
(代码分析)GREBE-Analyzer污点分析代码解析
Code:Markakd/GREBE (github.com)
**Target:**GREBE/analyzer
一、get_cg.py & run_analyze.py
二、analyzer/src/lib
前置知识:
GREBE
LLVM IR
LLVM Pass(legacy manager & new manager)
C++面向对象
taint analysis
2.1 代码来源
analyzer的主要作用是用于污点分析,其基于的代码是ucr副教授Chengyu Song 基于kint(2013年的分析工具)的工作《Enforcing-Kernel-Security-Invariants-with-Data-Flow-Integrity 》,其在kint的基础上实现了自己的call graph和taint analysis。过去几年有多篇安全A类会议都使用了这份分析代码。

针对最新的LLVM(14)版本,目前也有开源的kint:ganler/mini-kint: Enhanced implementation of Kint in LLVM-14, in C++17. (github.com)
2.2 总体结构
analyzer的源码分为几个模块:KAMain、Annotation、CallGraph、CrashAnalyzer、PointerAnalysis。KAMain.cc是程序的主模块,其引用模块:
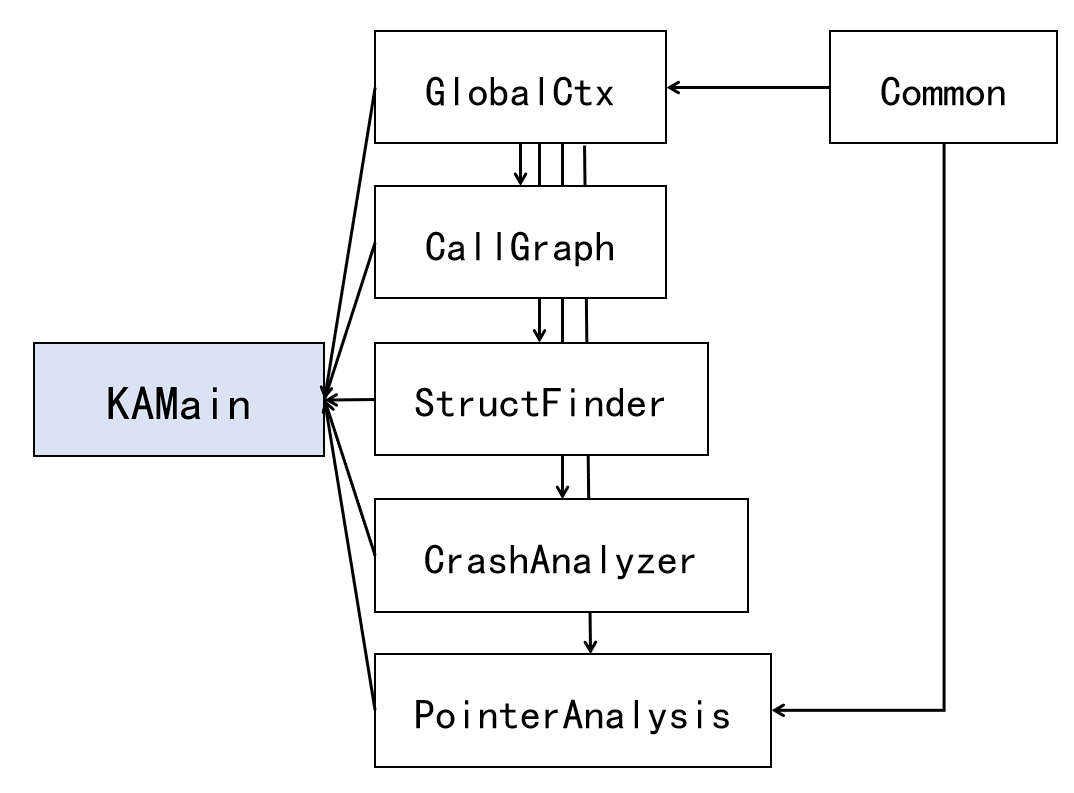
analyzer在GlobalCtx模块中定义了自己的Pass父类IterativeModulePass:
class IterativeModulePass {
protected:
GlobalContext *Ctx;
const char *ID;
public:
//构造者函数
IterativeModulePass(GlobalContext *Ctx_, const char *ID_)
: Ctx(Ctx_), ID(ID_) { }
// run on each module before iterative pass
virtual bool doInitialization(llvm::Module *M)
{ return true; }
// run on each module after iterative pass
virtual bool doFinalization(llvm::Module *M)
{ return true; }
// iterative pass
virtual bool doModulePass(llvm::Module *M)
{ return false; }
virtual void run(ModuleList &modules);
}; 可以看到IterativeModulePass实现了四个虚函数doInitialization、doFinalization、doModulePass和run分别用于Pass的运行前后处理以及在多个modules上运行Pass。从虚函数的定义就可以看出该项目使用的是旧版的Pass Manager。
项目中实现了四个子类,其继承关系如图所示:
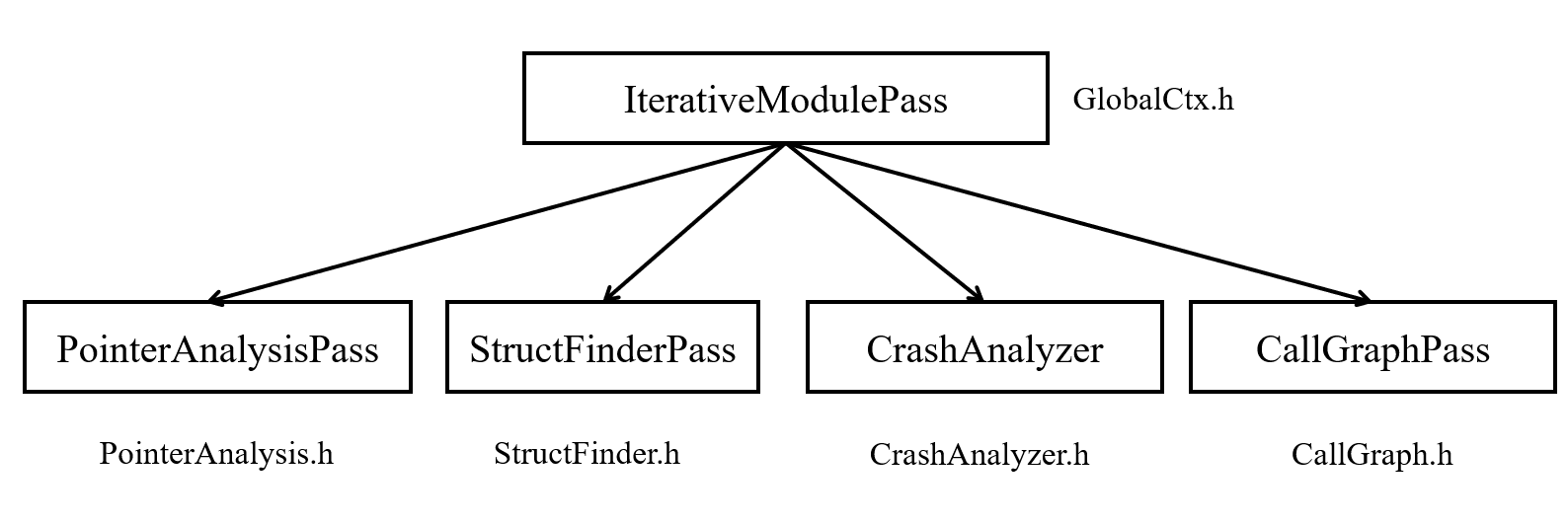
2.3 KAMain.cc
2.3.1 IterativeModulePass::run
IterativeModulePass::run的完整实现在KAMain.cc中,run函数的参数是一个module列表(ModuleList &modules),其数据结构是:
typedef std::vector< std::pair<llvm::Module*, llvm::StringRef> > ModuleList; llvm:StringRef类型表示一个固定不变的字符串的引用(包括一个字符数组的指针和长度),它支持可用在std::string类上的各种通用字符串操作。
①在run函数中,首先对传入的module列表进行遍历,并依次进行初始化操作:
//KAMain.cc
bool again = true;
while (again) {
again = false;
//遍历所有modules初始化,这里没有做任何操作
for (i = modules.begin(), e = modules.end(); i != e; ++i) {
KA_LOGS(3, "[" << i->second << "]");
// doInitialization只返回false,循环结束后again为0
again |= doInitialization(i->first);
}
} 这里的doInitialization和后续的doModulePass函数都是各个子类中定义的函数,其在父类的函数定义中出现是C++多态的体现,doInitialization函数并不通过IterativeModulePass类运行,而是通过其对应子类ChildName::doInitialization来运行子类特定的对应函数。由于所有子类中的doInitialization都只返回false,故这段初始化操作实际什么也没做。
②接着,对module列表中的每个module依次调用doModulePass函数,其调用各个子类中实现的Pass操作,并对结果进行统计。
//KAMain.cc
unsigned iter = 0, changed = 1;
while (changed) {
++iter;
changed = 0;
for (i = modules.begin(), e = modules.end(); i != e; ++i) {
KA_LOGS(3, "[" << ID << " / " << iter << "] ");
// FIXME: Seems the module name is incorrect, and perhaps it's a bug.
KA_LOGS(3, "[" << i->second << "]");
//运行Pass
bool ret = doModulePass(i->first);
if (ret) {
++changed;
KA_LOGS(3, "\t [CHANGED]");
} else {
KA_LOGS(3, " ");
}
}
KA_LOGS(3, "[" << ID << "] Updated in " << changed << " modules.");
} 由于所有子类的doModulePass函数返回值都是false,故这里的change应该不会被触发。
③最后,与doInitialization相似,调用doFinalization函数对modules做后处理,这里实际上除了CallGraphPass类对module更新了相关caller和callee映射,其它类的doFinalization什么都没做。所有子类的doFinalization都返回了false,故这里也只遍历了一轮。
//KAMain.cc
again = true;
while (again) {
again = false;
for (i = modules.begin(), e = modules.end(); i != e; ++i) {
again |= doFinalization(i->first);
}
} 综上,子类的run函数的作用就是接受一个module列表,对其中的每个module运行其对应的Pass。
2.3.2 doBasicInitialization
KAMain.cc中实现了一个独立函数doBasicInitialization:
//KAMain.cc
void doBasicInitialization(Module *M) {
// collect global object definitions
//llvm::GlobalVariable
for (GlobalVariable &G : M->globals()) {
// bool llvm::GlobalValue::hasExternalLinkage() 查找全局变量是否外部可见
if (G.hasExternalLinkage())
GlobalCtx.Gobjs[G.getName().str()] = &G;
}
// collect global function definitions
for (Function &F : *M) {
if (F.hasExternalLinkage() && !F.empty()) {
// external linkage always ends up with the function name
StringRef FNameRef = F.getName();
std::string FName = "";
if (FNameRef.startswith("__sys_"))
FName = "sys_" + FNameRef.str().substr(6);
else
FName = FNameRef.str();
GlobalCtx.Funcs[FName] = &F;
}
}
return;
} 其功能分为两个部分,将输入的module中的全局对象存储到GlobalCtx.Gobjs中,将输入modules中的全局函数存储到GlobalCtx.Funcs中。
2.3.3 main()
main函数的工作流程可以分为以下几部分:
2.3.3.1 准备工作:
- 分配堆栈资源:
//KAMain.cc -> main()
#ifdef SET_STACK_SIZE
//struct rlimit{
// rlim_t rlim_cur; //软限制
// rlim_t rlim_max; //应限制
//}
struct rlimit rl;
//getrlimit函数获取RLIMIT_STACK的当前资源限制
//RLIMIT_STACK表示最大的进程堆栈,以字节为单位
if (getrlimit(RLIMIT_STACK, &rl) == 0) {
rl.rlim_cur = SET_STACK_SIZE;
setrlimit(RLIMIT_STACK, &rl);
}
#endif 上述代码将进程的栈长度设置为预定义的SET_STACK_SIZE,以字节为单位。
- 打印stack trace:
//KAMain.cc -> main()
// Print a stack trace if we signal out.
#if LLVM_VERSION_MAJOR == 3 && LLVM_VERSION_MINOR < 9
sys::PrintStackTraceOnErrorSignal();
#else
sys::PrintStackTraceOnErrorSignal(StringRef());
#endif
PrettyStackTraceProgram X(argc, argv);
// Call llvm_shutdown() on exit.
llvm_shutdown_obj Y; 如果程序发生错误,上述代码将打印Stack Trace。
命令行选项:
KAMain.cc定义了如下命令行全局变量:
//KAMain.cc
cl::list<std::string> InputFilenames(
cl::Positional, cl::OneOrMore, cl::desc("<input bitcode files>"));
cl::opt<unsigned> VerboseLevel(
"debug-verbose", cl::desc("Print information about actions taken"),
cl::init(0));
cl::opt<std::string> DumpLocation(
"dump-location", cl::desc("dump found structures"), cl::NotHidden, cl::init(""));
cl::opt<std::string> CrashReport(
"crash-report", cl::desc("crash report"), cl::Required, cl::init(""));
cl::opt<std::string> CallGraph("call-graph", cl::desc("call graph from the report"),
cl::Required, cl::init("")); 其中,InputFilenames是一个list,包含输入的文件名称;VerboseLevel代表输出等级(具体见Common.h);DumpLocation代表dump文件存储的位置;CrashReport代表syzbot报告的位置;CallGraph代表从报告中提取的call trace文件的位置。
2.3.3.2 读取文件信息
对InputFilenames列表中的每个LLVM IR文件,需要依次对其做以下处理:
- IR File -> llvm::Module
// KAMain.cc -> main()
// Use separate LLVMContext to avoid type renaming
LLVMContext *LLVMCtx = new LLVMContext();
//来自#include <llvm/IRReader/IRReader.h>
//parseIRFile()函数接收一个bitcode文件,返回一个module
std::unique_ptr<Module> M = parseIRFile(InputFilenames[i], Err, *LLVMCtx);
if (M == NULL) {
errs() << argv[0] << ": error loading file '" << InputFilenames[i] << "'\n";
continue;
}
//std::unique_ptr智能指针相关
//release()将指针的控制权转移给外部代码
Module *Module = M.release(); std::unique_ptr是c++智能指针类型,用于对象对指针的使用权限管理,不必过于深究;这里LLVM::LLVMContext类用于多线程共享/线程独享,不必过于深究。
parseIRFile()来自llvm/IRReader/IRReader.h,其接收一个文件,判断其是否是bitcode文件,如果是则将其转化为Module。若分析失败则打印对应日志信息。
- std::string -> llvm::StringRef
// KAMain.cc -> main()
//将string复制到一个StringRef上
//string.data()返回string字符串的首地址
//strdup()用于字符串复制
StringRef MName = StringRef(strdup(InputFilenames[i].data())); 将函数名从std::string转化为llvm::StringRef,用于后续记录。
- 全局信息记录
//GlobalCtx.Modules是ModuleList类型
//ModuleList = std::vector< std::pair<llvm::Module*, llvm::StringRef>>
//lobalCtx.Modules存储[&Module,ModuleName]键值对
GlobalCtx.Modules.push_back(std::make_pair(Module, MName));
GlobalCtx.ModuleMaps[Module] = InputFilenames[i];
doBasicInitialization(Module); 将读取的Module和其名称存到GlobalCtx.Modules和GlobalCtx.ModuleMaps中,并调用doBasicInitialization函数,将Module中的全局对象存储到GlobalCtx.Gobjs中,全局函数存储到GlobalCtx.Funcs中。
完整代码如下:
// Load modules
KA_LOGS(0, "Total " << InputFilenames.size() << " file(s)");
// 遍历每个文件
for (unsigned i = 0; i < InputFilenames.size(); ++i) {
// Use separate LLVMContext to avoid type renaming
KA_LOGS(1, "[" << i << "] " << InputFilenames[i] << "");
LLVMContext *LLVMCtx = new LLVMContext();
//来自#include <llvm/IRReader/IRReader.h>
//parseIRFile()函数接收一个bitcode文件,返回一个module
std::unique_ptr<Module> M = parseIRFile(InputFilenames[i], Err, *LLVMCtx);
if (M == NULL) {
errs() << argv[0] << ": error loading file '" << InputFilenames[i] << "'\n";
continue;
}
//std::unique_ptr智能指针相关
//release()将指针的控制权转移给外部代码
Module *Module = M.release();
//将string复制到一个StringRef上
//string.data()返回string字符串的首地址
//strdup()用于字符串复制
StringRef MName = StringRef(strdup(InputFilenames[i].data()));
//GlobalCtx.Modules是ModuleList类型
//ModuleList = std::vector< std::pair<llvm::Module*, llvm::StringRef>>
//lobalCtx.Modules存储[&Module,ModuleName]键值对
GlobalCtx.Modules.push_back(std::make_pair(Module, MName));
GlobalCtx.ModuleMaps[Module] = InputFilenames[i];
doBasicInitialization(Module);
}2.3.3.3 分析CrashReport
该部分的功能是分析从syzbot爬取的报告,其目的是分析报告中是否存在可check的点:
std::ifstream report(CrashReport);
// do we find explicit check expression
bool explicity = false;
if (report.is_open()) {
//std::istreambuf_iterator 输入流缓冲区迭代器
//从指定的流缓冲区中读取字符元素
//这句代码将report从文件流转化为了一个string
std::string reportContent((std::istreambuf_iterator<char>(report)),
std::istreambuf_iterator<char>());
//如果report中有"WARNNING" 和 "invalid_op"
//代表存在可check点
if (reportContent.find("WARNING") != string::npos && reportContent.find("invalid_op") != string::npos) {
explicity = true;
}
//如果report中有"kernel BUG at"
//代表存在可check点
if (reportContent.find("kernel BUG at") != string::npos) {
explicity = true;
}
report.close();
}2.3.3.4 分析CallGraph
CallGraph就是使用get_cg.py脚本从syzbot报告中提取的call tarce,其以文本文件存储,CallGraph的每一行的组成是[函数名]+[空格]+[调用位置],例如:
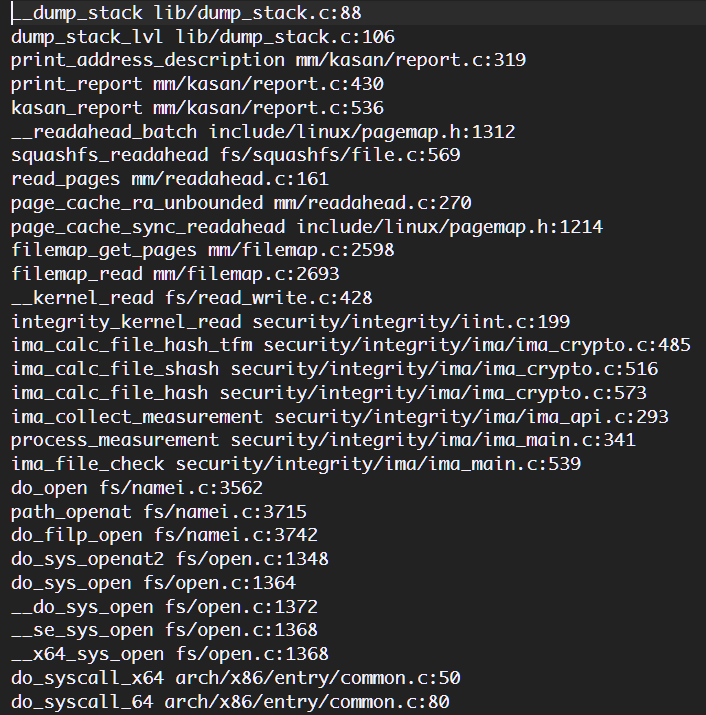
使用std::ifstream类打开文件:
std::ifstream file(CallGraph);
//用于定位Call Trace中的Crash点
std::string CrashLoc;
//用于检查是否存在KASAN报错
bool kasan_check = false;
if (file.is_open()) {
//······
file.close();
} 打开CallGraph后,逐行分析其中的每个函数是否在GlobalCtx.h中预定义的skipFunc函数集中,如果在call trace中前一个函数在skipFunc中而当前函数不在,则认为当前的函数是crash location。
if (file.is_open()) {
std::string line, curFunc;
std::string lastFunc = "";
bool skipped = true;
//读取每一行call trace
while (std::getline(file, line)) {
StringRef readin = StringRef(line);
//函数名就是CallGraph每行的第一个单词
curFunc = readin.split(" ").first.str();
/* if previous function is in the skipped function list
while current function is not, we set current function
as the crash location */
//skipFunc有哪些是GlobalCtx.h中预定义的
if (skipFunc.find(curFunc) != skipFunc.end()) {
skipped = true;
}
else {
if (skipped)
//上个函数在skipFunc中,而这个不在
CrashLoc = line;
skipped = false;
}
// 检查是否存在KASAN报错
if (curFunc.find("kasan_check_") != string::npos) {
kasan_check = true;
}
if (lastFunc != "") {
KA_LOGS(0, "inserting " << lastFunc << " " << curFunc);
//std::map<string, string>
//记录调用关系
GlobalCtx.CallGraph[lastFunc] = curFunc;
}
lastFunc = curFunc;
}
file.close();
} 在遍历CallGraph的过程中,会将函数的调用关系记录到 GlobalCtx.CallGraph中。
2.3.3.5 运行Pass && Dump
接下来对GlobalCtx.Modules中存储的所有Module调用CallGraphPass和PointerAnalysisPass:
//调用CallGraphPass
CallGraphPass CGPass(&GlobalCtx);
CGPass.run(GlobalCtx.Modules);
//调用PointerAnalysisPass
PointerAnalysisPass PAPass(&GlobalCtx);
PAPass.run(GlobalCtx.Modules); 如果前文的分析过程中存在Crash check point,则调用CrashAnalyzer Pass:
assert(CrashLoc != "");{
//调用CrashAnalyzePass
CrashAnalyzer CA(&GlobalCtx, explicity, CrashLoc);
CA.run(GlobalCtx.Modules);
// test_bit include/asm-generic/bitops/instrumented-non-atomic.h:110
if (DumpLocation != "")
CA.dump(DumpLocation);
else
CA.dump();
} 这是整个代码的核心部分,具体Pass的分析过程见后文。
2.4 CallGraphPass
2.4.1 C/C++特殊函数调用
**CallGraphPass的目的是构建文件的CallGraph,并将相关调用信息存储到Ctx全局变量中。**在进行具体代码分析前,首先来关注一下C语言中函数的特殊调用问题。
2.4.1.1 间接调用(indirect call)
C中的间接调用一般是指通过函数指针调用函数:
//directCall_test.c
#include <stdio.h>
void foo() { printf("function foo\n"); }
int main(int argc, char **argv){
foo();
return 0;
}//IndirectCall_test.c
#include <stdio.h>
void foo() { printf("function foo\n"); }
int main(int argc, char **argv){
void (*fp)() = foo;
fp();
return 0;
} 将其编译为ll文件如下:
//directCall_test.ll
; Function Attrs: noinline nounwind optnone uwtable
define dso_local void @foo() #0 {
%1 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([14 x i8], [14 x i8]* @.str, i64 0, i64 0))
ret void
}
declare dso_local i32 @printf(i8*, ...) #1
; Function Attrs: noinline nounwind optnone uwtable
define dso_local i32 @main() #0 {
%1 = alloca i32, align 4
store i32 0, i32* %1, align 4
call void @foo()
ret i32 0
}//IndirectCall_test.ll
; Function Attrs: noinline nounwind optnone uwtable
define dso_local void @foo() #0 {
%1 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([14 x i8], [14 x i8]* @.str, i64 0, i64 0))
ret void
}
declare dso_local i32 @printf(i8*, ...) #1
; Function Attrs: noinline nounwind optnone uwtable
define dso_local i32 @main() #0 {
%1 = alloca i32, align 4
%2 = alloca void (...)*, align 8
store i32 0, i32* %1, align 4
store void (...)* bitcast (void ()* @foo to void (...)*), void (...)** %2, align 8
%3 = load void (...)*, void (...)** %2, align 8
call void (...) %3()
ret i32 0
} 可以看到,直接调用指令的操作数就是确定Callee的地址(foo),但是间接调其操作数是一个虚拟寄存器%3(在汇编中就是一个确定的寄存器)。故当Pass分析到call语句时没有办法直接得出目标函数的地址,因为寄存器中的值可能是直接载入的确定的地址,也可能是其它地方载入的值。换句话说,直接调用语句可以确定call语句调用的foo函数,但是间接调用语句不能,因为调用什么函数取决于%3内加载了什么值。
在以上例子中,我们当然可以轻松看出间接调用的就是foo函数的地址,但是万一间接调用的地址取决于用户的输入/程序运行时的具体状态/读取的文件信息等,代码的分支情况就复杂了起来。在C++中的虚函数调用就是通过间接调用完成的,这也是其多态的基础。
2.4.1.2 内联汇编语句
内联汇编语言(或“inline asm”)是一些编程语言中的一项功能,允许在代码中直接包含汇编语言指令。在需要执行无法使用高级语言结构有效或清晰表达的特定操作时,使用内联汇编可能会很有用。例如,可以使用内联汇编访问硬件设备或优化性能关键的代码段。
内联汇编语句中可以包含调用指令,例如:
#include <stdio.h>
int main() {
int x = 10;
int y;
// 使用内联汇编语言调用一个汇编语言函数
__asm__("movl %1, %%eax; call assembly_function; movl %%eax, %0;" : "=r"(y) : "r"(x));
printf("The result is: %d\n", y);
return 0;
}
// 汇编函数用于将输入参数加5并返回结果
__asm__(
"assembly_function:\n"
"addl $5, %eax\n"
"ret\n"
); 上述代码使用内联汇编语言调用一个在汇编语言中定义的函数assembly_function。该函数接受一个输入参数,将其加5,然后返回结果。将其转化为LLVM IR如下:
define dso_local i32 @main() #0 {
%1 = alloca i32, align 4
%2 = alloca i32, align 4
%3 = alloca i32, align 4
store i32 0, i32* %1, align 4
store i32 10, i32* %2, align 4
%4 = load i32, i32* %2, align 4
%5 = call i32 asm "movl $1, %eax; call assembly_function; movl %eax, $0;", "=r,r,~{dirflag},~{fpsr},~{flags}"(i32 %4) #2, !srcloc !2
store i32 %5, i32* %3, align 4
%6 = load i32, i32* %3, align 4
%7 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([19 x i8], [19 x i8]* @.str, i64 0, i64 0), i32 %6)
ret i32 0
} 可见其使用call i32 asm语句直接调用汇编,并不对其处理。CallGraphPass跳过了对内联汇编函数调用语句的分析。
2.4.1.3 Intrinsic函数
Intrinsic函数是编译器内建的函数,由编译器提供,类似于内联函数。在LLVM中,Intrinsic函数一般是在IR级代码优化时引入的,也就是由前端产生。也可以在程序代码中写Intrinsic函数,并通过前端直接发射。这些函数名的前缀一般是保留字“llvm.”。LLVM后端选择用最高效的形式将Intrinsic函数转换给硬件执行,可以将Intrinsic函数拆分为一系列机器指令,也可以映射为单独一条机器指令,并直接调用相应的硬件功能。
这里CallGraphPass跳过了Intrinsic函数的调用分析,其与内核并无关系,是LLVM引入的。Intrinsic名必须全部以“ llvm”开头前缀。
2.4.2 代码分析
CallGraph的Pass执行代码如下:
//CallGraph.cc
bool CallGraphPass::doModulePass(Module *M) {
bool Changed = true, ret = false;
while (Changed) {
Changed = false;
//遍历Module中每个Function
for (Function &F : *M)
//对每个Function操作
Changed |= runOnFunction(&F);
ret |= Changed;
}
return ret;
} 进入函数CallGraph::runOnFunction:
//CallGraph.cc -> runOnFunction()
//llvm::GlobalObject -> hasSection(): Check if this global has a custom object file section.
//llvm::GlobalObject -> getSection(): Get the custom section of this global if it has one.
if(F->hasSection() && F->getSection().str() == ".init.text")
return false; 首先排除了初始化函数。在C代码中,使用__init宏声明的函数会在编译时将函数放在”.init.text”这个代码区中。标记为初始化的函数,表明该函数供在初始化期间使用。在模块装载之后,模块装载就会将初始化函数扔掉。这样可以将该函数占用的内存释放出来。
这里,程序通过使用inst_iterator直接遍历函数里的每条指令:
//CallGraph.cc -> runOnFunction()
bool Changed = false;
for (inst_iterator i = inst_begin(F), e = inst_end(F); i != e; ++i) {
//......
} 对于每条指令,可能与inst_iterator的指针重载有关,需要重新取址获取指向每条指令的地址[LLVM开发者手册]。接着,排除了asm内联调用和intrinsic调用:
////CallGraph.cc -> runOnFunction()
//获取指向指令引用的指针
Instruction *I = &*i;
// map callsite to possible callees
// dyn_cast检查指针I是否是CallInst类型
if (CallInst *CI = dyn_cast<CallInst>(I)) {
// ignore inline asm or intrinsic calls
if (CI->isInlineAsm() || (CI->getCalledFunction()
&& CI->getCalledFunction()->isIntrinsic()))
continue; 接下来需要获取该CallInst的Callee,即该指令调用的函数。对于直接调用,使用CI->getCalledFunction()即可;对于间接调用,由于其调用存在多种情况,需要具体分析:
// CallGraph.cc -> runOnFunction()
// might be an indirect call, find all possible callees
FuncSet &FS = Ctx->Callees[CI];
if (!findCallees(CI, FS))
continue; findCallees()函数流程如下:
// CallGraph.cc -> findCallees()
// typedef llvm::SmallPtrSet<llvm::Function*, 32> FuncSet;
bool CallGraphPass::findCallees(CallInst *CI, FuncSet &FS) {
Function *CF = CI->getCalledFunction();
// real function, S = S + {F}
if (CF) {
// prefer the real definition to declarations
// 获取函数定义
CF = getFuncDef(CF);
return FS.insert(CF).second;
}
//......
} CI->getCalledFunction()函数用于获取直接调用call指令的callee地址,若其是一个间接调用/非调用指令则返回nullptr。如果返回不为nullptr,则进入以下调用过程:
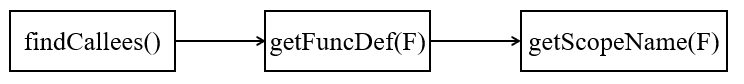
getFuncDef()过程如下:
// CallGraph.cc -> getFuncDef()
Function* CallGraphPass::getFuncDef(Function *F) {
// typedef std::unordered_map<std::string, llvm::Function*> FuncMap
FuncMap::iterator it = Ctx->Funcs.find(getScopeName(F));
if (it != Ctx->Funcs.end())
return it->second;
else
return F;
} getScopeName()过程如下:
// Annotation.h -> getScopeName()
static inline std::string getScopeName(const llvm::GlobalValue *GV) {
if (llvm::GlobalValue::isExternalLinkage(GV->getLinkage()))
return GV->getName().str();
else {
llvm::StringRef moduleName = llvm::sys::path::stem(
GV->getParent()->getModuleIdentifier());
return "_" + moduleName.str() + "." + GV->getName().str();
}
} 其中,llvm::GlobalValue类是llvm::Function类的父类llvm::GlobalObject的父类:
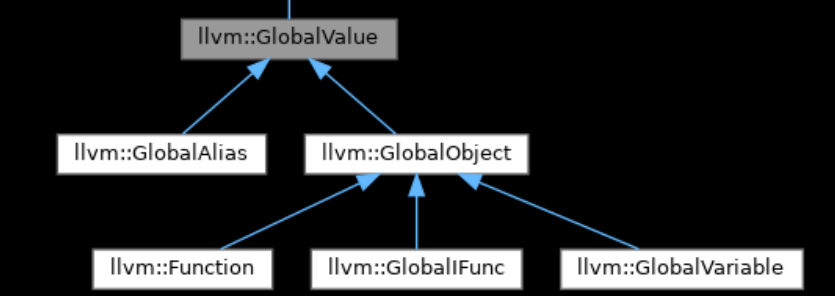
getScopeName()的作用是检查一个函数是否为全局函数(extern),如果是则直接返回其函数名,如果不是则查找该函数所属的Module,构建“_{ModuleName}.{FuncName}”字符串并返回。
回到getFuncDef()函数,其功能是在Ctx->Funcs中查找函数的定义,如果其在Ctx->Funcs中存在则返回Ctx->Funcs中的函数指针,否则返回输入的函数指针F本身。
回到findCallees()函数,如果输入的指令CI是一个直接调用,则获取其Callee函数指针CF,并调用getFuncDef()在Ctx->Funcs中查找并返回函数的定义。然后将指针插入FuncSet FS中,如果第一次插入则返回true,否则返回false。因为CF这里传入的是Ctx->Callees[CI],返回false就代表查找到的调用关系(CI->CF)已经存在。
如果findCallees()函数中CI指令并不是直接调用,则将其插入到Ctx->IndirectCallInst中:
// CallGraph.cc -> findCallees()
// save called values for point-to analysis
Ctx->IndirectCallInsts.push_back(CI);
#ifdef TYPE_BASED
// use type matching to concervatively find
// possible targets of indirect call
return findCalleesByType(CI, FS);
#else
// use assignments based approach to find possible targets
// const Value* llvm::CallInst::getCalledValue()
// getCalledValue() - Get a pointer to the function that is invoked by this instruction.
return findFunctions(CI->getCalledValue(), FS);
#endif 接下来,调用findFunctions查找其所有可能的Callee,并存储到Ctx->Callees[Ins]中,具体细节这里不再展开。
至此,已经找到了当前Call指令的所有Callee,接下来分析callInst指令的所有参数,找到其可能存在的函数指针参数并分析其所有函数指针的Callee,将其存储到Ctx->FuncPtrs[Id]中:
//CallGraph.cc -> runOnFunction()
#ifndef TYPE_BASED
// looking for function pointer arguments
// CI->getNumArgOperands():
// Return the number of invoke arguments
for (unsigned no = 0, ne = CI->getNumArgOperands(); no != ne; ++no) {
// CI->getArgOperand(no)
// Return the i-th invoke argument.
Value *V = CI->getArgOperand(no);
if (!isFunctionPointerOrVoid(V->getType()))
continue;
// find all possible assignments to the argument
FuncSet VS;
if (!findFunctions(V, VS))
continue;
// update argument FP-set for possible callees
for (Function *CF : FS) {
if (!CF) {
WARNING("NULL Function " << *CI << "\n");
assert(0);
}
std::string Id = getArgId(CF, no);
Changed |= mergeFuncSet(Ctx->FuncPtrs[Id], VS);
}
}
#endif 如果I不是CallInst指令,而是StoreInst类型指令,则:
//CallGraph.cc -> runOnFunction()
#ifndef TYPE_BASED
if (StoreInst *SI = dyn_cast<StoreInst>(I)) {
// stores to function pointers
Value *V = SI->getValueOperand();
if (isFunctionPointerOrVoid(V->getType())) {
std::string Id = getStoreId(SI);
if (!Id.empty()) {
FuncSet FS;
findFunctions(V, FS);
Changed |= mergeFuncSet(Id, FS, isFunctionPointer(V->getType()));
} else {
// errs() << "Empty StoreID: " << F->getName() << "::" << *SI << "\n";
}
}
} else if (ReturnInst *RI = dyn_cast<ReturnInst>(I)) {
// function returns
if (isFunctionPointerOrVoid(F->getReturnType())) {
Value *V = RI->getReturnValue();
std::string Id = getRetId(F);
FuncSet FS;
findFunctions(V, FS);
Changed |= mergeFuncSet(Id, FS, isFunctionPointer(V->getType()));
}
}
#endif 如果一个StoreInst类型指令,并且其操作数是函数指针,则获取其函数指针所有可能的Callee并存储到Ctx->FuncPtrs[]中。
在runOnFunction函数执行完毕后,其run函数调用CallGraphPass::doFinalization对每个Module进行善后处理:
//CallGraph.cc -> doFinalization()
bool CallGraphPass::doFinalization(Module *M) {
// update callee and caller mapping
// 遍历每个函数
for (Function &F : *M) {
//遍历每条指令
for (inst_iterator i = inst_begin(F), e = inst_end(F); i != e; ++i) {
// map callsite to possible callees
// 如果该指令是CallInst类型
// 根据之前存储的Callees,反向计算Callers
if (CallInst *CI = dyn_cast<CallInst>(&*i)) {
FuncSet &FS = Ctx->Callees[CI];
// calculate the caller info here
for (Function *CF : FS) {
CallInstSet &CIS = Ctx->Callers[CF];
CIS.insert(CI);
}
}
}
}
return false;
} 至此,CallGraphPass分析完毕。
2.5 PointerAnalysisPass
2.5.1 Alias Analysis
Alias Analysis/Pointer Analysis是一类试图确定两个指针是否可以指向内存中同一个对象的技术[LLVM Alias Analysis Infrastructure — LLVM 17.0.0]。
Alias Analysis(别名分析)是编译器理论中的一种技术,用于确定存储位置是否可以以多种方式访问。如果两个指针指向相同的位置,则称这两个指针为别名。 但是,它不能与Pointer Analysis(指针分析)混淆,指针分析解决的问题是一个指针可能指向哪些对象或者指向哪些地址,而别名分析解决的是两个指针指向的是否是同一个对象。指针分析和别名分析通常通过静态代码分析来实现。
别名分析在编译器理论中非常重要,在代码优化和安全方面有着非常广泛且重要的应用。编译器级优化需要指针别名信息来执行死代码消除(删除不影响程序结果的代码)、冗余加载/存储指令消除、指令调度(重排列指令)等。编译器级别的程序安全使用别名分析来检测内存泄漏和内存相关的安全漏洞。
2.5.2 代码分析
定义相关数据结构:
//GlobalCtx.h
typedef DenseMap<Value *, SmallPtrSet<Value *, 16>> PointerAnalysisMap;
typedef unordered_map<Function *, PointerAnalysisMap> FuncPointerAnalysisMap;
typedef unordered_map<Function *, AAResults *> FuncAAResultsMap; 分析代码:
//PointerAnalysis.cc
bool PointerAnalysisPass::doModulePass(Module *M) {
//llvm::legacy::FunctionPassManager是旧版的Pass Manager
legacy::FunctionPassManager *FPasses = new legacy::FunctionPassManager(M);
AAResultsWrapperPass *AARPass = new AAResultsWrapperPass();
FPasses->add(AARPass);
//return false
FPasses->doInitialization();
for (Function &F : *M) {
//如果该函数的定义在Module之外
if (F.isDeclaration())
continue;
FPasses->run(F);
}
FPasses->doFinalization();
AAResults &AAR = AARPass->getAAResults();
for (Module::iterator f = M->begin(), fe = M->end();
f != fe; ++f) {
Function* F = &*f;
PointerAnalysisMap aliasPtrs;
if (F->empty())
continue;
detectAliasPointers(F, AAR, aliasPtrs);
Ctx->FuncPAResults[F] = aliasPtrs;
Ctx->FuncAAResults[F] = &AAR;
}
return false;
} 其使用legacy::FunctionPassManager创建了一个旧版的Function Pass Manager,并将Pointer Analysis分析Pass AAResultsWrapperPass添加进去。
接下来使用(Function &F : *M)语句遍历Module中的每个函数,如果该函数F的定义不在Module之外,则运行AAResultsWrapperPass,并通过AAResult结构获取分析结果。
接下来再次遍历Module中的每个Function,对其调用函数detectAliasPointers:
//PointerAnalysis.cc
void PointerAnalysisPass::detectAliasPointers(Function* F, AAResults &AAR,
PointerAnalysisMap &aliasPtrs) {
std::set<Value *> addr1Set;
std::set<Value *> addr2Set;
Value *Addr1, *Addr2;
//获取所有指针类型
for (Argument &A : F->args())
if (A.getType()->isPointerTy())
addr1Set.insert(&A);
for (Instruction &I : instructions(*F))
if (I.getType()->isPointerTy())
addr1Set.insert(&I);
//why??
if (addr1Set.size() > 1000) {
return;
}
for (auto Addr1 : addr1Set) {
for (auto Addr2 : addr1Set) {
//只分析不同的指针对
if (Addr1 == Addr2)
continue;
//用于从总的分析结果里获取单对指针分析结果
AliasResult AResult = AAR.alias(Addr1, Addr2);
bool notAlias = true;
if (AResult == MustAlias || AResult == PartialAlias) {
notAlias = false;
//只要确定的
} else if (AResult == MayAlias) {
}
if (notAlias)
continue;
//如果存在alias
auto as = aliasPtrs.find(Addr1);
if (as == aliasPtrs.end()) {
SmallPtrSet<Value *, 16> sv;
sv.insert(Addr2);
aliasPtrs[Addr1] = sv;
} else {
as->second.insert(Addr2);
}
}
}
} detectAliasPointers()对每个输入的函数,首先用循环将其指针类参数和指针类指令都存储到集合addr1Set中,并且如果addr1Set存储的指针数量大于100则直接返回,不做分析(为什么?)。
接下来对addr1Set内的所有指针两两分析,使用AAResult.alias()函数获取两个指针的分析结果AResult,如果AResult为MustAlias/PartialAlias则将这个指针对存储到aliasPtrs中。
在detectAliasPointers()分析完后,将其Ailas分析结果存储到Ctx->FuncPAResults[F]中,将整个AAResultsWrapperPass的分析结果存储到Ctx->FuncAAResults[F]中,至此,PointerAnalysisPass分析完毕。
2.6 CrashAnalyzer
CrashAnalyzer用于确定反向污点分析的source。
在CrashAnalyzer.h中定义了CrashAnalyzer的构造函数:
//CrashAnalyzer.h
public:
//构造函数
CrashAnalyzer(GlobalContext *Ctx_, bool cond_,
/*llvm::StringRef fn,
llvm::StringRef Sourcef_, unsigned l*/
llvm::StringRef CrashLoc
)
: IterativeModulePass(Ctx_, "CrashAnalyzer") {
cond = cond_;
// KA_LOGS(0, "crash loc : " << CrashLoc << "\n");
funcName = CrashLoc.split(" ").first;
auto loc = CrashLoc.split(" ").second;
source = loc.split(":").first;
line = stoi(loc.split(":").second.str());
// KA_LOGS(0, "parsed loc: " << funcName << "\n");
// KA_LOGS(0, "source : " << source << "\n");
// KA_LOGS(0, "Line: " << line << "\n");
analyzed = false;
Ctx->InstNum = 0;
} 其继承了父类IterativeModulePass的构造函数,将Ctx设置为Ctx_,ID设置为“CrashAnalyzer”。接下来,设置cond(就是KAMain.cc中的explicity,用于表明是否在report中找到了显式可check点),并将CrashLoc中的函数名称与位置信息提取出来,分别赋值给变量funcName、loc、 source、line。最后将Ctx->InstNum设置为0。
CrashAnalyzer::doModulePass对每个函数运行CrashAnalyzer::runOnFunction :
//CrashAnalyzer.cc
bool CrashAnalyzer::doModulePass(Module* M) {
// some functions are defined in headers
// if (moduleName.str() != M->getSourceFileName())
// return false;
for (Function &F : *M)
runOnFunction(&F);
return false;
} CrashAnalyzer::runOnFunction()会定位之前在KAMain.cc中定位的CrashLoc中的函数以及crash位置,并遍历该函数的每条指令:
//确定source
void CrashAnalyzer::runOnFunction(Function *F) {
//只对carsh函数做分析
if (funcName != F->getName() || analyzed)
return;
//遍历每条指令
for (inst_iterator i = inst_begin(F), e = inst_end(F); i != e; i++) {
Instruction* I = &*i;
//DILocation metadata node provides information
//such as the file name, line number,
//and column number of the source code location
//corresponding to a particular instruction or operation in the IR
DILocation* Loc = I->getDebugLoc();
if (Loc == nullptr) {
continue;
}
/* remove "./" for header files */
StringRef sourceF = Loc->getScope()->getFilename();
if (sourceF.startswith("./")) {
sourceF = sourceF.split("./").second;
}
if (line == Loc->getLine() && sourceF == source) {
//显式/隐式定位source
//......
}
}//end of for
}//end of runOnFunction() 由上述代码可知,定位到call trace中的crash函数后,代码根据LLVM IR的debug信息来定位LLVM指令对应源代码的行数,以此定位到report中的crash行,例如对如下call trace:
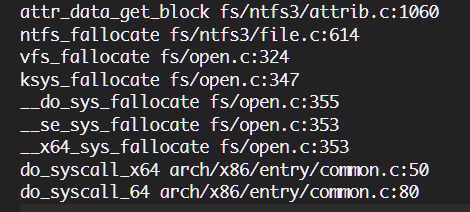
根据函数名来定位Module内的Crash函数,根据对应文件标志的代码行数来定位相关crash指令(遍历每个指令,根据metaData提供的debug信息查看指令对应的源码行数)。
2.6.1 Implicit Checking
**CrashAnalyzer::runOnFunction()根据cond参数决定以显式/隐式的方式定位反向污点分析的source(即导致程序crash的指令)。**当cond为false时,执行隐式检查(Implicit Checking):
//CrashAnalyzer.cc -> runOnFunction()
//Implicit Checking
//如果没有可以明确check的点
//则分析隐式Crash指令
if (!cond) {
//isa<> 与 java中的instanceof用法一致
//用于测试I是否是LoadInst/StoreInst类型
//是则返回true,否则返回false
if (isa<LoadInst>(I) || isa<StoreInst>(I)) {
Ctx->TaintSrc.insert(I);
Ctx->InstNum ++;
}
//如果是Call指令
else if (isa<CallInst>(I)) {
Function *F = cast<CallInst>(I)->getCalledFunction();
//如果不是直接调用指令则直接返回
if (F == nullptr) {
KA_WARNS(0, "Fail to find Function from the CallInst "<<*I);
continue;
}
StringRef Fname = F->getName();
/* since we skip some debugging functions in the first step
let's taint starting from these functions' argument */
//若Callee是skipFunc,则该Call指令作为source
if (skipFunc.find(Fname) != skipFunc.end()) {
Ctx->TaintSrc.insert(I);
//若Callee函数名包含"__write_once_size"
//获取Call指令的第一个参数作为source
} else if (Fname.find("__write_once_size") != string::npos) {
Ctx->TaintSrc.insert(cast<CallInst>(I)->getArgOperand(0));
}else {
KA_WARNS(0, "Unknown call here "<<*I);
}
}
//既不是存储/加载指令,也不是call指令,放弃
else {
KA_LOGS(1, "Unknown Inst here "<<*I);
}
}//end of implicit checking
//explicit checking
else{
//...
} 对于implicit checking:
1) 若定位的指令是LoadInst/StoreInst类型:
直接将此指令作为source。
2) 若定位的指令是CallInst类型:
若该Call不是直接调用则直接丢弃;否则若其Callee是skipFunc,直接将该指令作为source;或者其Callee函数名包含“__write_once_size”,将该Call指令的第一个操作数作为source。
3) 若以上二者都不是:
丢弃。
2.6.2 Explicit Checking
当cond为ture时,执行显式检查(Explicit Checking)。对于显式检查,GREBE文章中的定义是有明确错误检查功能的预定义宏(如WARN_ON和BUG_ON)、辅助函数等,其共性是在代码中直接进行检查,故代码中只分析CallInst类型指令:
//CrashAnalyzer.cc -> runOnFunction()
//explicit checking
else{
if (isa<CallInst>(I)) {
CallInst *CI = cast<CallInst>(I);
//获取直接调用子函数
Function *F = CI->getCalledFunction();
StringRef Fname = ""; // if calling asm
if (F != nullptr) {
Fname = F->getName();
}
//......
}
{ 针对不同的调用情况,其具体处理如下:
/* handle ODEBUG and DEBUG_OBJECTS_FREE.
* which generate warns using "implicit"
* checkings
*/
if (Fname.find("init_work") != string::npos ||
Fname.find("print_unlock_imbalance_bug") != string::npos ||
Fname.find("debug_print_object") != string::npos ||
Fname.find("debug_object_init") != string::npos ||
Fname.find("debug_assert_init") != string::npos ||
/* DEBUG_OBJECTS_FREE */
Fname.find("debug_check_no_obj_freed") != string::npos) {
Ctx->TaintSrc.insert(I);
} 对于子函数名中存在“printk”/内联汇编调用的,进行如下处理:
//定位指令属于的BB
BasicBlock *BB = CI->getParent();
KA_LOGS(2, "Found BB : "<<*BB);
KA_LOGS(2, "terminator : "<<*BB->getTerminator());
Value *condV;
bool warnOnce = false; 接着进行如下处理:
while (BB->getSinglePredecessor()) {
//Predecessor,前身,指在控制流中一个基本块的上一个块
BasicBlock *newBB = BB->getSinglePredecessor();
/* heuristic: if sotring true to `refcount_inc_checked.__warned`
* exists in the skipped BB, there should exist an redundant
* checking for the `refcount_inc_checked.__warned` */
//遍历基本块中的每条指令
for (Instruction &BBInst : *BB) {
//如果是StoreInst类型
if (isa<StoreInst>(&BBInst)) {
StoreInst *SI = cast<StoreInst>(&BBInst);
//如果StoreInst指令的第一个参数为常数
//&& 第二个参数为全局变量
if (isa<ConstantInt>(SI->getOperand(0))
&& isa<GlobalVariable>(SI->getOperand(1))) {
//获取第二个参数的名称
StringRef GVName = cast<GlobalVariable>(SI->getOperand(1))->getName();
KA_LOGS(0, "Found Global Value: "<<GVName);
//如果全局变量名称包含“__warned”
//并且子函数F存在(直接调用)
//并且子函数名称包含“__warn_printk”
if (GVName.find("__warned") != string::npos &&
F && F->getName().find("__warn_printk") != string::npos) {
KA_LOGS(0, "Warn ONCE checking here....");
warnOnce = true;
}
}
}
}
//如果是BranchInst类型
if (isa<BranchInst>(newBB->getTerminator())) {
//getTerminator()获取基本块的终止指令,例如分支指令br,ret等
//如果Predecessor块中的终止指令是BranchInst类型
BranchInst *BI = cast<BranchInst>(newBB->getTerminator());
//检查该br指令是否是条件跳转,isConditional()
//isConditional()返回true/false
if (BI->isConditional()) {
KA_LOGS(0, "Found first condition : "<<*BI->getCondition());
condV = BI->getCondition();
break;
}
}
//如果父块的终止指令不是conditional br,则继续向上寻找
BB = newBB;
KA_LOGS(1, "Skipping BB: "<<*BB); 如果指令的父基本块的终止指令是一个contional br并且指令所在的基本块不存在上述的warn调用,则将condition指令设置为污点源source:
/*
* if we find a condition value and the logging is not WARN_ONCE,
* we mark the condition value as taint source and continue.
* */
if (condV && !warnOnce ) {
Ctx->TaintSrc.insert(condV);
continue;
} 接下来进行广度优先搜索:
// null the condition
Value *SecondCondV = nullptr;
// breadth first search
std::vector<BasicBlock *> BBVec;
std::set<BasicBlock *> BBSet;
BBVec.push_back(BB);
//......while (!BBVec.empty() && !SecondCondV) {
BB = BBVec.back();
BBVec.pop_back();
// cyclic basic block
if (!BBSet.insert(BB).second) {
continue;
}
if (!BB->hasNPredecessorsOrMore(1)) {
/* no predecessor, let's find find its parents */
//getParent()用于获取当前基本块所在函数
auto fName = BB->getParent()->getName();
//如果该函数在report报告的Call trace中
if (Ctx->CallGraph.find(fName) != Ctx->CallGraph.end()) {
auto callerName = Ctx->CallGraph[fName];
for (auto M : Ctx->Callers) {
if (M.first->getName().endswith(fName)) {
auto CISet = M.second;
for (CallInst *caller : CISet) {
//根据调用图找到parent
if (caller->getFunction()->getName()
== callerName) {
BB = caller->getParent();
KA_LOGS(0, "Backwarding to its parent "<<callerName);
break;
}
}
}
}
}
}
//遍历其predecessors
for (BasicBlock *Pred : predecessors(BB)) {
KA_LOGS(1, "Found pre : "<<*Pred);
BBVec.push_back(Pred);
if (isa<BranchInst>(Pred->getTerminator())) {
BranchInst *BI = cast<BranchInst>(Pred->getTerminator());
if (BI->isConditional()
&& condV != BI->getCondition()) {
SecondCondV = BI->getCondition();
assert(SecondCondV);
KA_LOGS(0, "Found 1st condition : "<<*condV);
KA_LOGS(0, "Found 2nd condition : "<<*SecondCondV);
break;
}
}
}
}if (SecondCondV) {
Ctx->TaintSrc.insert(SecondCondV);
continue;
} 这里具体为什么要这么做还需深入探索。
2.7 Backward Taint Analysis
污点分析过程存储在StructFinderPass::doAnalyze()中:
// StructFinder.cc -> doAnalyze()
// v是污点源
void StructFinderPass::doAnalyze(Value *v) {
VSet vs;
vs.clear();
// 将污点分析的结果存储到全局变量Ctx->CriticalSt中
mergeSet(Ctx->CriticalSt, taintAnalysis(v, vs, false));
}
// StructFinderPass -> mergeSet()
static void mergeSet(std::set<llvm::StringRef> &a, std::set<llvm::StringRef> b) {
a.insert(b.begin(), b.end());
} 接下来进入正式的污点分析过程StructFinderPass::taintAnalysis,首先遍历污点源的用户指令,对其中的Cast指令进行处理:
//StructFinder.cc -> taintAnalysis()
std::set<llvm::StringRef> result;
//每个污点源单独一个result
result.clear();
if (!vs.insert(V).second) {
return result;
}
// debuging!!! remove this when deploying blockset
// found = false;
KA_LOGV(0, V);
// find the casting...
// V->users()获取污点源的用户指令
for (auto *user : V->users()) {
//BitCastInst类型是LLVM的数据类型转换指令
//其转换数据格式但不改变其存储方式
//例如:
//%ptr = alloca i32*
//%casted_ptr = bitcast i32** %ptr to i8**
if (isa<BitCastInst>(user)) {
BitCastInst *BCI = dyn_cast<BitCastInst>(user);
// getDestTy = get distination type
Type *dst = BCI->getDestTy();
// *Type -> StringRef
auto name = handleType(dst);
KA_LOGS(0, "Found "<<name<<" in casting");
addToSet(result, name);
}
} 可见,只要污点源的用户指令是BitCastInst类型,就将该指令的DestType的名称加入result中。
接下来,对污点源本身分为三类:Instruction、Argument与GlobalVaribal,三类污点源分别进行不同的处理。无需赘述,Instruction类型就是指令类型;Argument类型用于描述函数声明,GlobalVaribal表示全局变量。
0. StructFinderPass::handleType
handleType()函数用于获取struct/int的名称,如果传入的type是指针或数组则递归查找其指向类型。
StringRef StructFinderPass::handleType(Type *ty) {
if (ty == nullptr)
return StringRef("");
if (ty->isStructTy()) {
StructType *ST = dyn_cast<StructType>(ty);
StringRef stname = ST->getName();
//如果该结构以struct.为首,
//并且不是匿名结构
if (stname.startswith("struct.")
&& !stname.startswith("struct.anon"))
return stname;
} else if (ty->isPointerTy()){
ty = cast<PointerType>(ty)->getElementType();
return handleType(ty);
} else if (ty->isArrayTy()){
ty = cast<ArrayType>(ty)->getElementType();
return handleType(ty);
} else if (ty->isIntegerTy()) {
return StringRef("int");
}
return StringRef("");
}1. Instruction类型source:
针对不同类型的Insturction再分别处理.
1.1 Instruction::Store:
- 在LLVM IR中,store指令的格式如下:
%value = ...
%ptr = ...
store <type1> %value, <type2>* %ptr 其表明将type1格式的value存入type2格式的指针ptr所指向的内存中。type1与type2必须相同或者兼容。
- 在LLVM IR中,getelementptr指令的格式如下:
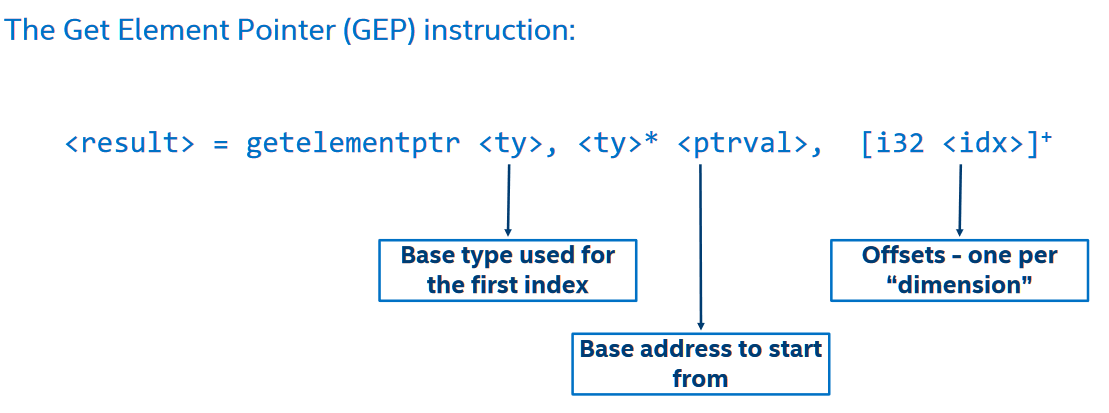
%array = alloca [10 x i32]
%element_ptr = getelementptr [10 x i32], [10 x i32]* %array, i32 0, i32 3 其用于计算结构中某个元素的指针,C语言中所有对数组/结构体的取值操作都会被翻译为getelementptr。
- 在LLVM IR中,load/store指令经常与getelementptr指令一起使用,用于表示对数组/结构体的赋值操作,例如:
%arr = alloca [10 x i32]
%x = load i32, i32* getelementptr inbounds ([10 x i32], [10 x i32]* %arr, i64 0, i64 3)%arr = alloca [10 x i32]
%3 = getelementptr inbounds [10 x i32], [10 x i32]* %arr, i64 0, i64 3
store i32 7, i32* %3 上述两个代码块分别表示从数组中取值和为数组某个成员赋值。
针对store指令的分析过程如下:
// StructFinder.cc -> taintAnalysis()
// if (auto *I = dyn_cast<Instruction>(V))
// I->getOpcode() == Instruction::Store:
case Instruction::Store:{
StoreInst *SI = cast<StoreInst>(I);
//获取指针类型
Type *SType = SI->getPointerOperandType();
//*Type -> StringRef
StringRef stName = handleType(SType);
//如果该指针类型已经在该source的result中了则跳过分析
if (!addToSet(result, stName)) {
break;
}
// would find a GetElementType
if (!isa<GetElementPtrInst>(SI->getOperand(0))) {
// assert(0 && "didn't find a GetElementPtrInst before StoreInst");
}
Value *GetV = SI->getOperand(1);
// we skip these getElement since they are nested
while (isa<GetElementPtrInst>(GetV)) {
GetElementPtrInst *GEI = cast<GetElementPtrInst>(GetV);
//getSourceElementType()获取取值操作的原地址
//hanleType获取类型名称,例如结构的名称
StringRef name = handleType(GEI->getSourceElementType());
//如果该结构已经处理则跳过
if (!addToSet(result, name)) {
break;
}
//继续递归,向上寻找其操作指针
GetV = GEI->getOperand(0);
}
// the outside GetElementPtrInst
// 处理最后的的GteV
mergeSet(result, taintAnalysis(GetV, vs, found));
break;
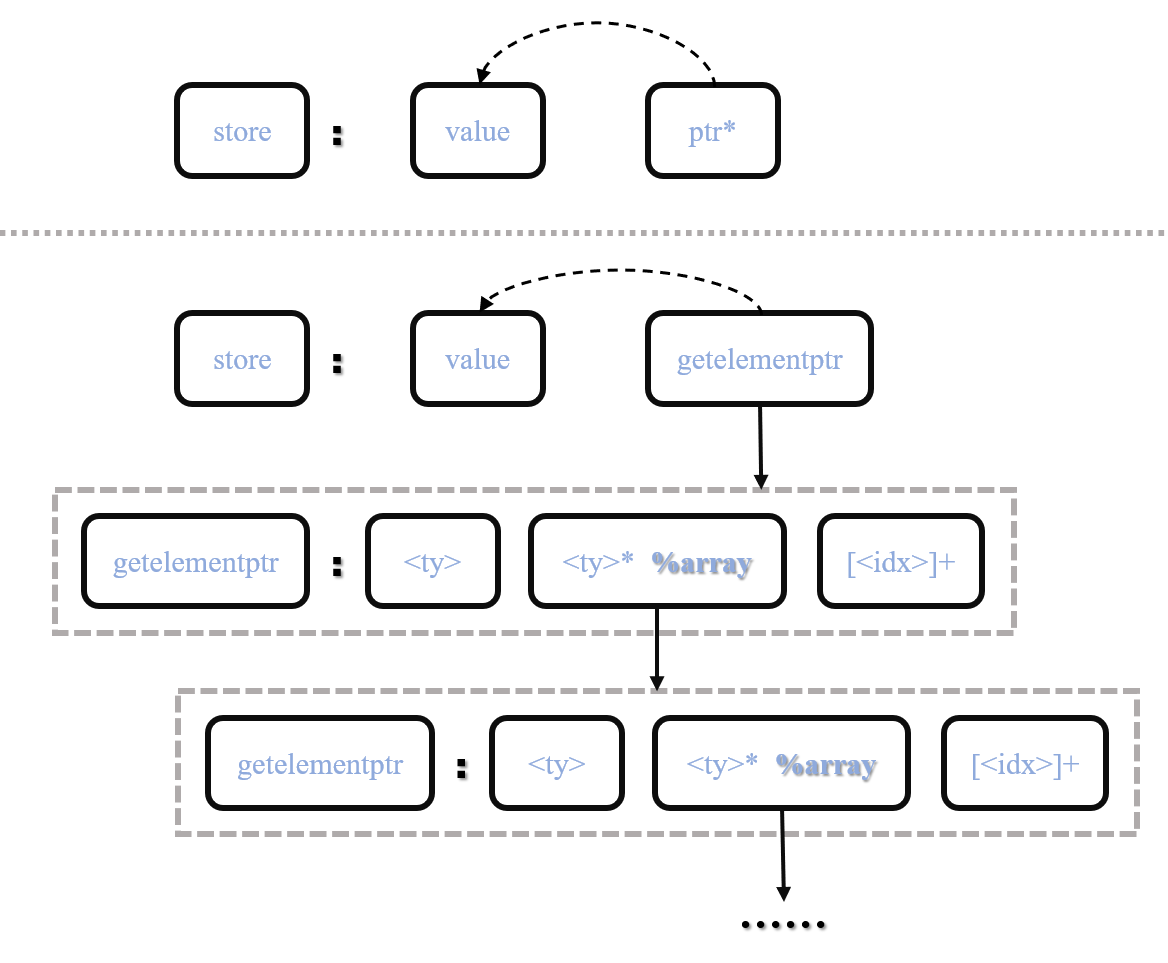
} 正常来说,对于一个store指令,如果其value (Operand(0))为污点源,那污点就会通过该指令传播到对应的ptr中去(Operand(1))。但由于C语言中存在对数组/结构体取值的操作,故store指令的Ptr也可能是GetElementPtrInst类型,所以代码中存在对store指令操作数的反复递归迭代,如下图所示:
1.2 Instruction::load
load指令的作用是从目标地址取操作数,其格式如下:
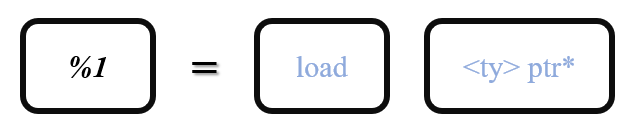
load指令将ptr所指向的数据以< type >的形式取出,并存入%1中。
Load指令处理部分:
case Instruction::Load:{
// should pair with a GetElementPtr
// remember to check if it is nested
LoadInst *LI = cast<LoadInst>(I);
Type *lType = LI->getPointerOperandType();
//获取ptr指向的结构名称
StringRef stName = handleType(lType);
if (!addToSet(result, stName)) {
break;
}
//如果Load指令的ptr指向的结构以"struct.list_head"开头
//并且Load指令的第一个参数为ConstantExpr(算术式)类型
if (stName == "struct.list_head" &&
isa<ConstantExpr>(LI->getOperand(0))) {
// looking type info in list_head
Value *bitcastV = nullptr;
//分析污点源的所有用户指令
for (auto *user : V->users()) {
//如果用户指令是phi指令
if (isa<PHINode>(user)) {
//继续获取其父指令
for (auto *uuser : user->users()) {
//如果其是一个类型转换指令
if (isa<BitCastInst>(uuser)) {
bitcastV = uuser;
}
}
}
}
//如果找不到类型转换指令则跳过
if (bitcastV == nullptr) {
break;
}
//遍历bitcast指令的父指令
for (auto *user : bitcastV->users()) {
//如果其父指令也是bitcast
if (isa<BitCastInst>(user)) {
BitCastInst *BCI = dyn_cast<BitCastInst>(user);
Type *src = BCI->getDestTy();
//将转换后的类型名称加入result
if (!addToSet(result, handleType(src))) {
}
}
}
break;
}
// would find a GetElementType
if (!isa<GetElementPtrInst>(LI->getOperand(0))) {
// it may not in some cases
// outs() << "in " << LI->getFunction()->getName() << "\n";
// assert(0 && "didn't find a GetElementPtrInst before LoadInst");
}
//同store指令,继续递归分析
Value *GetV = LI->getOperand(0);
// we skip these getElement since they are nested
while (isa<GetElementPtrInst>(GetV)) {
GetElementPtrInst *GEI = cast<GetElementPtrInst>(GetV);
StringRef name = handleType(GEI->getSourceElementType());
if (!addToSet(result, name)) {
break;
}
GetV = GEI->getOperand(0);
}
// the outside GetElementPtrInst
mergeSet(result, taintAnalysis(GetV, vs, found));
break;
} 如上述代码所示,load指令与store指令相比增加了struct.list_head的分析部分,list_head是Linux内核中的经典双向链表,其定义如下:
struct list_head {
struct list_head *next, *prev;
}; 针对struct.list_head,若其满足stName == "struct.list_head" && isa< ConstantExpr >(LI>getOperand(0)):
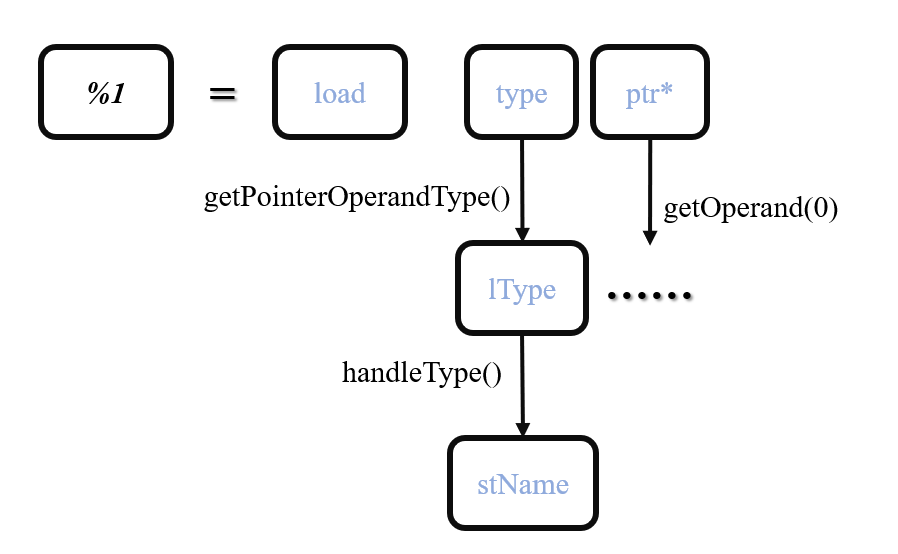
则代表其Load指令的type为struct.list_head类型且对应的指针ptr是ConstantExpr算术式类型,则分析该Load指令的所有父指令,其具体分析流程如下:
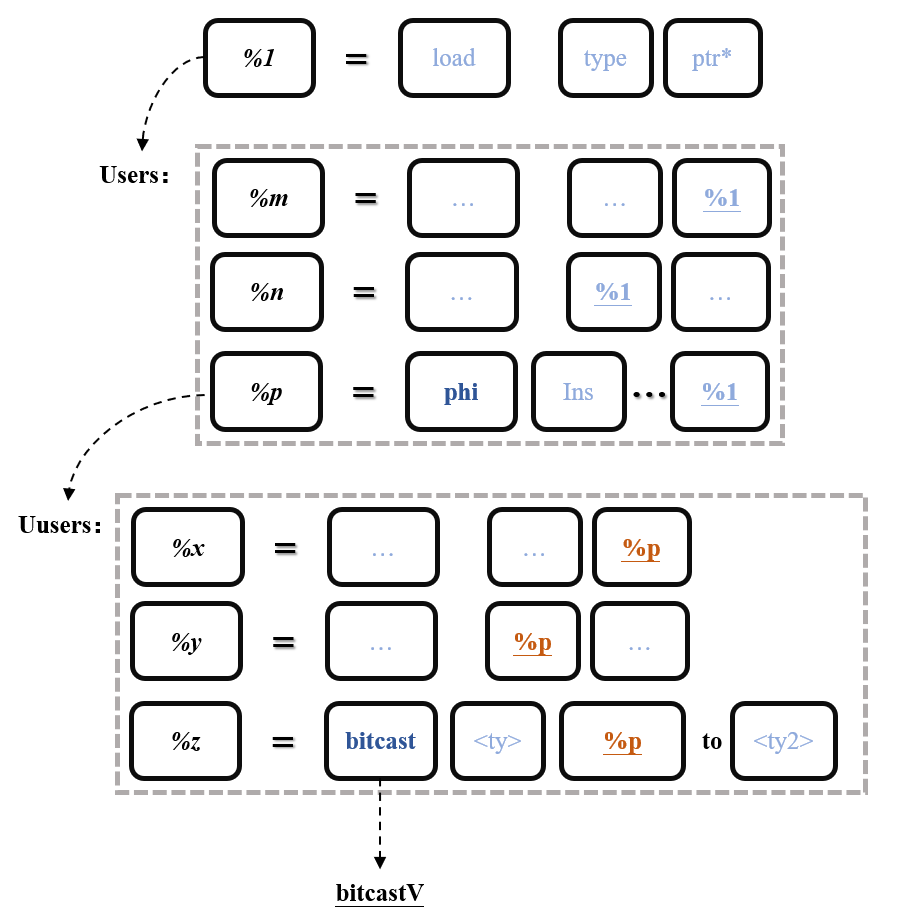
对于某个Load指令污点源,分析其父指令里的phi指令,再分析phi指令的父指令,找到其中的bitcast指令,后续再次分析这个bitcast指令的父指令:
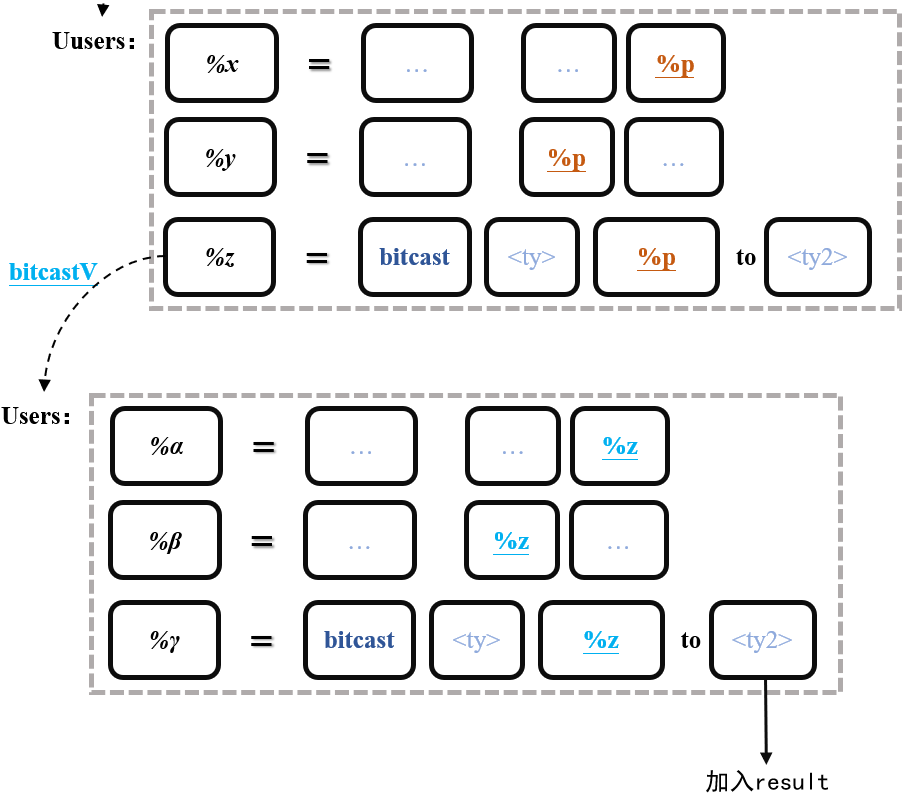
如果bitcastV的父指令也为bitcast指令,则将其目标type(即上图最后一行的type2)所指向的结构名称加入result集中。接下来针对GetElementPtrInst的分析同store指令,具体过程见上述代码。
1.3 Instruction::Call
遍历Call指令的所有参数,如果如果该参数不是某个结构体中的引用则将其指向的结构名加入result,然后递归深入分析arg参数:
case Instruction::Call:{
CallInst *CI = cast<CallInst>(I);
//遍历其参数列表
for (auto AI = CI->arg_begin(), E = CI->arg_end(); AI != E; AI++) {
//获取单个参数
Value* arg = dyn_cast<Value>(&*AI);
//跳过常数
if (dyn_cast<Constant>(arg)) {
continue;
}
// if not &a->b
// 如果该参数不是某个结构体中的引用(后续会分析)
if (!isa<GetElementPtrInst>(arg)) {
auto name = handleType(arg->getType());
addToSet(result, name);
}
// taint argument
// 继续递归分析
mergeSet(result, taintAnalysis(arg, vs, found));
}
break;
}1.4 Instruction::GetElementPtr
GetElementPtr指令的分析大体同上,也是递归分析,详见如下代码:
case Instruction::GetElementPtr:{
// this is nested
GetElementPtrInst *GEI = cast<GetElementPtrInst>(I);
// while (isa<GetElementPtrInst>(GEI->getOperand(0))) {
// // nest struct
// Type *src = GEI->getSourceElementType();
// GEI = cast<GetElementPtrInst>(I);
// }
Type *src = GEI->getSourceElementType();
// handle type
auto name = handleType(src);
if (!addToSet(result, name)) {
break;
}
// addToSet(result, name);
mergeSet(result, taintAnalysis(GEI->getOperand(0), vs, found));
// handle GetElementPtr other operands
for (unsigned i = 1, e = I->getNumOperands(); i != e; i++) {
V = I->getOperand(i);
if (dyn_cast<Constant>(V)) {
continue;
}
// taint value
mergeSet(result, taintAnalysis(V, vs, found));
}
break;
}1.5 Instruction::PHI
LLVM IR中PHI指令的格式如下所示:

phi指令用于不同代码块的分支判断,其根据不同代码块转移来的label选择value,对phi指令的相关函数操作如下所示:
PHINode::getNumIncomingValues():返回PHI节点的入边数量,即上图方括号的数量;
PHINode::getIncomingValues(i):返回第i个节点的value;
具体代码如下所示:
case Instruction::PHI:{
// check code coverage here to find the node
PHINode *PN = cast<PHINode>(I);
//遍历每个入边节点
for (unsigned i = 0, e = PN->getNumIncomingValues(); i != e; i++) {
//获取该节点的value
Value* IV = PN->getIncomingValue(i);
//这里什么都没做
if (Instruction *II = dyn_cast<Instruction>(IV)) {
// if II not get covered
// continue
}
//递归分析每个节点的value
mergeSet(result, taintAnalysis(IV, vs, found));
}
break;
}1.6 Instruction::Alloca
Alloca指令用于分配内存,这里遍历其所有父指令:
case Instruction::Alloca:
// return
// solve alias
//遍历其所有父指令
for (auto *user : V->users()) {
//若是store指令
if (isa<StoreInst>(user)) {
StoreInst *SI = cast<StoreInst>(user);
//获取store的参数
Value *next = SI->getOperand(0);
//递归分析
mergeSet(result, taintAnalysis(next, vs, found));
}
}
break;
1.7 Instruction::BitCast
BitCast同理,具体见代码:
case Instruction::BitCast:{
// handle type info
BitCastInst *BCI = dyn_cast<BitCastInst>(V);
Type *src = BCI->getSrcTy();
auto name = handleType(src);
if (!addToSet(result, name)) {
break;
}
mergeSet(result, taintAnalysis(BCI->getOperand(0), vs, found));
break;
}1.8 case Instruction::Select
Select指令类似于C语言中的x?:a:b语法,其格式如下:

其分析逻辑跟上述代码类似,详细见下:
case Instruction::Select:
for (unsigned i = 0, e = I->getNumOperands(); i != e; i++) {
V = I->getOperand(i);
//排除常数
if (dyn_cast<Constant>(V)) {
continue;
}
// taint value
mergeSet(result, taintAnalysis(V, vs, found));
}
break;2. Argument类型Source
else if (auto *Arg = dyn_cast<Argument>(V)) {
// argument
unsigned argNo = Arg->getArgNo();
StringRef name = handleType(Arg->getType());
if (!addToSet(result, name)) {
return result;
}
//获取参数属于的function
Function* callee = Arg->getParent();
//从Ctx->CallGraph中查找其父函数
auto parentName = findParents(callee->getName());
bool matched = false;
CallInstSet CISet;
//遍历call graph
//typedef llvm::DenseMap<llvm::CallInst*, FuncSet> CalleeMap;
for (auto M : Ctx->Callers) {
/* use endswith here because functions in the Callers
* are like `filename`.functionName
*/
if (M.first->getName().endswith(callee->getName()))
CISet = M.second;
//查找callee的所有caller
for (CallInst *caller : CISet) {
// TODO need pricise location check
if (parentName.find(caller->getFunction()->getName())
!= parentName.end()) {
matched = true;
auto parentFname = caller->getFunction()->getName();
if (parentFname.find("_sys_") != string::npos)
continue;
if (BlockFunc.find(parentFname) != BlockFunc.end())
continue;
KA_LOGS(2, "Taint to it's parent "<<caller->getFunction()->getName()<<" from "<<callee->getName());
//递归分析
mergeSet(result, taintAnalysis(caller->getArgOperand(argNo), vs, found));
}
}
}
return result;
/* global variable */
}3. GlobalVariable类型Source
全局变量单纯的添加即可:
else if (isa<GlobalVariable>(V)) {
GlobalVariable *GV = cast<GlobalVariable>(V);
StringRef name = handleType(GV->getType());
if (!addToSet(result, name)) {
return result;
}
}
综上所述,将污点分为instruction、argument和globalvariable三种类型,并分别分析,最终得到了一个结果集合result,这就是污点分析得到的关键结构对象。
Reference
- Markakd/GREBE (github.com)
- LLVM Pass:
- LLVM Pass入门导引
- llvm-project/llvm at main · llvm/llvm-project (github.com)
- About — LLVM 17.0.0git documentation
- PowerPoint Presentation (llvm.org)
- LLVM IR SSA 介绍 · GitBook (buaa-se-compiling.github.io)
- Writing an LLVM Pass — LLVM 17.0.0git documentation
- LLVM每日谈之八 PASS例子分析- (aliyun.com)
- LLVM开发者手册_llvm_shutdown_-CSDN
- CommandLine 2.0 Library Manual — LLVM 17.0.0git documentation
- LLVM: llvm::CallInst Class Reference
- LLVMdev] indirect calls tracking and control flow graph (google.com)
- LLVM: declaring an indirect function call in C that becomes a storedinst? - Stack Overflow
- LLVM Alias Analysis Infrastructure — LLVM 17.0.0git documentation
- 编译器优化:何为别名分析 - 知乎 (zhihu.com)
- Source Level Debugging with LLVM — LLVM 17.0.0git documentation
- I.users()_-CSDN博客
- kint:
- Paper:
- Wang X, Chen H, Jia Z, et al. Improving integer security for systems with KINT[C]//Presented as part of the 10th {USENIX} Symposium on Opera。ting Systems Design and Implementation ({OSDI} 12). 2012: 163-177.
- Song C, Lee B, Lu K, et al. Enforcing kernel security invariants with data flow integrity[C]//NDSS. 2016.
- Lin Z, Chen Y, Wu Y, et al. **GREBE: Unveiling exploitation potential for Linux kernel bugs[**C]//2022 IEEE Symposium on Security and Privacy (SP). IEEE, 2022.
- C/C++ && Kernel:
- 被知乎大佬嘲讽后的一个月,我重新研究了一下内联函数 - 知乎 (zhihu.com)
- c++ - How can I get Function Name of indirect call from CallInst in LLVM - Stack Overflow
- 函数指针及其定义和用法,C语言函数指针详解 (biancheng.net)
- 内部链接(internal linkage)和外部链接(external linkage)_CSDN博客
- compiler - Difference between direct and indirect function() calls - Software Engineering Stack Exchange
- Linux内核中经典链表 list_head 常见使用方法解析_内核链表 CSDN博客
PS
在人工分析前,先问问Cursor:
提问:这段代码的功能是什么?
**AI:**根据提供的代码,这是一个C++程序,用于对LLVM模块进行全局分析。它从输入文件中加载模块,执行基本初始化,并运行两个Pass:CallGraphPass和PointerAnalysisPass。
程序还从两个文件CrashReport和CallGraph中读取数据,以确定是否存在显式检查表达式并找到崩溃位置。如果在CrashReport文件中找到显式检查表达式,则程序将将“explicitly”标志设置为true。如果在CrashReport文件中找到“kernel BUG at”字符串,则程序还将将“explicitly”标志设置为true。然后,程序使用GlobalCtx和“explicitly”标志运行CrashAnalyzer来分析崩溃位置。
如果DumpLocation不为空,则程序将将分析结果转储到指定位置。否则,它将将结果转储到标准输出。最后,程序返回0。
因此,该程序的主要功能是对LLVM模块进行全局分析,并分析崩溃位置。
提问:请介绍这段代码使用的LLVM API。
**AI:**根据提供的代码,该程序使用了LLVM的以下API:
- llvm::IRReader:用于从文件中读取LLVM IR。
- llvm::LLVMContext:用于管理LLVM IR的上下文。
- llvm::Module:表示LLVM IR模块。
- llvm::PassManager:用于管理LLVM Pass。
- llvm::Verifier:用于验证LLVM IR的正确性。
- llvm::ManagedStatic:用于管理静态对象的生命周期。
- llvm::PrettyStackTrace:用于在程序崩溃时打印调用堆栈。
- llvm::ToolOutputFile:用于将输出写入文件。
- llvm::SystemUtils:提供了一些系统相关的实用函数。
- llvm::FileSystem:提供了一些文件系统相关的实用函数。
- llvm::SourceMgr:用于管理源文件和缓冲区。
- llvm::Signals:用于处理信号。
- llvm::Path:提供了一些路径相关的实用函数。此外,该程序还使用了一些自定义的类和函数,如GlobalCtx、CallGraph、StructFinder、CrashAnalyzer和PointerAnalysis。
提问:请问你能画出代码的结构图吗?
AI:
main function
├── cl::list < std::string> InputFilenames
├── cl::opt < unsigned> VerboseLevel
├── cl::opt < std::string> DumpLocation
├── cl::opt < std::string> CrashReport
├── CallGraphPass
├── PointerAnalysisPass
├── CrashAnalyzer
└── return 0其中,
InputFilenames、VerboseLevel、DumpLocation和CrashReport是程序的命令行参数。CallGraphPass和PointerAnalysisPass是两个LLVM Pass,用于分析LLVM模块的调用图和指针分析。CrashAnalyzer是一个自定义的类,用于分析崩溃位置。程序最后返回0。