某一行的映射信息(行级别映射),再利用Understand或者IDA Pro,tree-sitter,Chidra等工具,我们可以生成从二进制地址到源文件某一函数的映射信息(函数级别映射)。
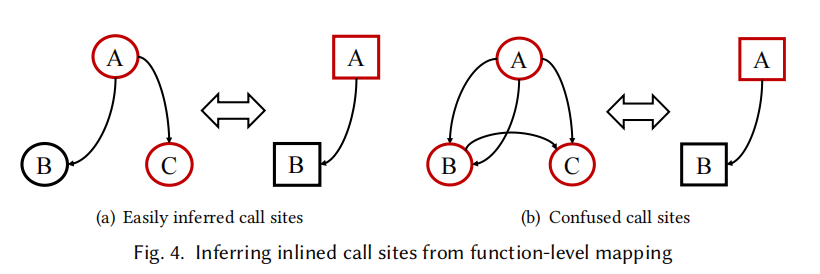
如上图所示,圆圈是源码函数,方框是编译后的二进制函数。在(a)中,由于A只调用了C一次,故在编译后的二进制函数中C就被内联进了A中;但在(b)中,A调用了两次B,A和B都调用了C,无法很清楚的判断到底哪次调用需要被内联,故编译出的二进制函数也与编译选项有关,并不绝对。
上述例子可以看出,即使我们得到的源码函数之间的相互调用关系我们也无法确定哪些函数会被内联。
但如果我们知道其二进制调用关系图,反过来看,若二进制图中某个调用在源码调用图中也存在(如上图a中的A–>B),则这个函数就不是内联函数,反之就是内联函数。这样,通过对调试信息的使用,可以成功的将可编译OSS项目的内联位置标注出来。
2. 特征提取
考虑到编译器一般通过评估内联的利弊来决定是否内联,我们总结了几个可以评估内联操作利弊的特征:
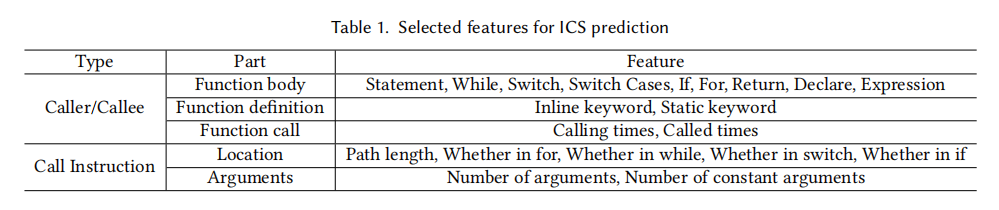
如上表所示,特征共分为两大类Caller/Callee和Call Instruciton:
Caller/Callee:
caller这里指调用其他公共开源函数的函数,callee指被许多其他函数调用的函数。这部分特征分为函数内部语句,函数定义语句和函数调用次数。
Call Instruciton:
调用函数指令,这里关注其调用的位置和参数声明,例如在内联循环中的函数调用就可以显著减少调用次数。同理,如果调用含有常量参数,可以帮助减少内联函数的大小。
3. 模型训练
3.1 训练数据分析
我们这里提出了一个名为**ECOCCJ48(Ensemble of Compiler Optimization based Classifier Chains built with J48)**的MLC模型来预测内联函数位置。在多标签任务中,标签之间通常存在联系,下表展示了两个编译器(gcc-8.2.0和clang-7.0)在Ox优化下的内联措施的差异和联系:
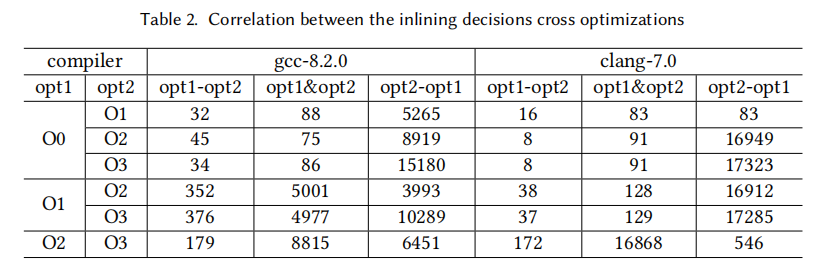
PS:opt1-opt2意味着使用优化措施opt1时内联,使用优化措施opt2时不内联的数量;opt1&opt2意味着使用两个都内联的数量。
在同一编译器不同优化设置的条件下,由上图可以看出,94.78%的内联操作如果出现在低级优化措施的条件下,也会出现在更高级的优化措施条件下。所以在同一行内opt1&opt2的数量都大于opt1-opt2。
在不同编译器的条件下,如下图所示,展示了不同优化措施下所做决策的Jaccard系数:
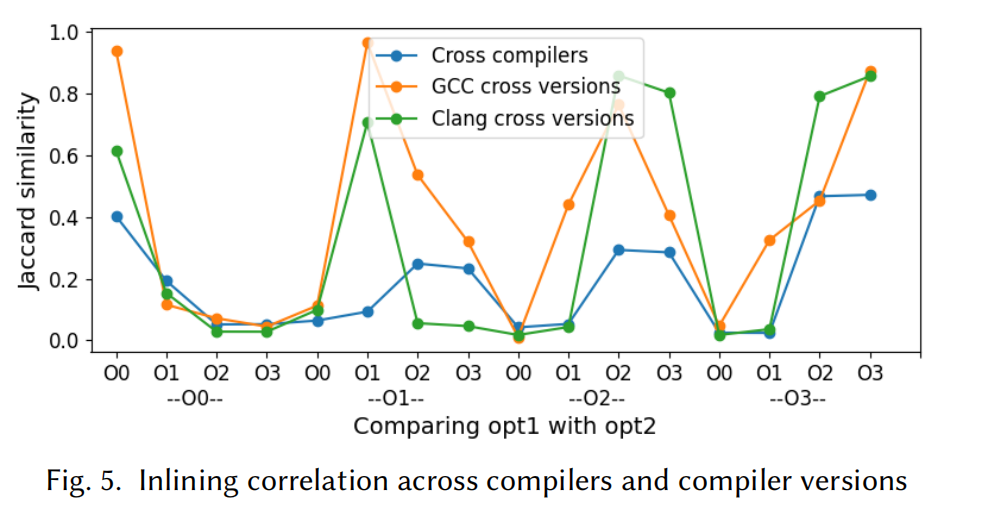
**在同一编译器家族(例如GCC的不同版本)比较时,其内联决策的相似性很高。**当使用O0-O3优化措施测试gcc-6.4.0 和 gcc-7.2.0,87%的函数调用采用了相同的内联决策。**在不同编译器的条件下,**其内联决策没有明显的联系。
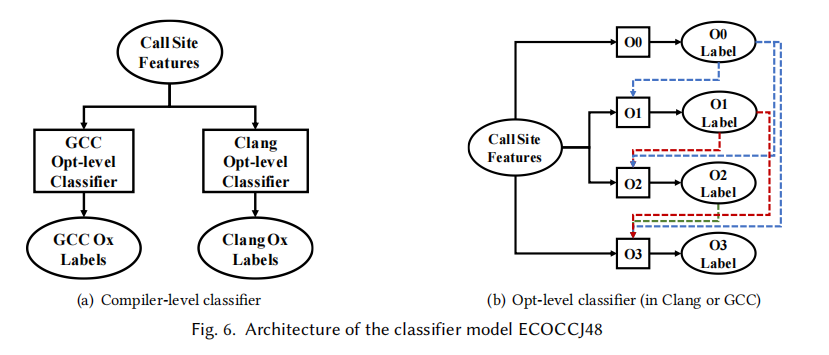
3.2 ECOCCJ48模型
ECOOCJ48分为两个部分,使用binary relevance来预测不同编译器下的标签,使用整合分类器链来预测同一编译器下不同优化措施的标签。
3.3 不平衡的数据集
目前存在的数据集有以下问题:
1.大多数的函数调用在被编译的过程中是不会被内联的,在使用OX优化时,大约只有20%的函数调用会被内联;
2.不同优化措施编译时内联点的比例也不同。
这些差异导致了训练数据集的不平衡,训练会更偏向于正常的调用。我们使用了集成学习方法来处理这些不平衡,其使用随机选择的数据集来训练,通过整合不同基础分类器的结果来预测标签。因为不同基础分类器在不同的资料库中被训练,故他们可以抓住内联模式。
SFS生成
1. FCG构建与ICS预测
对于不可编译的OSS项目,首先使用一个解析器(parser)来提取代码中的函数调用点,构建FCG图。两个节点之间可以有多个有向边,边上附带函数调用的位置信息。
对于FCG中的每个调用点,我们从其调用者,被调用者和调用指令中提取特征,将其作为ECOCCJ48的输入,得到所有编译设置(不同编译器+优化措施)的标签。
2. SFS生成
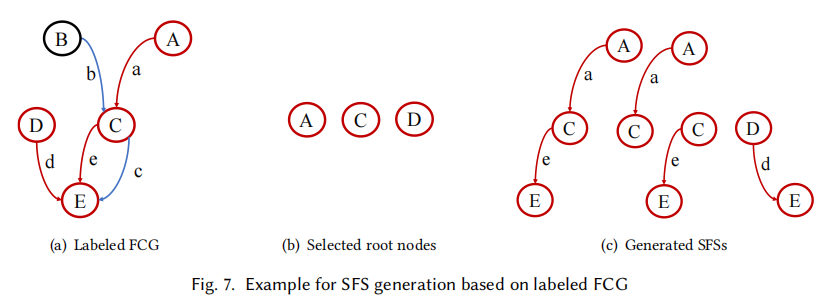
如上图所示,(a)就是已经构建好的FCG图,其中红圈代表有内联函数的函数,黑圈则没有;红边代表内联操作,蓝边代表正常调用。**假设FCG是一个有向无环图,SFS的生成就可以抽象成从FCG图中选择内联子树。**这里将SFS的生成分为两个部分:根节点的选择(b)和边扩展。
根节点的选择上,有以下原则:
1) 内联子树的根节点,如A,D;
2)非内联子树的根节点,但是既内联调用了其他函数,也被其他函数普通调用,如C。
除去这两种情况,要么一个节点没有指向其他节点的红色边,要么在内联子树上仅仅被其它红边所指。第一种情况显然不能进入SFS,第二种情况会被内联进其调用者之中。
边扩展上,遵循以下规则:
1) 对每个根节点,若其指向的节点仅有一条红边,则向下遍历其能遇到的所有节点(如对A,有A->C,A->C->E两条);
2)对每个根节点,若其指向的节点有两条相异颜色的边,则红色的边继续向下搜索生成,蓝色的边仅在下个点处停止。(如对C->E)。
若FCG成环,我们仅需注意,如果一个被调用节点已经在SFS中了,就不必再次遍历即可避免重复。
3. SFS汇总
得到函数的SFS后,我们将被调用函数的代码直接放进调用函数中。
测试评估
测试部分回答了以下问题:
- O2NMatcher可以提高现有1-to-1工作的表现吗?
- 与Bingo 和 ASM2Vec比较,O2NMatcher生成的SFS有多准确?
- 与现有的多标签分类工作相比,ECOCCJ48的表现如何?
- O2NMatcher在训练,预测和生成SFS的时间花费如何?
- 我们选取的特征集在ICS预测上有什么贡献?
1. 研究背景
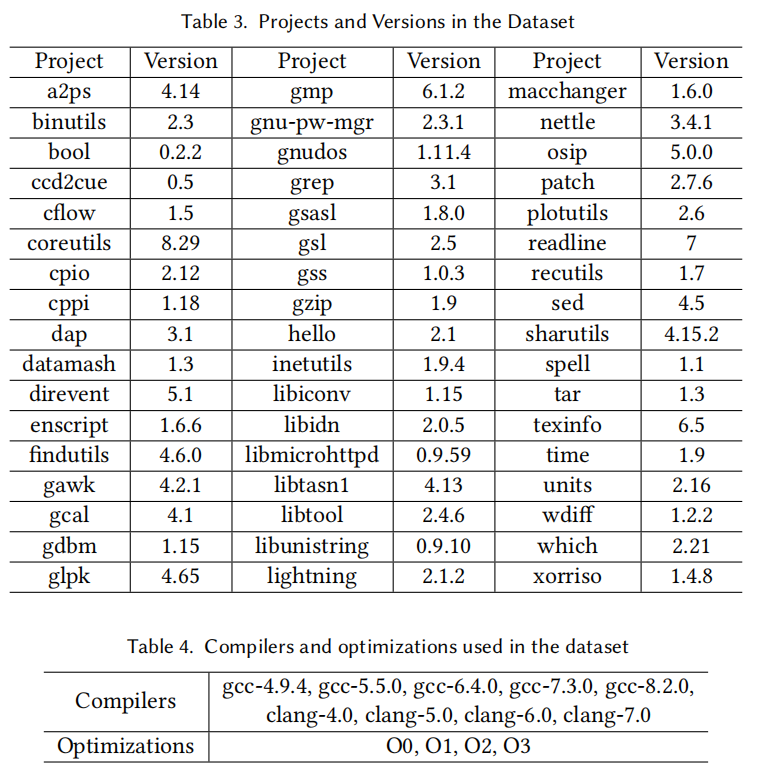
1.1 测试数据集
我们从GNU项目选择了51个包,使用9种编译器、4种优化措施编译成x86-64,得到8460个二进制文件和4294478个二进制函数。这些数据包含了诸如Coreutils、OpenSSL等在二进制相似性检测工作中广泛被使用的包。如下表所示:
1.2 Benchmark
因为O2NMatcher是一个对其它b2s方法的补充,我们需要选择一个baseline。这里我们选择CodeCMR,一个现有工作表现最好的b2s方法。CodeCMR有一个开放工具BinaryAI,可以方便后续测试。
(Zeping Yu, Wenxin Zheng, Jiaqi Wang, Qiyi Tang, Sen Nie, and Shi Wu. 2020. Codecmr: Cross-modal retrieval for function-level binary source code matching. Advances in Neural Information Processing Systems 33 (2020), 3872–3883.)
1.3 实验设置
**90%随机选择的训练集以及10%测试集。**由于相同编译器的内联选择比较相似,这里测试集仅用两个编译器生成:gcc-2.2.0和clang-7.0。测试集包含1.1中所有的编译器生成的数据。分类器在训练集上训练,然后对测试集生成SFSs。为了避免误差我们重复实验10次。
测试时,使用不带调试信息的stripped binary,并且OSS文件不能被编译。
1.4 评估标准
使用标准召回率recall@K来评估O2NMatcher准确率。(Recall@K召回率是指前topK结果中检索出的相关结果数和库中所有的相关结果数的比率,衡量的是检索系统的查全率。)在这里,recall@K代表前k个模型返回的源码函数中真正的源码函数占比。对于1-to-1匹配,真正的源码函数就是该待检测二进制函数的源码;对于我们的1-to-n匹配,在SFSs中,某个函数的根函数是真正的源码函数也可以算作阳性样本。在接下来的实验中我们会使用K = 1、10和50来测试。
使用SFS大小(SFS size)来评估O2NMatcher成本。SFS size是已生成的SFSs数量比上原函数集的数量。因为新增的SFSs增加了资料库的大小,故可能影响查询匹配的时间。
使用precision、recall和F1-score来评估ECOCCJ48准确率。
1.5 O2NMatcher的实现
在数据集标注工作上,我们使用Understand对源码做语法分析,使用IDA Pro来反汇编二进制文件。在FCG构建上,我们使用Understand来提取所有函数调用点,对源码生成FCG图,使用IDA Pro对二进制文件生成FCG图。在函数调用特征提取上,我们使用tree-sitter来提取函数体、函数定义和函数调用指令的特征,使用Understand提取函数调用次数特征。
在模型训练工作上,我们使用Python工具scikit-multilearn来实现ECOCCJ48模型和其他MCL方法。整个程序在Ubuntu 18.04、Intel Xeon Gold 6266C、1024GB DDR4 RAM、Nvidia RTX3090 GPU环境上运行。
2. 对问题一的回答:O2NMatcher的效果

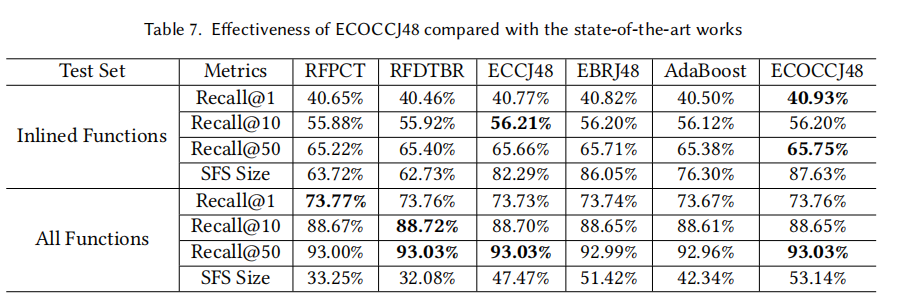
3. 对问题二的回答:SFSs的效果
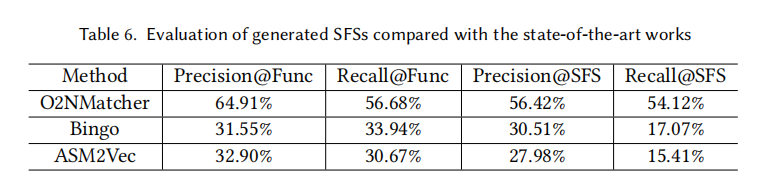
上表比较了O2NMatcher、Bingo和ASM2Vec生成的SFSs与标准答案的结果。
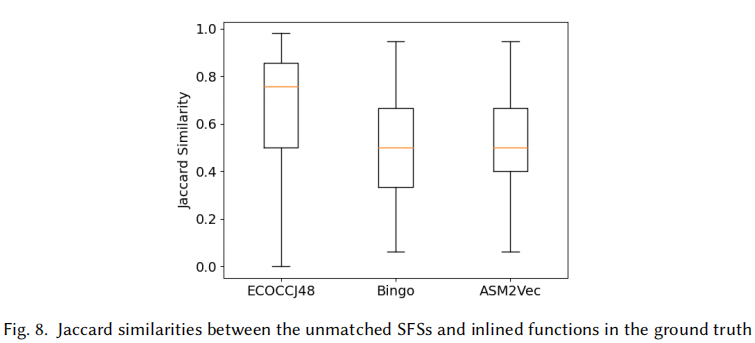
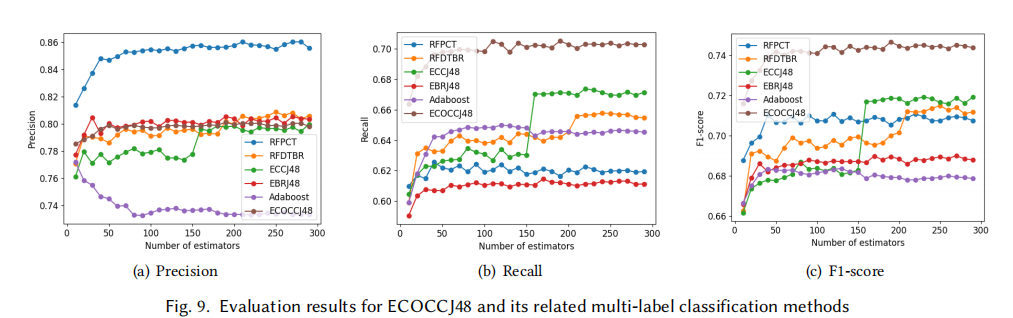
4. 对问题三的回答:ECOCCJ48的效果
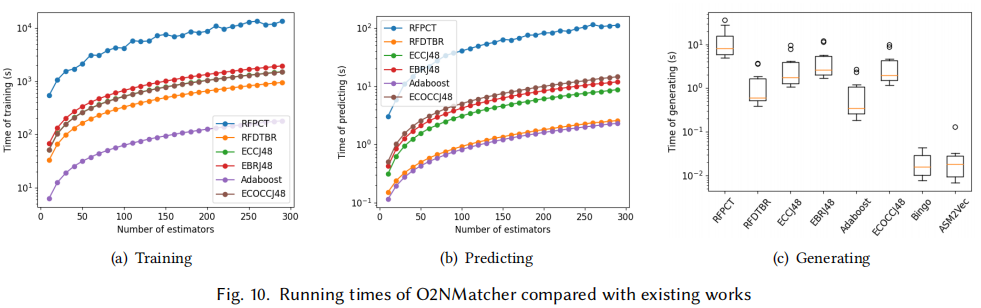
5. 对问题四的回答:O2NMatcher的成本
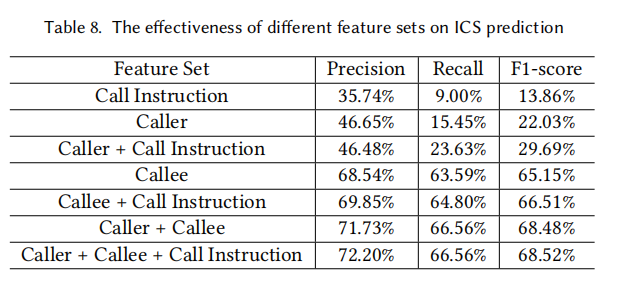
6. 对问题五的回答:特征选择的作用
五、问题
该方法模型怎么结合已有的方法?
原来怎么比现在就怎么比,只是从源码库变成了SFS。
SFSs怎么起作用?
将可能内联的函数体放进原函数的新代码库。
不平衡的数据集怎么处理的?
“We use ensemble methods to handle the imbalanced dataset. The ensemble method trains the base classifiers on the randomly selected dataset and predicts the labels by ggregating the predictions from the base classifiers. As different base lassifiers are trained in different corpora, they can capture the inlining patterns of some rare labels”这部分没看懂什么意思
在汇总SFS时:
“Directly, there are two ways to aggregate the SFS: conduct inlining for the source functions in the SFSs such as the inlining during compilation or directly aggregate the content of all the functions in the SFS”,这两种方式具体什么区别?