
Eunomia: Enabling User-specified Fine-Grained Search in Symbolically Executing WebAssembly Binaries
**时间:**2023.4
**作者:**Ningyu He、Zhehao Zhao(北大)/Haoyu Wang(华科)
**会议:**ISSTA‘2023
Abstract
尽管现有的技术已经提出了自动化的方法来缓解符号执行的路径爆炸问题,但用户仍然需要通过仔细应用各种搜索策略来优化符号执行。由于现有的方法主要只支持粗粒度的全局搜索策略,它们不能有效地遍历复杂的代码结构。在本文中,我们提出了Eunomia,一种符号执行技术,允许用户指定局部领域知识,以实现细粒度搜索。
在Eunomia中,我们设计了一个富有表现力的领域特定语言(DSL),即AES,让用户可以精确地将本地搜索策略定位到目标程序的不同部分。为了进一步优化局部搜索策略,我们设计了一种基于区间的算法,该算法可以自动隔离不同局部搜索策略的变量背景,避免同一变量的局部搜索策略之间的冲突。
我们将Eunomia作为一个针对WebAssembly的符号执行平台来实现,这使我们能够分析用各种语言(如C和Go)编写但可以编译成WebAssembly的应用程序。据我们所知,Eunomia是第一个支持WebAssembly运行时全部功能的符号执行引擎。
我们用一个专门的符号执行微基准套件和六个真实世界的应用来评估Eunomia。我们的评估显示,Eunomia在现实世界的应用中加速了错误检测,最多可达到三个数量级。根据一项全面的用户研究结果,用户可以通过编写一个简单直观的AES脚本来显著提高符号执行的效率和效果。除了验证六个已知的真实世界的bug,Eunomia还在一个流行的开源项目Collections-C中检测到两个新的0-day bug。
Background
1. 样例
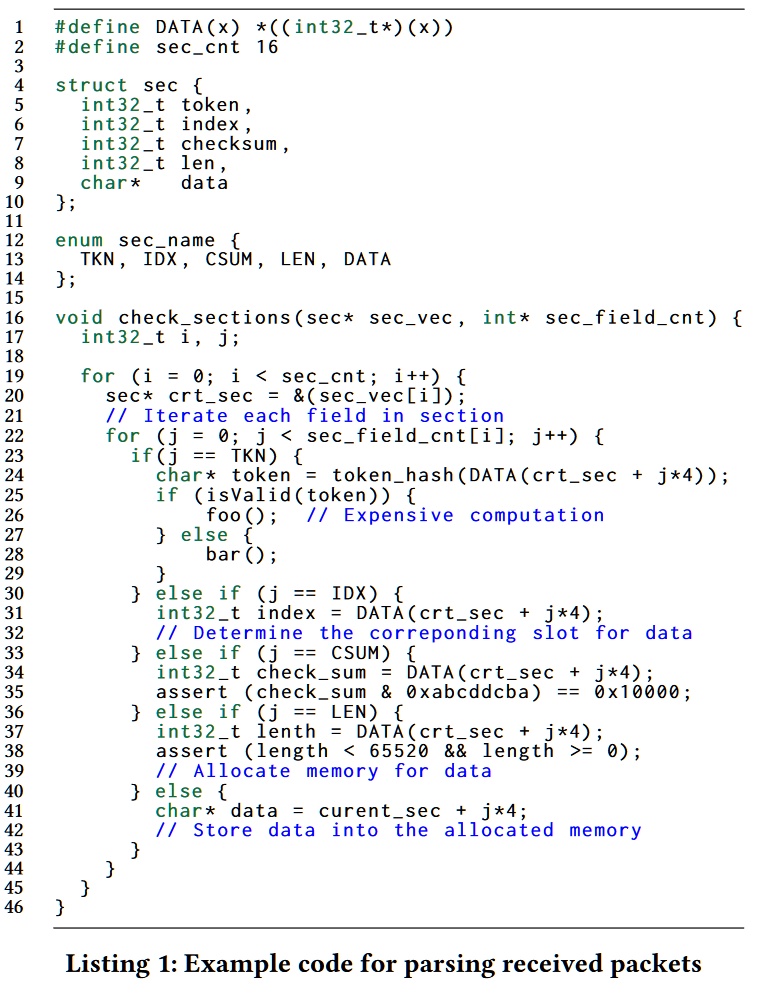
1.1 代码功能
以上图代码为例,其为一个工业网络协议处理函数check_sections。函数的输入是一个section 向量sec_vec和每个section所含的fields数sec_field_cnt。每个section最多有5个fields(L4)。具体来说,前三个section:token、index和checksum,呈现了每个部分的元数据,它们分别指的是发送方的token、收到的相应部分的索引,以及数据的校验和。len表示数据的长度,其正确性由上述的校验和验证。
综上,函数check_sections检验sec_field_cnt限制下的所有字段,以两层嵌套循环的方式实现,外层循环遍历所有收到的部分,而内部循环遍历所有字段并进行相应的验证。
1.2 现有工具问题
1.2.1 Klee
由于路径爆炸问题,直接在上述代码上使用符号执行无法在合理的时间内完成验证。在实践中,开发者可以提供两块领域知识来加速分析,如下所示:
DK1. 优先考虑成本较低的else分支,推迟分析昂贵的函数foo,同时验证用户令牌(L23 - L29);
DK2. 为了避免在分析复杂的数据(L41)时陷入困境,符号执行可以首先完成对简单场的分析,即tokn、index,以及checksum。
Klee不能有效地应用DK1和DK2,因为它没有确定优先级的原语。通常,我们使用KLEE原语,如klee_assume(cond)和klee_prefer_cex(obj, cond)来指定符号执行中的额外约束。不幸的是,这些原语只能修剪不需要的状态,而不能优先考虑有趣的路径。具体来说,klee_assume(cond)可以用来插入额外的约束,不符合cond的路径将被剪除。至于klee_prefer_cex(obj, cond),它为待测函数的符号参数增加了一个优先值。它只能在测试驱动中使用,而不是在代码中的任何地方(只能在产生输入时使用,故其不能直接引导符号执行去偏好某一部分代码)。
对于DK1,KLEE能做的最接近的做法是添加klee_assume(isValid(token)==0),这样就可以删去包含foo()的分支。然而,在DK1中,我们只想优先处理通向bar()的分支,直接修剪掉的路径可能会破坏分析的合理性。同样地,KLEE也不能利用DK2,其最接近的做法是在L22后面加上klee_assume(j<3)。然而,这种方法也影响了分析的合理性,因为KLEE直接放弃了对LEN和DATA字段的分析。
综上,利用Klee只能做到舍弃某部分的控制流分支而做不到“偏好”,但舍弃部分控制流并不符合分析工作的初衷。
1.2.2 其他方法
虽然有其他工作对执行路径进行优先排序[33, 34, 46, 53, 68],但它们也不能正确利用用户定义的领域知识。现有的路径优先化方法要么依赖于预先定义的启发式方法、黑盒策略,甚至是机器学习算法。他们的目标是加速一般的符号执行,而不是采用用户定义的领域知识。因此,它们与我们的工作大多是正交的。
1.3 解决方法

上图是为样例代码生成的AES自定义脚本,其可以实现DK1与DK2。每个语句由两部分组成,即定位部分和知识部分。我们可以看到,这两个语句被包裹在一个checker中,该checker为一个函数check_sections()(L1)工作。上图脚本的语义为:
(1)验证前三个元数据section;
(2)跳到内循环条件检查,不验证长度和数据;
(3)移动到下一个部分,重复(1)和(2);
(4)一旦所有前三个步骤完成,处理剩余的长度和数据字段。
2. 问题背景
目前已知的符号执行技术的问题是往往过于粗·略,无法满足某些分析目的。现有的方法大多支持应用于整个程序的全局搜索策略。然而,全局策略并不是最优的,因为一个程序的不同代码块具有明显的特征,可能适合不同的局部搜索策略。
假设代码的一个嵌套循环部分负责解析收到的网络数据包,开发者想检查嵌套循环中是否存在缓冲区溢出。然而,内层循环有一个复杂的函数,需要大量的时间来验证。因此,开发者可能想优先考虑内层循环中的其他轻量级部分,以最大化符号执行的覆盖率。不幸的是,现有的方法不能优先考虑内循环的一个子集。这导致了要么在处理复杂函数时被卡住,要么产生不健全的分析结果。因此,有必要让用户为不同程序代码块的局部搜索策略提供提示。
要实现为不同程序代码块提供不同局部搜索策略,需要面对的问题有:
如何为目标程序的不同部分有效地指定本地搜索策略;
实现本地搜索策略,同时避免潜在的冲突:
同一个变量可能同属于不同的代码结构,例如,一个变量可能同时被多层循环结构共享。因此,多个本地搜索策略可能因为相同的变量产生冲突。
已知的对Wasm做符号执行的方法缺少对WASI的支持,因此限制了应用的范围。
Contributions
- 提出并实现了一个新的符号执行框架Eunomia,它的路径搜索过程可以通过用户指定的领域知识进行细化调整,而无需对目标程序进行任何修改;
- 提出一个原创的领域特定语言(DSL),即AES,其可以可以绑定一组局部适配函数来加速分析过程。此外,用户还可以为语句或函数引入前置和后置条件,甚至可以在任意位置上引入to-checked谓词;
- 提出一个新的路径搜索策略,interval-based path searching,它可以将符号状态隔离到不同的语境中。为此,状态可以被任意修剪和重新排序而不影响最终结果的一致性;
- Eunomia在GitHub的一个2.5千星的项目(Collections-C)中发现了两个新的漏洞,开发人员已经承认并修补了这些漏洞;
- Eunomia是第一个支持Wasm全符号特性的符号执行引擎,并且比其他state-of-the-art表现更好。
Model
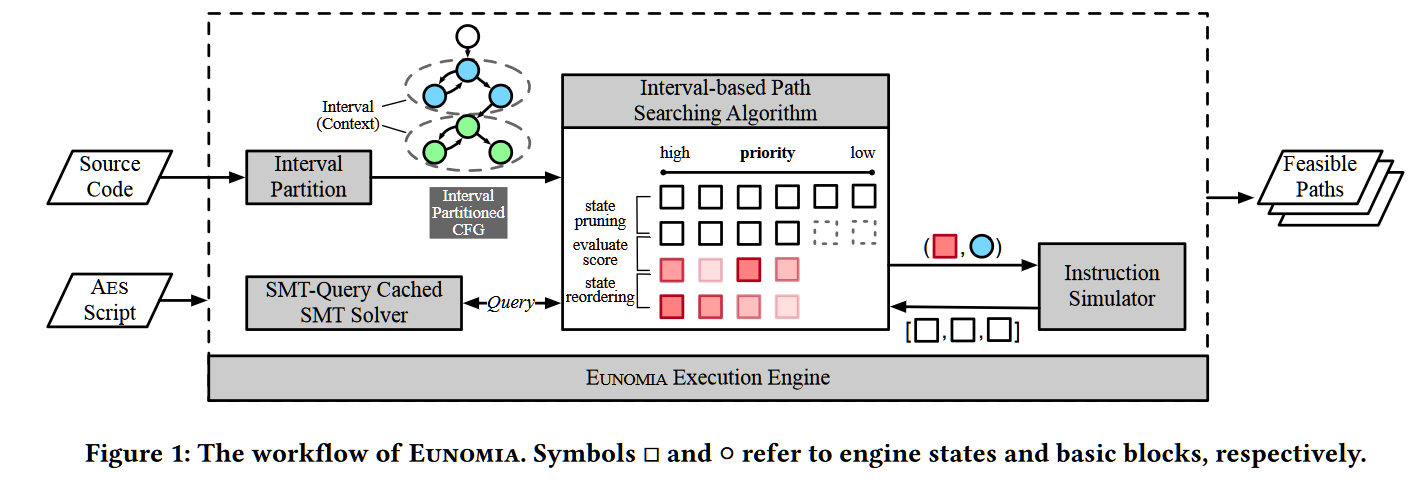
如上图所示,Eunomia将待分析程序的源代码和一个Aes脚本作为输入。给定程序的CFG将被划分为不同区间(详见第3.2.1节),其中每个区间都可以被视为一个独立的上下文。基于分割出的区间,我们提出一种基于区间的路径搜索算法。该算法为状态维持一个优先级队列,这些状态的优先级分数由Aes脚本中提供的局部适配函数来评估。为此,该算法从队列中弹出分数最高的状态和它接下来的一个基本块作为指令模拟器的输入。模拟器根据基本块中的指令对状态进行符号执行,如果有必要进行路径分叉,则返回一个或多个状态。注意,状态将在其相应的上下文下被评估。这样的迭代一直持续到队列中没有候选状态或分析终止。Eunomia最后会输出所有可满足的路径。
WebAssembly
目前最先进的符号执行引擎是一个商业的开源工具,Manticore [48],它需要大量的手工工作来对Wasm运行时的API进行建模,以分析Wasm应用程序。为了减轻安全研究人员分析Wasm二进制文件的负担,我们实现了Eunomia作为第一个支持具有约8K Python3代码的商用现成Wasm应用程序符号执行引擎。
1. Memory Modeling
WebAssembly采用线性内存作为内存模型。其内存中的数据是原始的比特串,可以被索引和解释。为了模拟通过具体指针的load和store指令,我们采用了[35]提出的映射结构,其中值是由BitVector建模的原始位串,而键是其对应的地址范围。然而,这个模型并不能正确地处理符号指针。
为了解决符号指针问题[40],我们采用完全符号化的内存模型[4]。具体来说,如果加载的地址是一个符号,Eunomia会考虑其所有可能的位置。我们没有像KLEE[7]那样对多个状态进行分叉,这引入了巨大的开销,而是将负担转移给SMT求解器,因为它在解决这种约束时不断地更新[7, 8, 19, 55]。换句话说,我们利用if-then-else(ite)语句来列举所有可能的位置,如下图所示,v代表load操作,内存的范围是(0-5),指针可能指向任意位置,store指令类似。
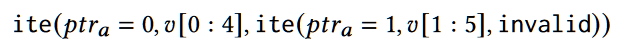
2. External Functions Emulating
在Runomia引擎中,我们应用基于摘要的技术来处理这个问题。具体来说,有一个WebAssembly接口(WASI)[66],它定义了一个Wasm二进制文件与外部环境互动的标准接口。WASI主要包括IO相关的函数,如fd_write和fd_open。为此,我们参考了文档,对所有这些与IO相关的函数进行建模,以模拟来自外部环境的响应。此外,我们还总结了C和Go中常见的标准库函数的行为,包括算术运算,以及字符串和内存操作函数。因此,所有对外部的调用都将被拦截。每个状态中的相应字段将根据函数总结进行更新。
3. SMT-Query Cache
我们设计了一个用于查询的缓存池来缓解这个问题。从形式上看,我们将SMTquery缓存定义为一个包含所有已解决约束条件的集合𝐶=[𝑐1, 𝑐2, …, 𝑐𝑛]。对于每个𝑐𝑖∈ 𝐶,我们的缓存池都会缓存其结果和所有从中推断出的公理。然后,对于一个给定的约束𝑐𝑠𝑜𝑙𝑣𝑒需要解决,在要求SMT求解器进行求解之前,Eunomia首先按照三个规则查询缓存 𝐶:

如果𝑐𝑠𝑜𝑙𝑣𝑒 不符合所有三个规则,Eunomia将𝑐𝑠𝑜𝑙𝑣𝑒 发送给SMT解算器并缓存结果。