
GREBE: Unveiling Exploitation Potential for Linux Kernel Bugs
时间:2022
作者:Zhenpeng Lin,Yueqi Chen,Yuhang Wu
会议:SP
ABSTRACT
最近,动态测试工具显著提升了Linux内核漏洞的发掘速度,这些工具会在挖掘漏洞时自动地生成报告,具体说明Linux系统的error。报告中的error暗示了相应的内核错误的可能的exploitability,因此,许多安全分析员使用(报告中)表现出来的error来推断一个错误的可利用性,从而考虑其exploit开发的优先级。然而,使用报告中的error可能会低估一个错误的可利用性。报告中表现出的error可能取决于该error是如何被触发的。通过不同的路径或在不同的背景下,一个error可能表现出各种错误行为,意味着非常不同的利用潜力。
此文提出了一个新的内核fuzz技术来找到所有可能的内核漏洞的error的表现。与传统的专注于内核代码覆盖率的内核fuzzing技术不同,我们的fuzzing技术更多的是针对有漏洞的代码片段。为了探索不同触发同一个bug的上下文/路径,文章引入了object-driven内核fuzzing技术。通过新探索的error,安全研究人员可以更好地推断出一个error的可利用性。
为了评估我们提出的技术的有效性、效率和影响,我们将我们的fuzzing技术作为一个工具GREBE来实现,并将其应用于60个真实世界的Linux内核漏洞。平均来说,GREBE可以为每个内核漏洞表现出2个以上的额外错误行为。对于26个内核错误,GREBE发现了更高的开发潜力。我们向内核供应商报告了其中的一些错误–这些错误的可利用性被错误地评估了,相应的补丁还没有被仔细地应用–导致他们迅速地采用补丁。
问题背景
1. 根据分析结果确定漏洞优先级
为了提高Linux其安全性,研究人员和分析人员引入了自动化的内核fuzzing技术和各种调试/sanitzation功能。在他们的推动下,安全研究人员和内核开发人员变得更容易确定Linux内核中的错误。然而,要确定触发bug的条件是否足以代表安全漏洞,仍然是一个挑战。例如,一个表现out-of-bound错误行为的bug通常意味着比那些表现出空指针解除引用错误行为的bug有更高的机会被利用。因此,我们的调查结果和以前的研究[1]、[2]、[3]都表明,在确定漏洞开发工作的优先次序时,漏洞的表现出的错误行为起着关键作用。
2. 自动化漏洞扫描工具提供的错误报告不完善
在实践中,当现有的fuzzing工具识别出一个内核错误时,该错误所表现出来的错误行为可能是其众多可能的错误行为之一。它的其他可能的错误行为可能与已经暴露的错误行为相去甚远。通过遵循不同的路径或执行环境来触发内核错误,我们可以使内核错误不仅表现出不太可能被利用的GPF错误,而且表现出极可能被利用的UAF错误。因此,如果只使用单一表现的错误行为来推断该错误可能的可利用性,这可能会产生一定误导。
3. 解决思路
为了解决上述问题,一种本能的反应是把一个内核错误报告作为输入,分析该内核错误的根本原因,并推断出该错误的根本原因可能带来的所有可能的后果(例如,内存越界、空指针解引用和内存泄漏等)。然而,根源诊断通常被认为是一项费时费力的工作。因此,我们认为,解决这个问题的一个更现实的策略是,在不进行根本原因分析的情况下,揭露出一个给定的内核错误的许多可能的后触发错误行为。然后,从公布的错误行为中,安全分析师可以更好地以更准确的方式推断其可能的可利用性。
4. 已有的方法
我们可以借用内核fuzzing的概念。然而,现有的内核fuzzing方法主要是为了最大化代码覆盖率而设计的(例如,Syzkaller[4]、KAFL[5]和Trinity[6]等)。在我们的任务中使用这些方法不可避免地存在效率低下和效果差的问题,这只是因为代码覆盖率驱动的内核fuzzing法没有被在该问题下定制,也没有为寻找与同一错误代码片段相关的各种路径或上下文进行优化。
为此,我们提出了一种定制的内核fuzzing处理机制,它将fuzzing处理的能量集中在有缺陷的代码区域,同时,将内核执行路径和上下文分散到目标有缺陷的代码片段。
问题引入
我们提出的内核fuzzing技术可以被看作是一种定向fuzzing技术。它首先将一个内核错误报告作为输入,并提取与报告的内核错误相关的内核结构/对象。然后,该方法进行fuzzing测试,并利用已识别的内核结构/对象的点击率作为对fuzzer的反馈。由于确定的内核结构/对象对成功触发错误至关重要,利用它们来指导fuzzing可以缩小内核fuzzer的范围,使fuzzer主要关注与报告错误有关的路径和背景。在这项工作中,我们将这种方法作为一个内核对象驱动的fuzzing工具来实现,并以GREBE命名,意味着 “多行为探索fuzzing”。
1. 例子

如上图所示,函数tun_attach是网络接口配置函数,它的参数tun是一个所有处于open状态的tun文件共享的全局变量。代码第3行表明,如果IFF_NAPI在tun->flags中被设定,内核将初始化一个定时器,并将相应的napi链接到网络设备napi_list的列表中。代码第12行表明,函数tun_detach负责清理tun_file中包含的数据以及关闭该文件。如果IFF_NAPI被设置,内核将取消定时器并从设备的napi_list中删除napi。在第24行,函数free_netdev将通过napi_list来删除列表中的napi。
这里的bug是由于tun_attach和tun_detach中的标志tun->flags的可能存在的不一致导致的。
以Syzkaller产生的内核错误报告为例:
报告所附的PoC显示,一个系统调用在IFF_NAPI未设置的情况下调用了tun_attach。这样一来,内核既没有初始化定时器,也没有将相应的napi添加到列表中。在这个设置之后,PoC程序进一步调用系统调用ioctl函数,在调用tun_detach之前在tun->flags中设置IFF_NAPI,这导致tun_attach和tun_detach的标志不一致。然后,在第17行,内核试图停止定时器,它解除了对tun_detach中的定时器对象所包含的指针的引用。然而,如上所述,定时器在tun_attach中没有被初始化,这导致了一个一般保护故障。一般保护故障意味着访问未被指定使用的存储。因此,基于这个单一的观察,许多分析人员可能会推断出这个错误可能是不可利用的。
然而,通过改变PoC程序,修改共享变量的赋值方式,我们可以让内核表现出一个UAF错误。具体来说,我们可以在调用函数tun_attach之前用IFF_NAPI设置tun->flags。这样,在调用tun_attach后,它可以将相应的tun_file添加到设备列表napi_list。在这个设置之后,我们可以进一步调用ioctl来清除tun_flags,然后再调用tun_detach。如上图,函数tun_detach在第18∼19行没有从列表中删除相应的napi,而是在第21行free了它。因此,当遍历设备列表时,拥有KASAN功能的内核将抛出UAF的错误。与报中显示的错误相比,这种非允许的访问不是访问一个无效的内核内存地址而产生一般的保护故障,而是与一个有效的内核内存地址联系在一起,并最终可以破坏内核内存。因此,基于这个UAF错误,许多分析人员可能认为这个错误可能是可利用的。
ps:
- Kernel Address SANitizer(KASAN)是一种动态内存安全错误检测工具,主要功能是检查内存越界访问和使用已释放内存的问题;
- UAF,Use after free。
2. 设计原理
鉴于内核错误报告展示了一个特定的错误行为,探索该错误其他可能的错误行为的一个本能反应是利用directed fuzzing,即探索通往我们感兴趣的程序站点的路径。但这种方法有两个局限:
- 首先,为了使用directed fuzzing来暴露多种错误行为,我们需要确定有错误的代码片段(即错误的root),将其作为锚点,并将其提供给directed fuzzer。然而,要正确和自动地确定内核错误的root是很有挑战性的。如果不正确地将一个非根本原因的点视为fuzzer的锚点,甚至可能使fuzzer无法触发该错误,更不用说找到该错误的多种错误行为了;
- 其次,即使我们能够指出内核错误的根源,也不意味着内核可以表现出多种错误行为。除了遵循不同的路径到达有缺陷的代码外,错误行为的展示也依赖于错误触发后的环境。例如,除了遵循一个特定的路径到有缺陷的代码片段,我们还需要一个单独的内核线程来改变一个全局变量,使触发错误和展示不同错误所需的背景多样化。根据设计,定向fuzzing法在接触到其感兴趣的目标代码后不能改变上下文。
在本文,我们通过扩展现有的带有内核-对象指导的内核fuzzing方法来解决这个问题。根据我们对许多内核错误的观察,我们发现内核错误的根本原因通常来自两种:
**对内核对象的不恰当使用。**这进一步导致了内核错误(例如前面提到的为tun_struct类型的内核对象分配不一致的标志值的案例);
在使用内核对象进行计算时涉及到一个不正确的值,它被进一步传播到一个关键的内核操作中,迫使内核表现出一个错误(例如,一个未消毒的整数被用作内核对象的偏移量,导致一个越界的内存访问)。
因此,在错误报告中指定的与错误相关的对象的指导下,我们可以让内核fuzzer远离那些与错误无关的路径和上下文,从而显著提高其效率。
模型方法

如上图所示,首先将一个内核错误报告作为输入,运行所附带的PoC,并追踪那些涉及内核错误的内核结构(例如,例子中的结构tun_file)。进一步检查内核源代码,找出操作这些类型的对象的代码语句。我们将这些语句视为对内核错误触发的成功至关重要的锚点。因此,我们对这些语句进行检测,以便在进行内核fuzzing时收集对象覆盖率作为反馈,然后利用覆盖率来调整相应的PoC程序。在这项工作中,我们的内核fuzzing机制将错误报告中附加的原始PoC程序作为输入。使用一种新的突变和种子生成方法,它逐步改变PoC,提高了已知错误的多种错误行为探索的效率和效果。
1. 确定关键结构
利用后向污点分析来识别基本的内核结构(即参与给定报告中错误的相关结构)。
1.1 报告分析 & 确定污点源
1.1.1 Explicit Checking

在上图中,函数vhost_dev_cleanup()的作用是:如果dev->work_list为空,清除连接到vhost_dev设备上的worker;否则通过WARN_ON内的宏报错。故在这里,污点分析的sources应该就是dev->work_list。在这个例子中,内核开发者明确地将预定义的条件制定为一个表达式,并将其传递给宏WARN_ON进行错误处理。然而,对于其他一些调试功能,检查是由编译器检测的,或者由硬件完成,而不是由内核开发者编写的一段源代码。对于这些功能,条件是隐含的,不能从内核的源代码中识别。
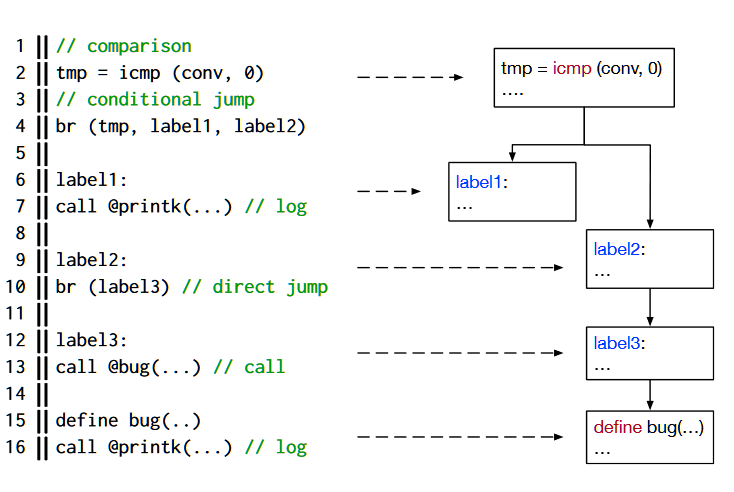
Explicit Checking就是对这一类明确条件的检查。内核开发者明确地将检查制定为一个表达式,并将其传递给标准调试功能,如WARN_ON和BUG_ON。这些宏是模式化的代码块,包括条件语句和日志语句,如果条件得到满足就会执行。除了这种标准化的记录内核错误的方式外,开发者还可以建立自己的宏,将日志语句包裹在一个辅助函数中(如上图15,16行)。
为了找到触发bug日志记录语句的源头,确定污点分析的sources,需要沿着支配树(如上图右半部分)回溯,直到找到一个条件跳转基本块。然后,我们将其相应的比较语句作为触发error记录操作的条件,从其中提取相应的变量作为sources。
1.1.2 Implicit Checking
对于由编译器检测或由硬件完成的相关条件检查,称之为隐式检查。
对于通过编译器工具完成的隐式检查,内核地址消毒器(KASAN)可以对每一个内存访问进行检测,这样就可以检查对一个内存地址的访问是否合法。KASAN依靠影子内存来记录内存状态。例如,如果被检测的内核触及一个已释放的内存区域,它将产生一个错误报告,指出引发使用后释放错误的指令。关于中断所做的隐性检查(例如,由MMU检测到的一般保护故障),中断处理程序负责记录相应的指令。从这些调试机制产生的错误报告中,我们可以很容易地确定执行无效内存访问的指令。有了这些信息,我们的下一步就是确定与该无效内存访问相关的变量。

一般报告中所包含的错误指令是二进制指令。为了处理这个问题,从调试信息中,需要将二进制指令与源代码中的相应语句进行映射。假设对应的源代码是一个简单语句,只有一个加载或存储操作,在这种情况下,这个语句就是导致非法内存访问的语句,并将操作数变量作为污点源处理。然而,如果被识别的指令链接到一个涉及多个内存加载和存储的复合语句(如上图中描述的walk->offset = sg->offset),将进行进一步的分析。
具体来说,首先检查错误报告,并找出捕捉到内核错误的具体指令。然后,把与捕捉错误的指令相关的内存访问操作作为我们的sources。再次以上图中的情况为例。错误报告指出错误是由语句kasan_check_read(&sg->offset, sizeof(var))捕获的,它与sg->offset有关。故这里认为第2行的sg->offset是污点源。
1.2 污点传播 & 确定sink
从错误报告中提取调用痕迹(call trace),基于call trace构建cfg,并在该图上向后传播污点源。
- 如果被污染的变量是一个嵌套结构的字段或一个联合变量,则进一步污染其父结构变量,并将父结构视为一个关键结构(原因是,嵌套结构或联合变量是内存中父结构变量的一部分。如果嵌套结构或联合变量的某个字段带有一个无效的值,这很可能是由于对其父结构变量的不恰当使用造成的);
- 当污点传播遇到一个循环时,如果污点源在循环内被更新,那么也将循环计数器污染(举例,一些越界操作就是由于循环计数器被修改/破坏/扩大,导致访问了无效的内存区域)。
当以下条件之一成立时终止污点传播,在进行污点向后传播的同时,也将传播扩展到被污点变量的别名上:
- 污点传播到了污点变量本身的定义语句;
- 污点传播到了系统调用的入口、中断处理程序或启动工作队列调度器的函数入口;
2. 内核结构排序
成功识别所有与报告中的错误有关的内核结构后,直接fuzzing可能导致效率低下问题,故这里做进一步缩小操作。
2.1 内核结构选择
在Linux内核中,提供了一个用来创建双向循环链表的结构 list_head。虽然linux内核是用C语言写的,但是list_head的引入,使得内核数据结构也可以拥有面向对象的特性,通过使用操作list_head 的通用接口很容易实现代码的重用。在整个内核代码库中,list_head结构被广泛地使用。如果将这种结构和相应的对象纳入内核模糊指导,内核模糊器将不可避免地探索一个大的代码空间,使模糊器偏离重心。因此,为了保持内核fuzzer探索的效率,我们需要将这些结构从我们的内核fuzzing中排除。
除了上面提到的结构,Linux内核开发者还实现了许多其他与抽象接口有关的结构。这些接口与实现层耦合在一起,以支持大量的设备和功能。例如,内核为所有从用户空间请求的网络服务创建了一个结构socket ,不管指定什么协议。因此,与struct list_head类似,它们也应该在后期的内核fuzzing中被排除。
为了精确定位并排除这些结构,这里设计了一种系统的方法,根据内核结构的流行程度对其进行排序。在更高层次上,这个方法构建了一个描述内核结构之间引用关系的图。图中的每个节点代表一个内核结构,而节点之间的有向边表示参考关系。在该图上,应用PageRank算法,给每个结构分配一个权重,排除较高权值的结构。
2.2 构建图结构

对于结构定义语句,给定一个结构,我们浏览它的所有字段成员。如果字段是一个指向另一个结构的指针,我们就把给定的结构与被引用的结构联系起来。如上图extensions是一个引用struct skb_ext的指针,就在图中把sk_buff结构链接到skb_ext结构。
struct rb_node是一个匿名union中的自我引用结构。这里就跳过匿名union,只将struct sk_buff直接链接到struct rb_node,而无需进一步扩展。

**对于类型转换语句,*由于内核支持多态,例如上图中ip6_fraglist_init函数,skb->data从void被投射到struct frag_hdr。void 是一个抽象的数据类型,而结构类型struct frag_hdr*则更加具体化。因此,我们在结构图中增加了一条边,将结构skb_buff连接到结构frag_hdr。
利用构建的图,使用PageRank算法对其流行程度进行排序。只使用那些等级较低的内核结构和对象来指导fuzzing。
2.3 技术性研讨
根据我们对数百个真实世界的内核错误的观察,大多数内核错误的根本原因与不太流行的结构有关。因此,删除流行的结构并不会对模糊器触发我们感兴趣的错误产生负面影响。
即使被消除的流行结构与我们感兴趣的内核错误的根源有关,让模糊器专注于这些不太流行的结构,仍然可以让我们接触到流行结构类型中的一些对象。原因是不太受欢迎的结构通常是由受欢迎的结构组成的(例如,list 1中罕见的结构struct napi_struct包含受欢迎的结构struct hrtimer)。
3. 对象驱动内核fuzzing
传统的内核探索方法是利用跟踪函数来跟踪已经执行的基本块。在这项工作中,我们的探索机制保留了这种能力,并进一步引入了一个额外的工具化组件。其被设计成一个编译器插件,该插件检查基本块中的每条语句,并识别那些负责分配、删除和使用关键对象的基本块。更具体地说,组件引入了一个新的追踪功能,它将记录的基本块地址中最重要的16位替换为一个神奇的数字,以将这些基本块与其他基本块区分开来。有了这些工具,通过观察代码覆盖率反馈中最重要的16位地址,我们可以很容易地确定哪些与关键对象有关的基本块是在fuzzing程序的操作之下的。当运行一个模糊测试程序时,我们可以很容易地确定它是否接触到了一个关键对象。
3.1 种子选择
若程序接触到了一个新的涉及关键对象的基本块/至少有一个系统调用涵盖了更多的代码(允许内核fuzzer积累内核状态,从而增加未来突变的可能性,以达到涉及关键对象的未见过的基本块。),并操作了关键对象时,将变异的种子添加到库中。
3.2 种子生成 & 变异
使用报告中的POC程序用作初始种子,每次在生成新的种子时,只使用已经包含在种子库中的系统调用来组装新的种子。
进一步引入了现有内核fuzzing(即Syzkaller)中使用的变异机制。这种突变机制将与种子库中已包含的系统调用相关的新系统调用引入种子中。
3.3 变异优化
在对模糊程序进行突变时,Syzkaller的突变机制利用预定义的模板来指导新种子的合成。模板规定了系统调用之间的依赖关系和相应系统调用的参数格式。例如,Syzkaller的模板规定,系统调用read需要一个resource(即文件描述符)作为其参数之一,openat()以及socket()将产生相应的resource。在这个模板的指导下,Syzkaller可以通过在系统调用openat()上附加系统调用read()或socket()来对模糊程序种子进行变异。模板指导下的突变确保了种子程序(也就是runner的输入)的合法性,从而避免了过早产生无效输入。

但是,这种基于模板的突变方式也不一定符合我们的需求。以上图两个POC程序为例,Syzkaller在a中插入了socket(),显然增大了搜索空间,不利于fuzzing;在b中,Syzkaller根据@max变量的合法范围是[INT_MIN,INT_MAX]从而改变了@max的值,但在此Bug中,只有@max=-1时bug才会被触发,故这里的突变也是副作用的。
**故为了更高效的fuzzing,这里需要进行变异优化。**根据相应的系统调用所依据的资源类型对系统调用规范模板进行分组(例如将与网络套接字和设备文件有关的系统调用分别归类)。在每组中,再将系统调用分为两个子组。一个是负责资源的创建,另一个是负责资源的使用。当变异种子程序时,我们的模糊组件要么用同一组中的系统调用替换,要么插入与种子程序中显示的资源相关的系统调用。
ps:
- 污点分析:三元组<sources, sinks, sanitizers>,代表污点源,污点会聚处和消毒器。