
Fuzzing: A Survey for Roadmap
**时间:**2022
**作者:**Xiaogang Zhu、Sheng Wen(澳洲斯威本科技大学)
**期刊:**ACM Computing Surveys(中科院一区)
Abstract
最近,模糊测试(fuzzing)在检测安全缺陷方面有着大量使用,它产生了大量的测试案例,并监控缺陷的执行情况,fuzzing已经在各种应用程序中发现了成千上万的错误和漏洞。
Fuzzing虽然有效,但对其所面临的问题缺乏系统的分析。作为一种缺陷检测技术,fuzzing需要缩小整个输入空间(input space)和缺陷空间(defect space)之间的差距。如果对生成的输入没有限制,输入空间是无限的,然而,应用中的缺陷是稀疏的,这表明缺陷空间要比整个输入空间小得多。此外,由于fuzzing会产生大量的测试用例来反复检查目标,这就要求fuzzing以自动的方式进行,由于应用程序和漏洞的复杂性,对不同的应用程序进行自动化执行具有挑战性
在这篇文章中,我们系统地回顾和分析了这些gap以及它们的解决方案,同时考虑了广度和深度。这项调查可以作为初学者和高级开发人员更好地了解fuzzing的路线图。
Generating input optimization
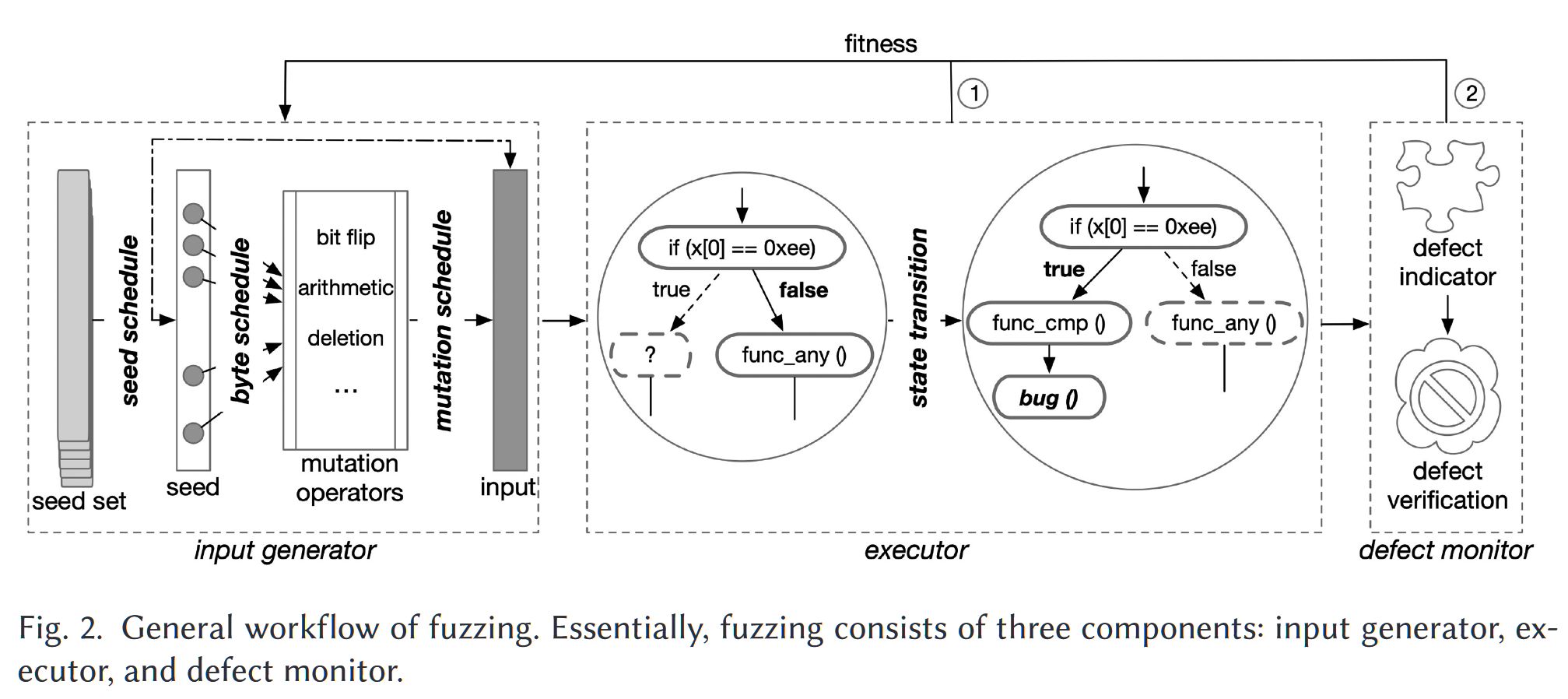
如上图所示为fuzzing的基本流程,在生成输入时,其可以对seed set,seed schedule,byte schedule和mutation schedule做优化。
1. Seed Set Selection
**在保障代码覆盖率的前提下,seed set越小越好。**这是因为多余的种子会浪费算力,重复检测已经检测过的代码块。COVERSET[158]将最小化种子集的问题表述为最小集合覆盖问题(MSCP),它最小化包含所有元素的子集。由于MSCP是一个NP-hard问题,COVERSET使用贪心多项式近似算法来获得最小集。
2. Seed Schedule
在选择了Seed set之后,Seed Schedule的任务是从其中选择对应的种子用于后续操作,并为所选种子分配其可运行的最大时间。
由于 PUTs 与defects的复杂性,未发现代码覆盖率与未发现漏洞是不可知的,我们无法知道一个输入是否能触发漏洞,类似地在检索代码之前我们也不能获得程序行为的概率分布,数学上几乎不可能找到一个全局最优解法,因此研究人员基于多种优化方法来近似地解决这个问题。
2.1 Fitness by #Bugs
Fitness == 衡量seed/input指标。Fitness by Bugs意味着以发现bug的多少作为种子的评价标准。
- 为了使bug最多,一种方法是在随机或按顺序选择种子的同时,分配每个种子的时间预算。如果不考虑执行状态,最大化问题可以简化为整数线性规划(ILP)问题。也就是说,ILP打算在线性约束条件(例如每个种子的时间预算的上限值)下最大化bug的数量。通过解决ILP问题,可以自动计算每个种子的时间预算。
- 另一种见解是将发现bug的过程视为WCCP问题。经典概率问题:优惠券收集问题 - cnblogs.com
- ILP和WCCP都会给更可能发现bug的种子分配更多可用时间。
ILP和WCCP这两种理论上可以计算出全局最优解的算法需要知道环境的全部信息,由于这并不可能,所以基本效果都不好(例如强化学习中动态规划算法虽然可以直接求得全局最优策略,但由于环境信息不可知或算力限制,基本没有实际应用场景),只在早期使用。
2.2 Fitness by State Transition (Markov Chain)
因为在PUT中,bug是稀疏的,当使用bug的数量作为fitness时,优化过程将迅速收敛到局部优化。因此,它可能会错过探索更多代码覆盖的机会,由复杂条件包裹的深层bug就会避开fuzzing。
为了缓解这个问题,fuzzer基于执行状态(如代码覆盖率)作为fitness,因为执行状态可以为fuzzing提供更多的信息。目前大多数现有的fuzzer都是基于代码覆盖率计算fitness。使用代码覆盖率的另一个原因是,更大的代码覆盖率表明发现错误的可能性更高[130]。
两种建模方法:
Block transition
Fuzzing之前通过蒙特卡洛采样(Monte Carlo method),计算出程序CFG中每个基本块跳转的概率P
ij,进而计算出某个种子在执行过程中执行路径的概率(经过的基本块概率相乘)。种子对应的概率越低则fitness越高。Path transition
P
ij这里代表从Seedi变异到Seedj的概率,每个P通过之前执行fuzzing结果计算,同样是概率越小fitness越高,更倾向于生成稀有的path。这里AFLFast[23]使用1/pij为每个种子分配能量,其还有变式:directed greybox fuzzing (DGF) [22, 217]和regression greybox fuzzing (RGF) [214]。
使用马尔科夫理论对state transition建模,以此优化seed schedule有一定效果,但其缺点是MC需要计算所有状态的概率。实际使用中,很多状态并没有被检测,故MC方法也容易陷入局部最优解(还是环境信息获取不全面的问题)。
2.3 Fitness by State Transition (Multi-armed Bandit)
前置知识:
rule of three(statistics):如果前n次采样事件a都没有发生,则有95%的置信度表明至多3/n的概率事件a会发生。Rule of three (statistics) - HandWiki#:~:text=In statistical analysis%2C the rule of three states,good approximation of results from more sensitive tests.);
Round-Robin Scheduling:轮询调度算法;
对于MC建模方法导致的问题:
对于使用MC的Block transition:可以使用统计学中的rule of three**规则来为未出现的state赋概率值;
**对于使用MC的Path transition:**使用Round-Robin Scheduling先为每个seed赋相同的time budget,后续经过不断采样再使用计算的概率值。但这么做的问题就是不好平衡Round-Robin和Markov,搜索有所seed和聚焦于某个seed是一个“exploration and exploitation”问题(又是经典的e and e问题)。
综上,为了解决这个问题引入了Multi-armed Bandit模型。
多摇臂老虎机,Multi-armed Bandit是强化学习中的经典模型,老虎机有n个摇杆,每个摇杆i有P~i~的概率中奖,每次可以选择一个摇杆拉下。<u>玩家的目的是通过有策略的尝试,找到中奖率最高的摇杆(因为这么做就可以reward期望最大化)。</u>在MAB游戏中,其exploration代表不断尝试不同的摇杆,获取其对应reward的期望,也就是对环境采样;其exploitation代表找到最好的策略使reward最大化,这里最好的策略就是只拉下中奖概率最高的摇杆。
在fuzzing中,一个seed就是一个摇杆(arm),对应的reward就是该seed运行时的一系列发现。
EcoFuzz[203]将其建模为一个MAB问题,并使用$E(t_i)=1-\frac{P_{ii}}{\sqrt{i}}$来表示每个seed ti的期望(而不是最开始的新路径数/变异次数,因为这样会导致期望越来越小,梯度过小,比较结果不明显),这里Pii表示一个种子变异后仍走原来路径的概率,故EcoFuzz更偏向可以生成新路径的种子;
AFL-HIER[88]也将其建模为一个MAB问题,不同于EcoFuzz只使用了单一的edge coverage来retain新的种子,AFL-HIER利用了更多评价标准(函数,edge,基本块等),其使用一个MAB算法UCB1来解决多等级评价标准MAB问题。
2.4 Fitness by State Discovery
物种发现问题:生态学家从野外收集大量样本,样本中的物种可能是丰富的或罕见的。生态学家根据这些样本推断出一个完整组合的属性,包括未发现的物种。
同样地,fuzzer产生的输入是收集的样本,而程序的输入空间是整个集合体。fuzzing算法根据特定的指标将输入归类为不同的种类。例如,一个执行路径可以是一个物种,所有行使该路径的输入都属于这个物种。在这种情况下,一个罕见的物种是一个只有少数输入行使的执行路径。物种发现中的一个重要假设是,未发现的物种的属性几乎只能由已发现的稀有物种来解释[31]。这个假说意味着fuzzing可以给稀有物种(稀有路径)分配更多的能量来发现新的状态。
基于物种发现的问题,Entropic[21]将fuzzing理解为一个学习过程;即fuzzer逐渐学习更多关于程序行为的信息(物种)。Entropic建议使用Shannon’s entropy(香农熵)[170]来衡量物种发现的效率,原始的香农熵H衡量物种的平均信息,计算公式为$H = -\sum_i{p_ilog(p_i)}$,其中pi是选择物种Si的概率。如果收集的样本包含许多物种,熵H就大(信息量大);否则,如果收集的样本包含少数物种,熵H就小(信息量小)。
同时,Entropic认为,物种的发现率可以量化fuzzer的效率。根据香农理论推导,Entropic衡量种子的物种发现效率。具体来说,$p_i^t$是变异种子t并产生属于物种Si的输入的概率。种子t的学习率是根据概率$p_i^t$和改进的熵估计器计算的。通过熵得出的结论是,更多的能量被分配给学习率较大的种子;也就是说,发现新物种更有效的种子被分配更多的能量。
3. Byte Schedule
Byte Schedule的作用是决定在种子中选择一个字节来进行变异的频率。大多数fuzzer通过运行信息来启发式或随机地选择字节。相较于Seed Schedule,Byte Schedule需要对程序有着跟深入的理解,例如对路径条件和数据流的分析。
定义The importance of bytes:bytes如何影响fuzzing。
- **影响branch behavior:**NEUZZ [172]和MTFuzz [171]将输入bytes和branch behaviors之间的关系通过深度学习模型建模,DL模型的梯度量化了bytes的重要性,因为一个bytes的梯度越大,该bytes的很小的扰动就会导致branch behaviors的重大差异。故对于接下来的种子变异,fuzzing将优先考虑具有较高重要性的bytes进行突变。
- **影响fitness:**AFLChurn [214]利用了Ant Colony Optimization (ACO),蚁群优化算法来学习bytes如何影响种子的fitness。
4. Mutation Operator Schedule
Mutation Operator Schedule的作用是选择一个变异操作来对所选bytes进行变异,Mutation Schedule决定了下一次变异bytes时使用那种变异方法,即变异器(mutator)。
Classfuzz [42]认为探索了更多新状态的mutator被选中的概率应该更高,因此,Classfuzz假设**Markov Chain Monte Carlo (MCMC)**可以对Mutation Schedule的过程进行建模,其采用了H-M(Metropolis-Hastings)算法。具体来说,每个突变器都有一个成功率,它可以量化突变器所探索的新状态。Classfuzz首先随机选择下一个变体,然后根据当前变体和所选变体的成功率来接受或拒绝选择。
MOPT[116]采用了Particle Swarm Optimization (PSO),粒子群优化算法来对mutator选择过程建模,构建mutator选择的概率分布。
5. Diverse Information for Fitness
Fitness除了应用于schedule of seeds, bytes, 和mutators,也可以被应用于seed retention。Fuzzers通常利用遗传算法(GA)来制定种子保留的过程。具体来说,fuzzer通过变异种子生成输入,如果输入探索到新的执行状态(即更好的fitness),则该输入会被保留为新的种子。当为下一轮测试选择种子时(基于seed schedule),fuzzing可能会选择这个新的种子。
为了提高对defect发现的能力,需要更敏感的代码覆盖率来揭示更多的执行状态信息。另一方面,针对一些特定的场景,如深度学习模型[148]或机器人车辆[82],设计了新的fitness类型。请注意,fitness信息的多样性在前面提到的seed retention和schedule问题上都得到了利用。
5.1 Sensitive Code Coverage
Fitness的敏感性表明其区别不同程序运行状态的能力。
许多coverage-guided fuzzers会实现一个bitmap用于向fuzzing提供edge-coverage的信息,bitmap本质上是一个紧凑的vector,其索引代表了对应edge的标识符,标识符是$hash(b_i,b_j)$,bi和bj是随机分配的块标识符。
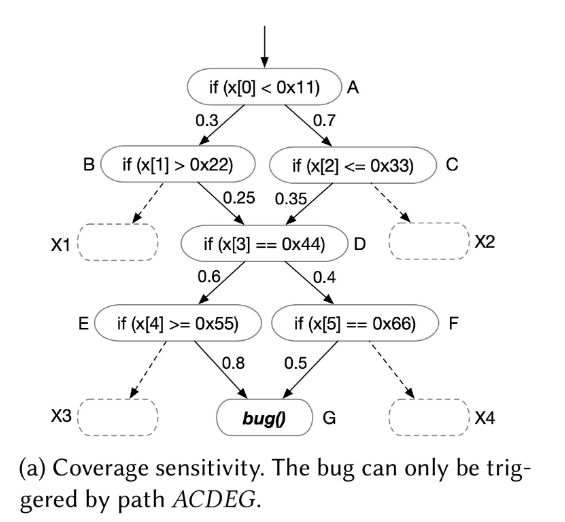
如上图所示,如果存在哈希碰撞,导致$id_{AB}=id_{AC} , id_{BD}=id_{CD}$,则路径ABD和ACD就会被认为是一条路径。如果存在Bug路径ACDEG,则其会被fuzzer忽略。虽然这种实现在执行过程中速度很快,但它牺牲了edge-coverage的精度。
有了bitmap,fuzzing可以确定一个输入是否行覆盖了新的edge,如果有的话,就保留这个输入作为新的种子。具体来说,fuzzing维护一个总体bitmap,它是单个执行的bitmap的联合。当确定新边时,fuzzing将单个bitmap与整体bitmap进行比较,以检查单个bitmap中是否存在新边。
然而,位图的联合会失去执行的信息[118]。例如,如果图3(a)中的路径ABDEG和ACDFG已经被执行,那么执行新路径ACDEG的输入将不会被保留为种子,因为所有的边已经存在于整体bitmap中。因此,一个解决方案是将所有单个的bitmap组合起来[118]。因为bitmap的组合会引入太多的种子,一个关键的挑战是如何平衡fuzzing的效率和保持覆盖率的敏感性。一个潜在的解决方案是使用动态主成分分析[191]来降低数据集的维度[118]。
其他提高edge-coverage灵敏度的解决方案包括路径哈希[198]、调用上下文[37, 87, 171]、多级覆盖[88]和代码复杂性[105],这些都为边缘覆盖增加了额外的信息。

专注于代码覆盖率的fuzzing也不一定适合探索复杂的执行状态。上图是一个迷宫程序,每次走一步,只有当走到出口时才会出发Bug。然而,由于switch语句只有四条edge,很快就会探索完,在这之后fuzzing就很难继续根据代码覆盖率来指导测试。
5.2 Diverse Fitness
Fitness并不一定非得用code coverage,实际上,code coverage不是一直是最好的适合fuzzing反馈信息。如果没有code coverage,一个直觉上的做法是根据执行结果保留种子,如执行结果的合法性[141]或协议实现的状态机[154]。不同的fitness如下:
- ***Legality of execution result:***一个面向对象的程序(如Java)由一连串的方法调用组成,执行结果要么合法,要么抛出异常。Fuzzing生成并获得可以可以探索更多新的、合法的对象状态新的方法调用序列[141] ;
- ***State machine of protocol implementations:***一个状态机由状态集合和转变其状态的输入组成。由于协议的复杂性,fuzzer通常通过逐渐向状态机添加新的状态来推断状态机[55, 61, 64, 69, 154]。状态机从一个种子(即初始状态机)开始,fuzzer对状态机的当前状态进行突变以探索新的状态。漏洞的分析是基于状态机的,其目的是为了搜索导致漏洞的转换[55];
- ***Safety policy of robotic vehicles:***安全策略是对机器人车辆的物理或功能安全的要求,例如车辆发动机的最高温度[82]。当一个输入更接近于违反政策时,该输入就会被保留下来,供以后突变使用;
- ***Fitness for deep learning systems:***The fuzzing of deep learning systems (DLSs) 旨在提高它们的鲁棒性和可靠性[68, 115, 148]。为了实现这一目标,fuzzer设计了不同类型的fitness,例如用于发现角落状态的神经元覆盖率[148],用于增强训练数据的损失函数[68],或者用于探索深度学习推理引擎(即框架和库)的操作者级覆盖率[115]。
- ***Validation log of Android SmartTVs:***验证日志是正在执行的Android智能电视的信息[1]。验证日志被用来推断有效输入和提取输入边界。有效输入为fuzzing提供了有效的种子,而输入边界则减少了输入的搜索空间。
- ***Behavioral asymmetry of differential testing:***对于差分测试(differential testing),错误是通过观察不同实现的行为差异发现的,这些实现具有相同的功能,在相同的输入上。行为的不对称性表明各种实现的差异程度。模糊测试的目的是生成能够发现更多差异的测试案例;
- ***Alias coverage for data race:***别名覆盖是为了检测内核文件系统中的数据竞争[194]。数据竞争是一个并发的错误,其中两个线程访问一个共享的内存位置而没有适当的同步。因此,别名覆盖跟踪可能相互交错的内存访问对;
- ***Dangerous locations for bugs:***危险的位置(Dangerous locations)是那些有更高概率触发错误的代码区域。因此,fuzzer可以将资源引向这些位置,以提高fuzzing的效果和效率。对于并发性错误,危险位置通常是指导致违反原子性的代码区域[97]、数据竞赛[84, 167]或可疑的交织[35]。对于非并发性错误,危险位置可以通过补丁测试[122]、崩溃再现[155]、静态分析报告[48]或信息流检测[123]获得。此外,危险位置可能是内存访问[84,182,188],sanitizer检查[40,140],或提交历史[214]。
6. Evaluation Theory
Fuzzing的评测通常与检测阶段分开进行,然而,我们认为评估是fuzzing过程的一部分,因为适当的评估可以帮助提高fuzzing的性能[215]。适当的评价包括有效的实验corpus[215]、公平的评价环境/平台[30, 104, 126]、合理的fuzzing时间[17, 20]和全面的比较指标[96, 104]。尽管这些研究工作在适当的评价方面做出了努力,但关于如何评价技术(即fuzzing algorithms)而不是实现(即实现算法的代码),仍然是一个开放的问题[18]。一个广泛使用的解决方案是基于统计测试来评估fuzzer,它提供了一个反映模糊技术之间差异的可能性[96]。
7. Summary
下表表明了不同fuzzing processes使用的不同优化方法来优化**input generation**:
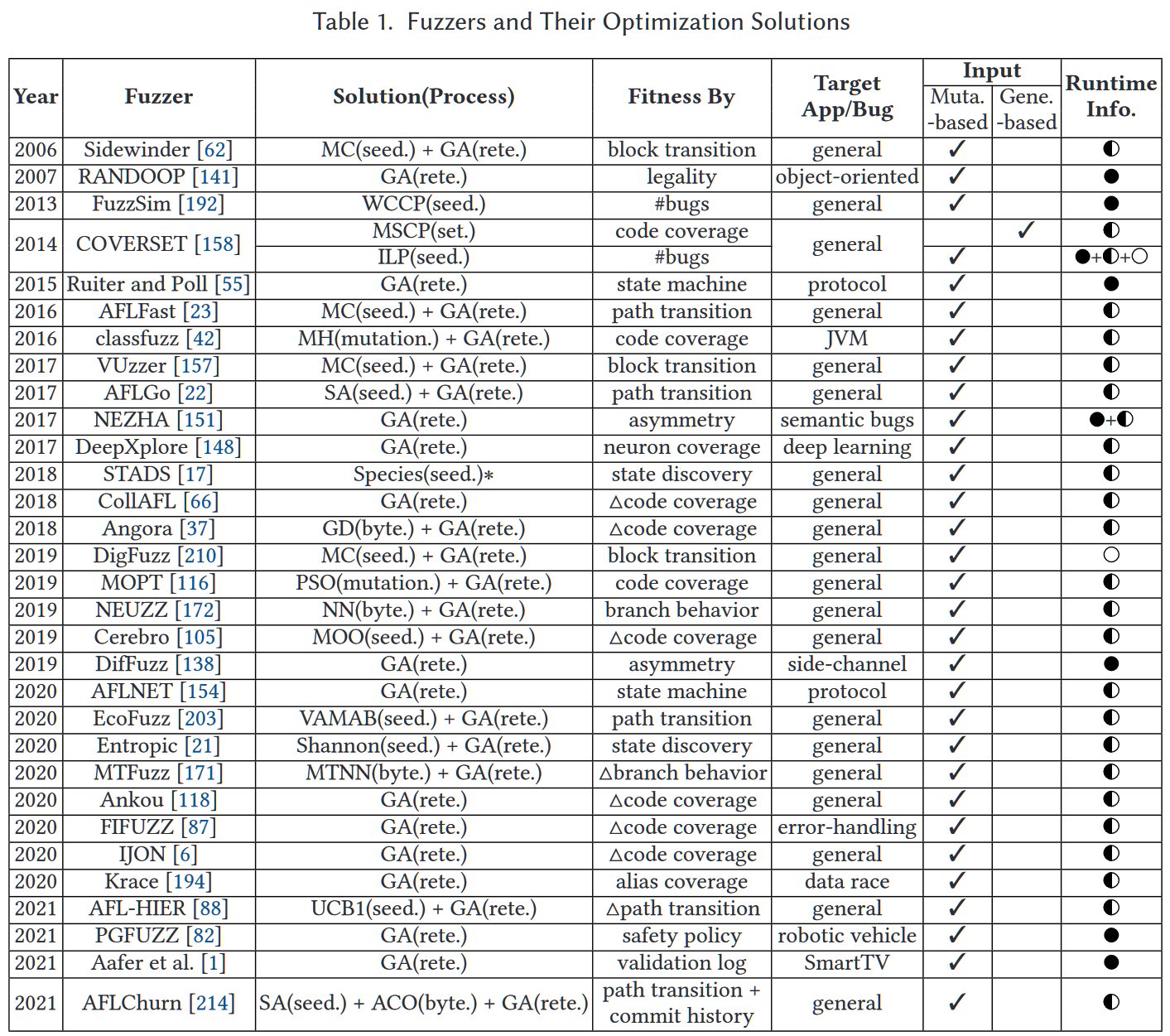
Solution:
**MC:**Markov Chain
**MSCP:**Minimal Set Cover Problem,最小集合覆盖问题; Tutorial-覆盖问题
**ILP:**Integer Linear Programming Problem,整数规划问题;
**WCCP:**Weighted Coupon Collector’s Problem,彩票收集问题;
**VAMAB:**Variant of Adversarial Multi-Armed Bandit,对抗性多臂老虎机的变种;
**UCB1:**Upper Confidence Bound算法,解决MAB问题的一种算法;
**MH:**Metropolis-Hastings采样;
**PSO:**Particle Swarm Optimization,粒子群优化;
**Shannon:**香农理论;
*Species:**Models of Species Discovery,物种发现模型;
**ACO:**Ant Colony Optimization,蚁群优化;
**SA:**Simulated Annealing,模拟退火算法;
NN: 神经网络;
**MTNN:**Multi-task Neural Networks,多任务NN;
**GA:**Genetic Algorithm,遗传算法;
**GD:**Gradient Descent,梯度下降;
**MOO:**Multi-objective Optimization,多目标优化;
**R:**Random,随机。
**set:**Seed Set Selection
**seed:**Seed Schedule
**byte:**Byte Schedule
**mutation:**Mutation Schedule
**rete:**Seed Retention->将测试过程中生成的有价值的input加入population

Input space optimization
上一节描述了fuzzer可以通过优化输入的生成来提高效率,这一节讲解其如何通过减少输入空间来优化。
Fuzzer可以将输入中的相关bytes分组,并对每组应用特定的mutator。假设一个输入包括a×b个字节,并被平均分成a个部分;那么在解决一个特定的路径约束时,fuzzing的搜索空间是$a\times256^b$,而不是$256^{a\times b}$。
相关联的字节可以是构建相同数据结构的字节[16, 201],影响相同路径约束的字节[37, 38, 65, 67, 157, 160, 187],或者符合语法的相同部分[78, 115, 120, 136, 181, 197, 212]。Mutator包括字节突变(例如,比特翻转、字节删除和字节插入)[23, 206]和块突变(例如,块替换、块删除和块插入)。

如上图所示,输入被分为了变量i、k和数组a,如果前面的条件满足(line13),则当判断到14行时,整个搜索空间就只剩1bytes了。例如,如果在全局输入空间对上图(a)中的line14的条件进行检验,fuzzing需要生成$256^{11}$个输入来遍历所有可能的情况(输入有11个字节)。但如果根据源码分析,只有第11个字节才影响a[2]的值,那么只需要变异这一个字节即可,故只需要生成256个输入就可以遍历所有可能情况。

一种特殊的输入是高度结构化的输入,它被用于协议实现、文档对象模型(DOM)引擎和编译器等应用。如图上图所示,cJSON解析器要求一个输入的片段以某些特定的字符开始,如果一个输入违反了这个要求,那么这个输入就不允许检查解析器所保护的功能。
1. Byte-constraint Relation
对于大多数路径约束,它们只受输入的一小部分影响。如果fuzzer只对相关的字节进行变异,那么通过减少输入的搜索空间,fuzzing的性能可以得到明显的改善(如上图a),这就是byte-constraint relation。
在获得Byte-constraint relation后,一个简单的变异方案是随机地变异相关的字节[67, 157, 187]。一个更统一的方法是将一个字节的值分别从0到255设置[172]。然而,这两种方案是无效的,因为它们并不了解其生成的输入的质量。如果byte-constraint relation的推断过程可以获得程序中比较指令的值,fuzzing就可以突变相关的字节,并选择在通过路径约束方面取得进展的输入。此外,fuzzer可以利用梯度下降算法来突变相关字节并逐渐解决路径约束[37, 38]。
1.1 Dynamic Taint Analysis
动态污点分析,Dynamic taint analysis (DTA),是一种常见的技术,用于建立输入字节和路径约束之间的关系。DTA在输入中标记某些数据,并在执行过程中传播这些标签,如果程序中的一个变量获得了一个标签,该变量就会被连接到具有该标签的数据上。Fuzzer[37, 38, 67, 157, 160, 187]一般利用DTA在输入字节和安全敏感节点(系统/库调用,条件跳转)之间建立关系。
DTA需要大量的手工工作,并且由于隐含的数据流,也可能导致不准确的关系。
1.2 Relation Inference
由于fuzzing用许多测试用例测试目标程序,一个轻量级的解决方案是在运行时推断bytes relation。一种方法是观察一个字节的突变是否改变了一个变量的值[65]、一个比较指令的结果[7, 103, 200]或一个分支的命中率[101],如果改变了,该字节就会分别与该变量、比较指令或分支相联系;另一种推理方法是基于深度学习[172]在输入字节和分支行为之间建立近似的联系。
2. Concolic Execution
Concolic Execution也被成为动态符号执行,同时利用符号执行和fuzzing的技术被称为hybrid fuzzing或whitebox fuzzing。
Hybrid fuzzing一个改进是优先选择最难最复杂的路径让Concolic Execution解决[210]。除了路径选择,Hybrid fuzzing的性能还可以通过开发近似的SMT约束条件求解器来提高;约束解算器也可以根据目标的特点进行改进。在嵌套条件方面(如图4(a)中的第13-15行),Pangolin[81]提出了多面体路径抽象来解决嵌套路径约束。多面体路径抽象保留了历史约束的解空间,并重用该解空间来满足当前路径约束的可达性。例如,为了解决图4(a)第14行的约束,输入必须首先满足第13行的条件。为了在需要高度结构化输入的程序中利用混合模糊法,Godefroid等人[71]首先将语法中的token符号化为符号变量。然后,他们使用上下文自由约束解算器来生成新的输入。
3. Program Transformation
对于fuzzing来说,程序转换的目的是去除阻碍fuzzing发现更多执行状态的合理性检查。通过移除这些检查,fuzzing可以探索目标程序中的深层代码并暴露出潜在的bug[150]。去除后会引入许多错误位置的假阳性,这可以通过符号执行来进一步验证。因此,程序转换通过专注于可能潜在触发bug的输入来减少搜索空间。
4. Input Model
例如像协议处理、DOM引擎、JS引擎、PDF阅读器、系统调用或编译器等程序都需要高度结构化的输入,input model代表着构建高度结构化输入的一系列规则,包括结构、格式、数据限制等。为了生成满足规范的输入,生成过程限制只能做特定的操作,如果一个输入违反了目标程序的语法或语义,该输入将在早期阶段被程序拒绝,换句话说,input space要受制于input model。
4.1 Accessible Models or Tools
许多fuzzer通过Accessible Models或者现有的工具来生成有效输入,由于规范的解析很复杂,所以容易出错。图4(b)中的cJSON解析器是对JSON规范的实现,由于对不同数据类型的复杂解析,它虽然简单,但却容易出错。**因此,研究界已经开源了一些用于高度结构化输入的工具,例如QuickCheck[50]和ANTLR[146]。**例如,NAUTILUS[5]和Superion[186]基于ANTLR生成新的输入。然后,NAUTILUS和Superion都使用代码覆盖率来优化变异过程。在某些情况下,input model可以只是生成的数据符合的类型(例如,API参数或物理信号的类型)[1, 41, 70, 179]。例如,网络物理系统(CPSs)的执行器的数据可以是二进制的开或关[41]。
4.2 Integration of Implementations
另一种有效方法是将fuzzing与目标应用程序的实现相结合[64, 89, 173]。这种整合允许fuzzing通过定制输入生成过程来检查目标应用程序的预期属性。例如,TLS-Attacker[173]创建了一个框架,可以根据每个片段的类型突变输入,并操纵协议信息的顺序。这个框架包括一个完整的传输层安全(TLS)协议实现。
4.3 Intermediate Representation
一个更复杂的方法是将input model转换为中间表示法(IR)。对于高度结构化的输入,对原始输入文件的突变过于复杂,无法保持语法和语义,因此,研究人员将原始文件翻译成IR,使其更简单和统一。Fuzzer对IR进行突变,然后将突变后的IR再翻译成原始输入格式,这种变异策略可以保持句法或语义的正确性,并产生更多不同的输入。例如,IR被用来测试数据库管理系统(DBMS)[212],检查DOM引擎[197],或模糊不同的语言处理器(例如,编译器或解释器)[43]。
5. Fragment Recombination
片段重组的基本思想是将输入文件分成许多小块(即片段),然后通过合并不同输入文件的小块来生成一个新的输入文件。每个片段都符合输入的规格,因此重新组合的输入文件在语法上是正确的。理想情况下,重新组合的输入文件将行使一个新的执行路径或暴露出一个新的错误。
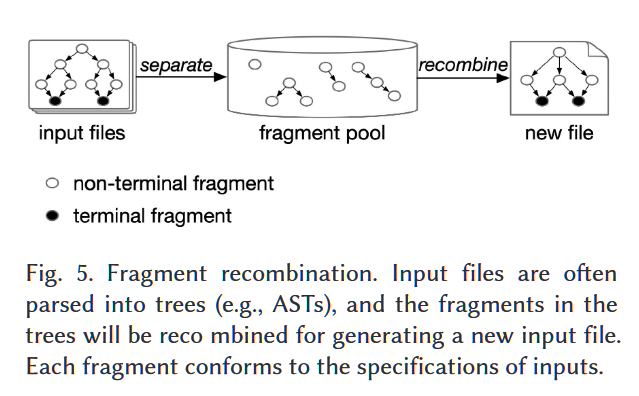
如图5所示,fuzzer首先将输入文件解析成一棵树(如抽象语法树(AST)),它保持了句法的正确性。为了正确解析输入,输入语料库必须是valid的[78, 180, 185, 199] ,其可以从网络上下载。
除了有效的输入,fuzzer也会收集有问题的输入,这些输入之前已经引起了无效的行为[80,99,145] 。基本假设是,在输入已经发现错误的位置或附近,可能仍然存在新的错误[80]。有问题的输入已经行使了复杂的执行路径,导致无效的行为。因此,片段的重新组合可能会行使相同或相邻的复杂路径,这有助于fuzzer探索深层代码行。在第二阶段,输入文件被分离成许多片段,这些片段被储存在片段池中。因为模糊分析器将输入解析成AST,所以片段可以是包含非终端的子树。当重组片段时,要求新生成的输入文件在语法上是正确的。因此,模糊器基于随机选择[80, 120, 199]、遗传算法[180]或机器学习[185]来重组句法兼容的片段。除了句法上的正确性,语义上的正确性对fuzzing的有效性也有很大影响。例如,为了生成句法和语义正确的JavaScript输入,CodeAlchemist[78]用汇编约束来标记片段。也就是说,只有当约束条件得到满足时,不同的片段才会被合并。
6. Format Inference
如果input model无法访问,推断输入的格式是产生有效输入的一个有效方法。此外,一个input model只能生成具有特定格式的输入,为了支持更多格式的输入,开发者必须利用新的input model,并在生成输入时选择相应的input model。因此,格式推理比基于模型的方法更具可扩展性。
6.1 Corpus-based
为了推断格式,一个直接的方法是向有效的输入语料库学习。由于缺乏input model,研究人员建立端到端的深度学习模型来替代input model。RNN是fuzzer生成结构化输入的一个较好的深度学习模型[74, 79, 111, 112]。然而,通过使用深度学习来代替input model的方案可能会受到生成无效输入的影响。例如,DeepFuzz[112]生成有效语法输入的最高比率仅为82.63%。
为了提高有效输入的生成率,需要对训练数据进行相应的改进。例如,在生成PDF文件时,训练数据是由PDF对象的序列组成的,而不是文本数据。对于智能合约,训练数据是关于交易的序列[79],类似地,LipFuzzer[208]训练对抗性语言学模型以生成语音命令,其中训练数据是通过语言结构呈现的。此外,fuzzing可以根据有效的输入语料库合成一个context-free grammar(例如,重复和交替等规则属性)[12],然后利用合成的语法来生成高度结构化的输入。
基于语料库的解决方案要求训练数据全面覆盖输入规范,这可能并不实际。此外,它不使用来自内部执行状态的知识(例如,代码覆盖率),这可能导致低代码覆盖率。
6.2 Coverage-based
**从本质上讲,输入的格式表明输入中不同字节之间的关系。**因此,在代码覆盖率的基础上,fuzzer推断字节与字节之间的关系,以促进fuzzing过程。
- GRIMOIRE [16]使用代码覆盖率来推断目标程序所需的格式,它的目的是识别输入的格式边界。具体来说,它改变了输入中的一些字节,并检查这些改变是否会导致不同的代码覆盖率。如果代码覆盖率保持不变,则可以随机地改变该字节。否则,这些位置就需要仔细地进行变异;
- ProFuzzer[201]首先定义了六种数据类型,涵盖了大多数输入内容。然后,根据边缘覆盖率的分布,它推断出每个字节的类型,并将属于同一类型的连续字节合并。
6.3 Encoding Function
与上述所有专注于输入的方法不同,一些fuzzer聚焦于搜索编码输入格式的代码区域。因为这样的代码区通常负责生成结构化的输入,所以fuzzer在编码输入的格式之前进行变异操作。尽管PUT的源代码可能无法访问,但其生成结构化的输入的相应实现通常可以访问。
举例来说,物联网设备中的大多数是通过配套的应用程序控制的,这些应用程序生成与目标设备通信的消息[36]。通过定位与编码格式相关的代码区域,可以对函数的参数[36, 159]或计算格式的指令[92]进行变异操作。例如,IoTFuzzer[36]钩住此类函数,并对这些函数的参数数据进行突变。
Format inference主要用于满足程序所需的句法格式,但其仍可能生成错误的数据。

如上图js代码所示,虽然snippet 2满足程序所需的数据格式,但line2-5有一个语义错误,原因是errf()函数未定义。
7. Dependency Inference
许多应用程序要求输入中的**数据依赖性正确**,而这些数据通常是由语句序列组成的。这些序列包括内核代码的系统调用[77, 95, 142],面向对象程序的处理器的对象[59, 117],服务/库的应用编程接口(API)[8, 83, 110],或智能合约的应用二进制接口(ABIs)[86]。一方面,这些应用大多需要在使用输入的数据之前进行定义/声明,如图6所述。另一方面,执行一些语句的输出是其他一些语句的参数数据。
7.1 Documents or Source Code
序列的数据依赖性通常是通过静态分析推断出来的。因为许多应用程序都有描述其界面的文件或源代码,研究人员根据这些资源推断出数据依赖性[8, 53, 59, 86, 110, 117]。这些资源包含了如何使用一个接口的信息和接口的预先需求。当fuzzing生成包括接口的输入时,fuzzing也需要生成接口的先决条件,否则,生成的输入将在早期阶段被拒绝。
然而,静态分析会带来很高的误报率,并且会遗漏接口的依赖关系。因此,当有机会接触到PUT的源代码时,更好的解决方案是结合静态分析和动态分析[95]。
7.2 Real-world Programs
许多现实世界的程序实现了调用接口的代码行,这些代码行已经考虑了接口的数据依赖性。因此,fuzzing可以根据对现实世界程序进行的程序切片,合成调用接口的新程序[10]。
此外,通过分析那些真实世界程序的执行日志,可以推断出数据的依赖性[77, 83, 142]。执行日志明确地包含了接口的排序信息,也就是哪个接口先被执行的信息。此外,执行日志还隐含了接口之间的参数依赖性信息。为了获得显性和隐性信息,在执行真实世界的程序时,fuzzing会钩住每个接口并记录所需的信息。
8. Summary
下表描述了减少搜索空间的方法和用于分组输入字节的关系,其方法都减少了输入空间:

Automation
自动化分为三个部分:自动化运行PUT;自动化检测是否发生了bug;更快的运行速度。针对这三个部分:
- 大多数fuzzer已经成功地自动化运行命令行软件,但它们不能直接用于其他目标,如硬件或多语言软件;
- 目前fuzzing一般使用crash作为是否发生Bug的检测指标,但类似data race等bug可能并不会发生crash。
1. Automatic Execution of PUTs
这一段介绍了fuzzing针对不同应用场景下自动化执行程序的方法。
1.1 Command-line Programs
Fuzzing在命令行程序的测试上取得了巨大的成功。
Fuzzing在一个子进程中运行PUTs,然后将程序需要的参数和输入传递给它。为了提高执行速度,fuzzing不会重复执行测试一个PUT的所有步骤。相反,它克隆了一个子进程,以便跳过预处理步骤,如将程序文件加载到内存中等。
通常,fuzzing对所有测试只采取同一个命令行选项,也就是说,所有生成的输入都使用同一个命令行参数。因为不同的选项表示不同的代码覆盖率,所以一个彻底的测试需要在fuzzing期间列举所有的命令选项。一个有效的方案是,如果一个输入对一个选项无效,fuzzing会跳过对所有其余选项的测试[176]。这个方案的一个重要观察点是,如果一个输入对一个选项无效,那么这个输入将使所有其他的选项失效。
1.2 Deep Learning Systems
对于深度学习系统,输入就是training data、test data甚至是深度学习模型。输入的fitness可以是neuron coverage(神经元覆盖率)、loss function或者operator-level coverage。
对于深度学习系统,fuzzing不仅检测其可能出现的错误,还可以检测其鲁棒性。
1.3 Operating System Kernels
对于操作系统,其更为复杂,内核包括许多中断和内核线程,导致非确定性的执行状态。Fuzzing一般选择用hypervisor虚拟机(QEMU、KVM等)来运行目标内核,同时通过Intel的Processor Trace (PT)技术来获取代码覆盖率。
操作系统的输入通常是文件系统镜像(file system image)或系统调用序列,fuzzer可以通过对内核进行数据独立性分析后生成对应的系统调用序列来测试内核,然后检测该序列的运行情况来判断结果。另一种fuzzing操作系统内核的方法是模拟外部设备,由于内核与仿真设备进行通信,fuzzer可以产生输入来测试内核中的驱动程序。
1.4 Cyber-Physical Systems
Cyber-Physical Systems(CPS),信息物理系统,物理和软件组件在不同的空间和时间尺度上运行。其应用包括自动汽车系统、医疗监控、过程控制系统、机器人系统、自动飞行员电子设备、智能电网、交通物流系统等。
CPS包括两个主要部件,计算单元和物理进程。一个广泛使用的计算单元是可编程逻辑控制器(PLC),它控制执行器来管理物理过程并接收来自传感器的输入。因此,在对CPS进行fuzzing时,fuzzer可以取代PLC,直接通过网络向执行器发送大量指令[41]。另一种fuzzing测试CPS的方法是检查PLC的控制应用程序和运行时间[179]。然而,PLC的二进制文件不能像摸索命令行程序那样被摸索。因为PLC应用程序有各种二进制格式,并与物理组件进行复杂的通信,这些应用程序的自动化程度各不相同。基于对PLC二进制文件及其开发平台(如Codesys)的分析,在PLC设备上运行PLC二进制文件时,有可能自动进行fuzzing[179]。
1.5 Internet of Things
对物联网的fuzzing包括了模拟(emulation)和网络层级测试(network-level test)。仿真器(emulator)[34, 205]可以模拟执行原本在物联网固件上运行的程序,在仿真器的帮助下,fuzzer以灰盒方式运行目标程序[211]。
另一方面,网络层面的fuzzing以黑箱方式检查物联网设备,由于物联网设备可以通过网络与外界进行通信,fuzzer自动向物联网设备发送消息(请求),并等待物联网设备的执行结果(响应)[36, 63, 159]。通过对响应进行分类,fitness是类别的数量,也就是说,目的是为了探索更多的类别[63]。
1.6 Applications with Graphical User Interface
GUI程序的执行速度比命令行程序慢很多,而在fuzzing中执行速度又很重要,故一般对GUI程序的测试都将其替换为一个更快的命令行执行方法。举例来说,fuzzer可以对用户界面的互动进行建模,从而为Android应用程序生成事件序列。此外,fuzzer还可以利用准备好执行环境的约束条件,直接调用图形用户界面中的目标函数。
1.7 Applications with Network
一些例如智能合约、协议处理、云服务、安卓原生服务、智能驾驶等应用程序通过网络接受输入,因此,输入可以在本地生成,而目标应用程序的执行可以在远程进行。自动测试的效率依赖于生成的输入的质量,以及反映执行状态的fitness。例如,智能合约的输入是合约交易的序列,即不同账户之间的信息。当收到交易时,智能合约中的功能在其区块链的基础设施上执行。
2. Automatic Detection of Bugs
这一段介绍了如何自动的检测是否发生了bug,介绍了6中成功被fuzzing检测的bug:
2.1 Memory-violation Bugs
Memory-violation,内存损坏,是一种最古老又最严重的安全bug,其可以分为两类(如下图):
- spatial safety violations:out-of-bounds,内存越界访问,如(a);
- Buffer overflow是Out-of-bounds的一种经典样例,Dowser [76]认为其主要由于在循环中访问数组引起。为了检测循环中的缓冲区溢出,Dowser对循环中访问缓冲区的指令进行排序,并对行使较高等级访问的输入进行优先排序。然后,它使用污点分析和concolic execution来解决所选输入的路径约束。由于Dowser专注于循环中的数组,因此只需要对少量指令进行检测。这种关注提高了污点分析和concolic execution的执行速度。
- temporal safety violations:UAF,如图(b);
- UAF是temporal safety violation的经典样例,其包含了分配、释放和再次使用三个步骤,这种错误模式促使UAFL[184](ICSE‘2020)生成能够逐渐覆盖潜在UaF的整个序列的输入,潜在的UaF序列是通过基于错误模式的静态类型状态分析得到的。

尽管有很多方法被发明出来用于减轻这两种漏洞的影响,但由于成本以及低兼容性问题,几乎没有在实际上使用。
2.2 Concurrency Bugs
并发错误被分为以下几类:
deadlock bugs
发现死锁的一个解决方案是检测锁序图,其中每个节点代表一个锁[4],如果图中存在一个闭环,就会检测到一个潜在的死锁[90]。为了提高循环检测的效率和可扩展性,MagicFuzzer[27]迭代地删除图中的锁,如果这些锁不包括在任何循环中。然后,MagicFuzzer根据一个随机调度器检查剩余的周期。
non-deadlock bugs
atomicity-violation bugs:
违反原子性原则bug,如下图(a)所示,line3需要在line1之后运行,但由于Thread 2在中间改变了
p->info的值,导致产生错误。ATOMFUZZER[144]观察到一个典型的错误模式,即一个原子块内的锁被两个线程反复获取和释放。具体来说,如果一个原子块内的线程t要获取一个之前已经被t获取和释放的锁L,ATOMFUZZER会延迟线程t的执行,并等待另一个线程t ′获取该锁L,当另一个线程t ′在线程t的延迟期间获取该锁L时,就是一种原子性违反。
order-violation bugs:
内存被以错误的顺序访问,如下图(b)所示,Thread2中的mThd->State在线程1中的mThd初始化之前被执行,这就产生了一个错误,使用未初始化的变量。

更为普遍的说 ,并发错误的发生是由于线程的不正确交织。挑战在于,并发程序可能有太多的交错状态,无法逐一检查(即状态爆炸问题)。CalFuzzer[166]基于以下事实缓解了状态爆炸问题:一些交织是等价的,因为它们来自非交互指令的不同执行顺序。这种等价性表明,对它们的执行将导致相同的状态。CalFuzzer随机选择一组线程,这些线程的后续指令互不交互,并同时执行这些指令。因此,CalFuzzer[166]可以更有效地检查不同的交织。
2.3 Algorithmic Complexity
Algorithm complexity (AC)漏洞指的是当一个算法的最坏情况下的复杂性导致大大降低性能,这可能导致拒绝服务(DoS)攻击。

如上图所示的代码,array = [8,5,3,7,9]和[1,5,6,7,9]两种输入导致quicksort的算法复杂度是完全不同的。
- SlowFuzz[152]通过引导fuzzing向增加执行指令数量的方向发展,来检测AC错误;
- HotFuzz[15]通过最大化单个method的资源消耗来检测Java method中的AC错误;
- MemLock[44]根据边缘覆盖率和内存消耗这两个指标来检测AC错误,它将fuzzing引向那些能够发现更多边缘或消耗更多内存的输入;
- 前面提到的fuzzer直接生成最差性能的输入(WPI)来发现AC错误。相反,Singularity[190]根据对这些WPI总是遵循一个特定模式的观察,合成了用于生成输入的程序。
2.4 Spectre-type Bugs
有零漏洞是一种微架构攻击,利用错误预测的分支推测来控制内存访问[139]。例如,在图10中,攻击者可以为变量input发送几个in-bound值,这将训练分支预测器来推测第2行的检查是否总是真的。当攻击者为输入发送一个超限值时,预测器将错误地预测分支行为,第3-4行被投机性地执行(即在没有第2行检查的情况下被执行)。由于输入实际上并不满足第2行的检查,第3-4行的执行会导致缓冲区超读。
因此,SpecFuzz[139]对目标程序进行分析,以模拟投机执行,它可以强制执行错误预测的代码路径。然后,错误预测的路径中的任何无效内存访问都会被触发。

2.5 Side Channels
侧信道漏洞通过观察系统的非功能行为(如执行时间)泄露秘密信息。例如,如果一个秘密是语句 “if (a > 0){…}else{…}”中的变量a,人们可以观察then-branch和else-branch的执行时间来判断a的值是否大于0。一种特殊的边信道被称为JIT诱导的边信道,它是由及时优化(JIT)引起的[25]。与前面提到的Spectre型bug类似,人们可以反复运行程序来训练JIT编译器,使其优化the then-branch或else-branch的执行时间。然后,训练过的分支(如the then-branch)和未训练过的分支(如else-branch)的执行时间将有足够的偏差,可以被观察到。因此,变量a的秘密值被泄露了。
2.6 Integer Bugs
当一个算术表达式的值超出机器类型所决定的范围时,就会发生整数溢出/下溢漏洞。另一方面,整数转换错误发生在将一种整数类型错误地转换为另一种整数类型时。
为了检测整数bug,SmartFuzz[132]根据不同的整数bug在符号仿真中加入了特定的约束。然后,符号解算器打算生成可能触发整数错误的具体输入。
3. Improvement of Execution Speed
提升运行的速度对fuzzing非常重要,因为fuzzing会在time budget上会运行多个测试样例。
3.1 Binary Analysis
作为一个预处理过程,fuzzing主要利用静态工具来获取执行状态,因为静态工具为fuzzing提供了高执行速度[58, 134]。一个广泛使用的静态分析工具是LLVM[113],它在编译过程中对程序进行分析。
当面对不开源应用时,传统的额二进制插桩工具(如Dyninst)应用到fuzzing上时时间开销过大,为了解决这个问题:
- RetroWrite[58]提出使用基于可重构汇编的静态二进制重写技术。它的重点是通过利用PIC的重定位信息对汇编文件进行仪器化的64位独立代码(PIC)的二进制文件。由于RetroWrite可以对内联的代码片段进行检测,因此性能开销有所降低。尽管很快,RetroWrite只支持64位PIC二进制;
- 为了维护低运行时开销和可扩展性,FIBRE[134]通过四个IR修改阶段简化了代码插桩过程。这四个阶段通过静态重写、内联、跟踪寄存器的有效性和考虑各种二进制格式来检测程序。上述重写技术只重写一次二进制文件,这可能导致不健全的二进制重写,特别是对于剥离的二进制文件[189];
- 为了解决这个问题,STOCHFUZZ[209]基于模糊处理重复执行目标程序的事实,提出了增量和随机重写技术。具体来说,STOCHFUZZ对目标二进制文件进行多次改写,并逐步修复之前改写结果所带来的问题。
3.2 Execution Process
程序执行速度也可以提高。
- UnTracer[133]观察到,在模糊处理过程中产生的大多数测试用例并没有发现新的覆盖范围。这表明,追踪所有的测试用例(AFL使用)会产生大量的运行时间开销。因此,UnTracer只跟踪覆盖率增加的测试案例,以提高执行速度。这是通过在基本块的开头插入中断来完成的。当一个块被检查时,UnTracer会删除该块的插桩代码,这样将来执行时就不会在该块被中断;
- 由于block coverage失去了执行状态的信息,CSI-Fuzz[216]利用边缘覆盖来改进UnTracer;
- Zeror[213]通过在Untracer-instrumented二进制和AFL-instrumented二进制之间自适应切换来改进UnTracer。对于hybrid-fuzzing,concolic execution被用来解决路径约束。然而,concolic execution中的符号模拟在制定路径约束时很慢,这是混合模糊法在扩展到现实世界应用时受到影响的主要因素;
- QSYM[204]通过删除一些耗时的组件,如IR翻译和快照,缓解了性能瓶颈。此外,它只收集和解决了一部分路径约束。尽管由QSYM生成的具体输入可能不是路径约束的精确解,但QSYM使用fuzzing通过改变这些具体输入来搜索有效输入;
- Intriguer[46]观察到,由于QSYM解决了许多不必要的约束,所以QSYM仍然存在性能瓶颈。然后,Intriguer对更多的相关指令进行了符号仿真,这是由动态污点分析决定的。除了插桩和hybrid-fuzzing,另一个优化是提高并行模式下的执行速度。Xu等人[195]观察到,AFL[206]在120个内核上并行运行时,速度明显减慢。这促使他们设计新的操作原语来提高执行速度。
3.3 Various Applications
除了一般的应用,fuzzing也被用来检测不同领域目标的缺陷,如物联网、操作系统内核和虚拟机监视器(VMM)。由于这些目标通常有特殊的功能,所以模糊测试是为目标定制的,以便以有效的方式进行测试。
虽然仿真是一种很有前途的模糊物联网固件的方法,但全虚拟化的吞吐量很低。全虚拟化的运行时间开销主要来自于翻译内存访问的虚拟地址和仿真系统调用。
- FIRM-AFL[211]通过结合用户模式虚拟化和全系统虚拟化来减轻开销,它主要在用户模式仿真中运行程序;
- 为了对VMM进行模糊处理,Schumilo等人[162, 163]设计了一个定制的操作系统和一个快速的快照恢复机制,以便有效地进行模糊处理。
- 至于文件系统,由于image太大,突变整个磁盘image会大大降低模糊处理的吞吐量。JANUS[196]只对种子image的元数据进行了修改;也就是说,它利用了结构化数据的特性。这个解决方案减少了输入的搜索空间,从而提高了吞吐量;
- 操作系统内核也可以通过外部设备被破坏,也就是说,漏洞是沿着硬件-操作系统边界发生的。为了检测设备-驱动通信中的缺陷,PeriScope[174]提出了基于内核的页面故障处理机制的Fuzz;
- Windows的应用程序与Linux的不同,因为它们大量使用图形界面,而且Windows缺乏快速克隆进程的方法。WINNIE[91]合成了一个运行没有图形界面的应用程序的约束。此外,它还为Windows实现了fork()来有效地克隆进程;
- BigFuzz[207]将数据密集型可扩展计算(DISC)应用程序转换为语义等价的程序,该程序独立于DISC框架。由于DISC框架引入了较长的延迟,独立于框架的执行方式显著提高了执行速度。
Gap
综上所述,目前fuzzing解决的三个gap:
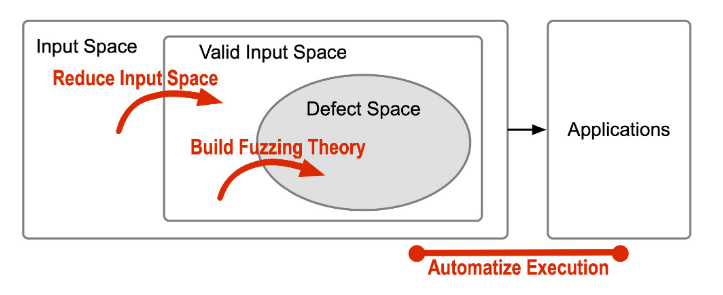
Gap 1: Sparse defect space of inputs
在应用程序中的漏洞分布是分散的,而仅有部分特定的输入能够触发漏洞;浅显的漏洞可以在短时间内被 fuzz 到,但许多安全漏洞需要测试复杂的执行路径并解决严格的路径约束,因此一个高效的 fuzzing 算法需要同时对 待测试程序(program under test, PUTs)与 安全缺陷(security flaws)足够精通,以在一个更有可能存在漏洞的代码区域分配计算资源。
Gap 2: Strict valid input space
每种应用程序都有着自己的特定输入格式,现代程序越来越大,导致了越来越复杂的输入,因此,生成有效输入是有挑战性的。
此外,为了提高fuzzing的效率,生成的输入最好能执行不同的执行状态(例如,代码覆盖率)。这就要求fuzzing为有效输入的生成开发更先进的方案。如果没有对PUT的系统性分析,几乎不可能精确限制输入空间。例如,PDF文件的随机突变可能违反PDF的规范。模糊法需要仔细地突变PDF文件,使生成的输入属于有效输入空间。
Gap 3: Various targets
由于 fuzzing 大量重复地测试 PUTs,这需要高效的自动化方法。PUTs 与漏洞都是多种多样的,有的程序可以简单直接地被自动化地测试(命令行),但许多程序在自动化测试前都需要做大量的工作(例如硬件);此外,安全缺陷同样需要自动化的 indicator 以记录潜在的真正漏洞,程序崩溃是一个常用的 indicator 因为其可以被 OS 自动捕获,但有的安全缺陷并不会表现出崩溃(例如data race),这需要精心设计的 indicator。
PS: data race(数据争用) & race condition(竞态条件)
Direction of future research
未来可能的几个方向:
1. More sensitive fitness
提高代码覆盖率的效率和效果,尤其是其敏感性(Fitness的敏感性表明其区别不同程序运行状态的能力)。最近,研究人员意识到,代码覆盖率在发现复杂的bug方面有其局限性。因此,他们通过引入通过分析bug获得的信息(如危险代码区域)来扩展代码覆盖率。未来的工作可以分析bug,并根据bug的特征进行检测,特别是分析那些逃避当前fuzzing的bug。
2. More sophisticated fuzzing theories
目前的fuzzing理论研究都是部分地定制了fuzzing的某个过程(第3节)。大多数现有的工作旨在制定seed schedule,而关注其他fuzzing过程的工作则少得多。由于fuzzing的复杂性,现有的工作中很少有制定整个fuzzing过程的。
从数学理论上制定整个fuzzing过程是non-trivial的。然而,制定一个以上的fuzzing过程是可能的,如博弈论,其同时考虑seed schedule和bytes schedule。
更长远来看,关于fuzzing的理论限制也可以是研究方向(例如,灰盒fuzzing的限制)。另一方面,用多种类型的fitness来制定fuzzing过程是建立更复杂的fuzzing理论的另一种方式。例如,未来的工作可以同时考虑错误的到来和状态的转换来制定fuzzing过程。
3. Sound evaluation
少部分研究工作关注评价的合理性,但没有得出确切的结论(3.6节)。这些工作只为合理的评价提供了建议,如时间预算或评价指标,更多的问题仍然有待回答。
- 我们应该使用合成的bug还是真实世界的bug作为评价体例?
- 统计测试是区分两种fuzzing技术的最终答案吗?
- 终止fuzzing的合理时间预算是什么?
- 当不存在用于比较fuzzer时,我们如何评估特殊的目标应用,如硬件?
4. Scalable input inference
如果在fuzzing过程中使用特定格式或数据依赖性,其效率可以得到显著提高。静态分析被广泛用于格式推断和数据依赖性推断。然而,静态分析是特定于应用程序的;也就是说,推理方法的实现需要考虑不同应用程序的特点。目前,动态分析侧重于格式推断,很少有作品在数据依赖性推断方面做出努力。具有动态分析的推理方法有可能被用于多种应用;也就是说,动态分析比静态分析更具可扩展性。更多的研究可以集中在基于动态分析的数据依赖性推断上。
5. Efficient mutation operators
几乎所有的fuzzer在fuzzing过程中都使用了固定的mutator。也就是说,fuzzer根据目标应用程序的特点提前设计了一些mutator,并且在摸索过程中并不改变mutator。有几项工作打算优化mutator,但没有人关注可改变的mutator,是否有可能设计出在fuzzing过程中可以改变的mutator来提高性能?因为mutator schedule与bytes schedule密切相关,所以在设计mutator时考虑到bytes schedule可能是有希望的。此外,高度结构化输入的mutator可能对一般应用有不同的属性,因此,高度结构化输入的mutator schedule可能也值得研究。
6. More types of applications
Fuzzing在检测命令行程序的错误方面取得了巨大成功。研究人员也在对更多类型的应用程序进行fuzzing方面做出了许多努力(第5.1节)。由于不同应用程序的复杂性,fuzzing在实际检测更多类型的应用程序时有其局限性。例如,一些工作探索了对网络物理系统进行fuzzing的可能性,但fuzzing的能力是有限的[41, 179]。由于执行速度对fuzzing至关重要,因此hard-fuzzing应用的一个潜在方向是提高其执行速度。
7. More types of bugs
Fuzzing已经成功地检测到了诸如memory-violation bugs, concurrency bugs, 或者algorithmic complexity bugs。然而,它很难检测到许多其他类型的错误,如特权升级或逻辑错误。
目前的挑战是为这些错误设计适当的指标,以便在fuzzing过程中自动记录它们。因为这种指标反映了相应的bug的特征,所以指标的设计需要研究人员对fuzzing和目标bug都有很好的理解。例如,即使触发了逻辑错误,程序也会在没有异常的情况下运行。为了设计逻辑错误的自动指标,需要对开发代码的功能需求有深刻的理解。