
Everything Old is New Again: Binary Security of WebAssembly
**时间:**2020
**作者:**Daniel Lehmann(德国斯图加特大学),Johannes Kinder(慕尼黑联邦国防大学)
**会议:**USENIX’2020
Abstract
WebAssembly是一种越来越流行的编译目标,其旨在通过严格分离代码和数据、强制执行类型和限制间接控制流,在浏览器和其他平台上安全可靠地运行代码。不过,内存不安全的源语言的漏洞仍然可以转化为WebAssembly二进制文件的漏洞。
在文本中,我们分析了什么样的漏洞在WASM二进制文件中是可利用的,以及其与本地代码的比较。我们发现,许多经典的漏洞,由于常见的缓解措施,在本地二进制文件中不再可利用,但在WebAssembly中却完全暴露。另外,WebAssembly能够实现一些独特的攻击,例如覆盖所谓的常量数据或使用堆栈溢出操纵堆。
我们提出了一套攻击原语,使攻击者(i)能够写入任意内存,(ii)能够覆盖敏感数据,以及(iii)能够通过转移控制流或操纵主机环境来触发意外行为。我们提供了一套易受攻击的POC应用程序,以及完整的端到端漏洞,其中涵盖了三个WebAssembly平台。对真实世界的二进制文件和SPEC CPU程序编译成WebAssembly的经验性风险评估表明,我们的攻击原语在实践中可能是可行的。总的来说,我们的发现表明,WebAssembly缺乏二进制的安全性,这也许是令人惊讶的,我们讨论了潜在的保护机制,以减轻由此产生的风险。
问题背景
1. WebAssembly的安全分为两个方面:
- ***Host security:***runtime环境在保护主机系统免受恶意WebAssembly代码侵害方面的有效性;
- 对host security的攻击依赖于执行错误[16, 59],因此通常是聚焦于一个特定的虚拟机(VM)。
- ***Binary security:***内置故障隔离机制在防止其他良性的WebAssembly代码被利用方面的有效性。
- 针对binary security的攻击–本文的重点–是针对每个WebAssembly程序及其编译器工具链的攻击,WebAssembly的设计包括各种功能,以确保二进制安全。例如,由WebAssembly程序维护的内存与它的代码、执行堆栈和底层虚拟机的数据结构是分开的;为了防止与type有关的崩溃和攻击,二进制文件被设计成容易进行类型检查的方式,并且在执行前静态检查类型;此外,WebAssembly程序只能跳转到指定的代码位置,这种故障隔离的形式可以防止许多经典的控制流攻击。
综合Wasm的安全机制,以及Wasm的源语言(C/C++/Rust)一般都是会对内存进行操作的,引出了如下问题:内存漏洞对Wasm二进制安全性有何影响?
Wasm的原始论文说:“在最坏的情况下,一个有错误的或被利用的WebAssembly程序会把它自己内存中的数据弄得一团糟”;Wasm的官方文档说:“常见的缓解措施,如数据执行预防(DEP)和堆栈粉碎保护(SSP),在WebAssembly程序中并不需要”。
2. Wasm的控制流:
与本地代码或Java字节码不同,WebAssembly只有结构化的控制流。一个函数中的指令被组织成良好的嵌套块,分支只能跳到周围块的末尾,而且只能在当前函数内,并且多分支只能指向在分支表中静态指定的块,不受限制的goto或跳转到任意地址是不可能的。特别是,人们不能把内存中的数据作为字节码指令来执行。因此,许多经典的攻击在WebAssembly中被排除了,例如,注入shellcode或滥用无限制的间接跳转,如x86中的jmp *%reg。
3. Wasm的间接跳转:
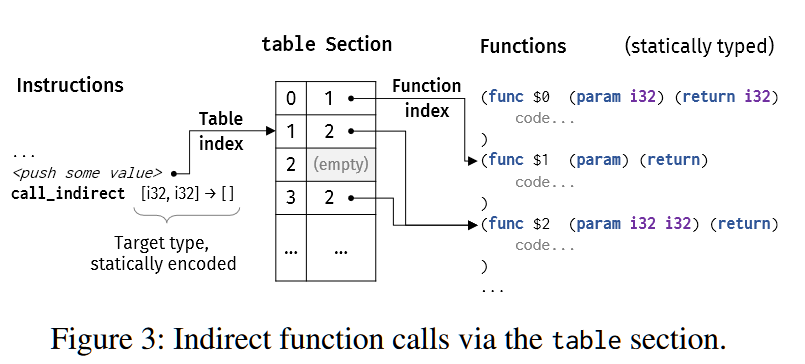
如上图所示,间接调用(目标函数的地址不确定,存储在变量或者寄存器中)需要通过table sectio来完成,左边的call_indirect指令从堆栈中弹出一个值,用来索引table section,table section将这个索引映射到一个函数,随后被调用。因此,只有当一个函数出现在table中时才能被间接调用。为了确保类型的正确性,虚拟机在执行调用前会检查目标函数是否与间接调用指令中静态声明的类型兼容,否则就会终止执行。
贡献
- 对WebAssembly的线性内存和从C、C++和Rust等语言编译的程序的使用进行了深入的安全分析,WebAssembly缺少哪些常见的内存保护,以及这如何使一些代码比编译成本地二进制时更不安全(第三节);
- 一组从我们的分析中得到的攻击原语,以及对WebAssembly生态系统所提供或不提供的缓解措施的讨论;
- 一组易受攻击的应用程序和端到端的exploit实例,显示了我们在三个不同的WebAssembly平台上的攻击结果;
- 经验证明,数据流和控制流攻击都可能是可行的,对来自真实世界网络应用的WebAssembly二进制文件以及从大型C和C++程序中编译出来的文件进行了测试;
- 讨论可能的缓解措施,以加固WebAssembly二进制文件对所述的攻击的防御(第7节)。我们公开了我们的攻击原语、端到端漏洞和分析工具,以帮助这个过程。
对Wasm线性内存的安全分析
3.1 Managed vs. Unmanaged Data
***Managed Data:***即局部变量、全局变量、评估堆栈上的值和返回地址,位于由虚拟机直接处理。
- WebAssembly代码只能通过指令与managed data进行隐式交互,但不能直接修改其底层存储。例如,可以使用
local.get 0读取local 0,但在任何时候,程序都无法看到local的实际底层地址。
- WebAssembly代码只能通过指令与managed data进行隐式交互,但不能直接修改其底层存储。例如,可以使用
***Unmanaged Data:***所有驻留在线性内存中的数据,它们完全在程序的控制之下,通常由编译器生成的代码组织。
- 将unmanaged data放在线性内存中有几个原因,因为WebAssembly只有四种数据类型,而且managed data只能容纳这些原始类型的实例,所有非标量数据,如字符串、数组或列表,都必须存储在线性内存中; 因为managed data没有地址,所以任何在源程序中曾经被使用地址的变量,例如,out parameters(使用参数指针而不是返回值来返回结果),也必须存储在线性存储器中。
- 由于许多非标量类型在源程序中作为函数范围的数据,具有动态寿命,编译器在线性内存中为call stack、heap和static data创建了一块区域。我们将把编译器在线性内存中创建的call stack称为unmanaged stack,以区别于managed evaluation stack(存放指令的中间值)和managed call stack(存放locals和返回地址)。重要的是,这意味着大量的数据位于unmanagedd的线性内存中,不在虚拟机的保护之下,而是在程序中内存写入指令的完全控制之下。
3.2 Memory layout
**Memory layout指的是stack、heap和data在linear memory中的顺序。**在linear memory中,为了保证heap可以动态生长,heap必须是放在最后的。Heap下面是stack和静态数据,由于在WebAssembly中没有只读内存(在下一节会有更多的介绍),所以在.data和.rodata之间没有区别,而且由于内存总是零初始化的,所以不需要专门的.bss部分。换句话说,.data、.rodata和.bss在WebAssembly中没有明确的区分。
在下文中,当我们提到linear memory中的data section时,我们指的是所有这些在程序的整个生命周期内有效的数据,例如,静态初始化的字符串常量、全局数组或零字节范围。
不同编译器生成的WASM内存布局如下:
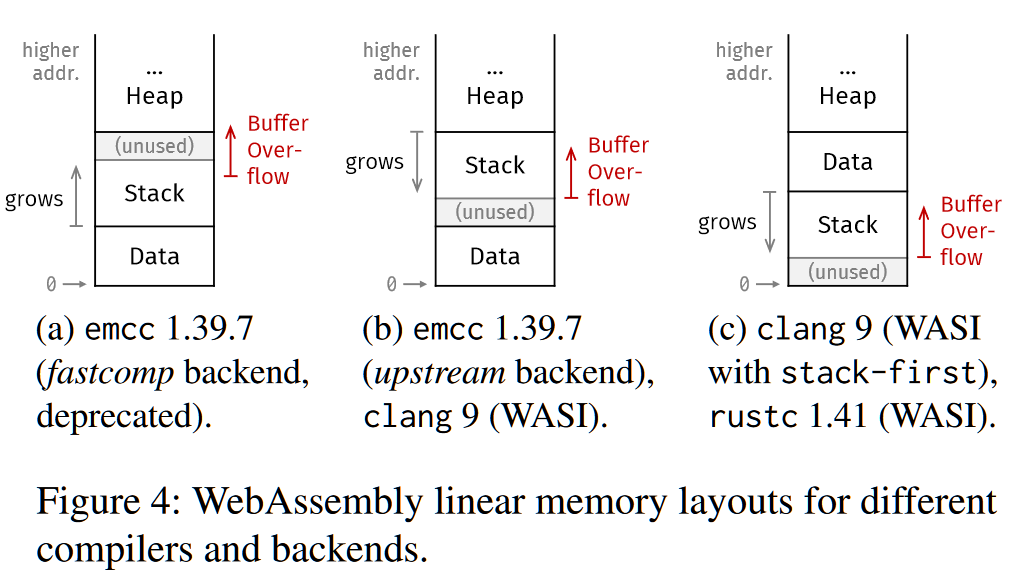
如图所示,注意到Heap的生长方向都是向上的,但Stack不一定,其根据不同布局生长方向不同。在Emscripten和Clang中,static data默认是第一位的,但使用Rust和Clang的链接器选项-stack-first,就可以使stack位于第一,data位于stack和heap之间。
3.3 Memory Protections
- WebAssembly的线性内存是一个单一的、连续的内存空间,没有任何空隙,所以每个指针∈[0, max_mem]都是有效的,只要攻击者保持在这个范围内,任何读写操作都会成功。因为不能在static data、unmanaged stack和heap上安装guard pages,一个section的溢出会无声地破坏相邻section的数据(第4节显示,缓冲区和堆栈溢出因此是WebAssembly中非常强大的攻击原语);
- 在WebAssembly中,线性内存在设计上是不可执行的,故直接jump到线性内存中没用。然而,WebAssembly不允许将内存标记为只读,相反,线性内存中的所有数据都是可写的。这是线性内存的另一个相当令人惊讶的限制,并使我们在第4节中的一个攻击原语成为可能;
- 在WebAssembly中,没有ASLR。WebAssembly线性内存的排列是确定的,也就是说,stack和heap的位置是可以从编译器和程序中预测的。即使在WebAssembly中加入某种形式的ASLR,线性内存也是由32位指针来寻址的,这很可能没有提供足够的熵来进行强有力的保护。
Attack Primitives,攻击原语
本节介绍了可用于利用编译为WebAssembly的代码中的漏洞的攻击原语,原语横跨三个方面:
- 获取写操作原语,即攻击者利用一个漏洞来实现对内存的意外写入的能力;
- 能够覆盖敏感数据;
- 覆盖数据来触发破坏安全的行为。
原则上,这三个维度的原语可以自由组合。例如,第一个维度的写原语可以覆盖第二个维度的任何数据,以触发第三个维度的任何类型的错误行为。
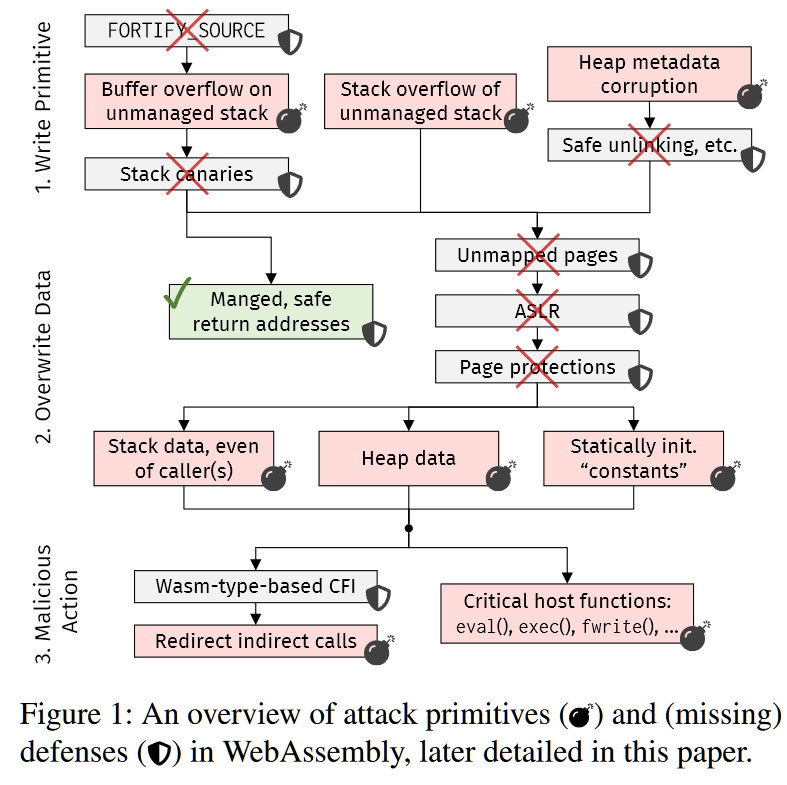
如上图所示,打叉的防御措施表明其在原生平台下一般都会使用但在WASM平台用不了。这里的一些攻击在原生平台下存在,这里关注的重点是是否可以迁移到WASM平台上;另外一些攻击原语在原生平台下是不可能实现的,但在WASM下成为了可能。
4.1 Obtaining a Write Primitive
这里,我们讨论了那些在原生平台上有有效缓解措施,但在WebAssembly中没有的攻击类型。(我们不讨论那些在WebAssembly中可能存在的、但既不新颖也不专门针对该平台的攻击原语。例如,整数溢出存在于WebAssembly,就像它们存在于x86或ARM中那样。)
4.1.1 Stack-based Buffer Overflow
与目前的看法相反,基于堆栈的缓冲区溢出在WebAssembly中是可以利用的。
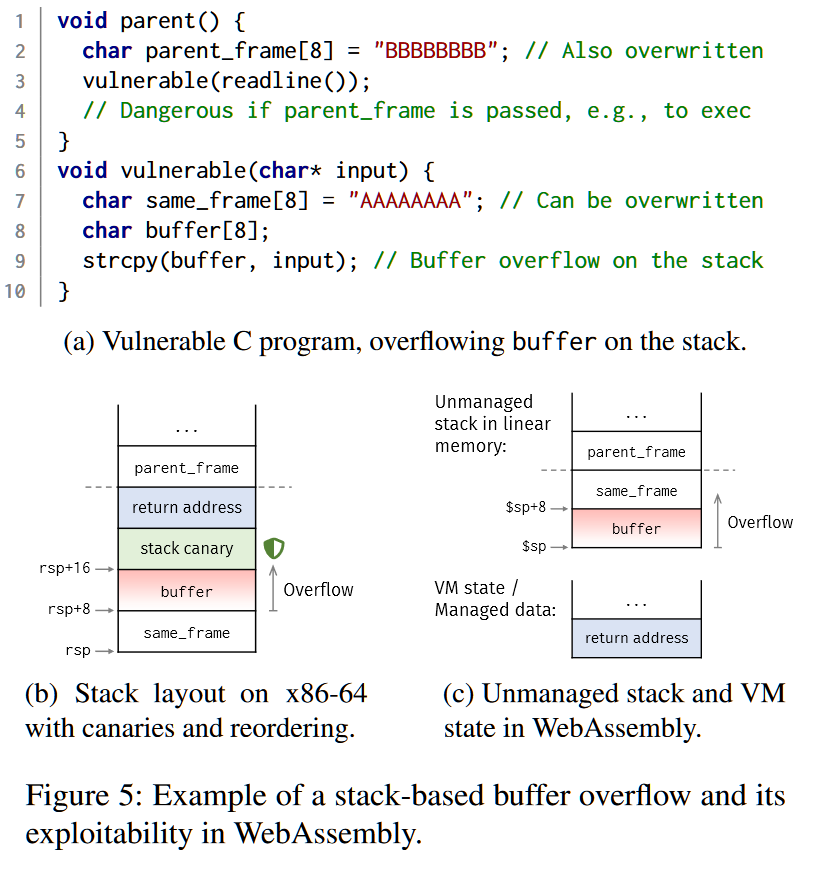
如上图所示,由于line 9没做边界检查导致buffer可以被溢出写入。
因为WebAssembly虚拟机隔离了managed data,特别是程序的返回地址,所以很容易让人产生强烈的(和错误的)安全感,正如第1节中引用的WebAssembly官方设计文档所说明的那样。然而,缓冲区溢出会损害WebAssembly中的数据,因为C语言中的部分funcion-scope的数据是存储在线性内存的unmanaged stack中的(如这里的frame数组)。
如图c所示,顶部是线性内存中的unmanaged stack,底部是VM内部存储managed data的区域。虽然底部的managed data受到了VM的保护,但unmanaged stack并没有受到保护。
事实上,在写进unmanaged stack的局部变量(如buffer)时的溢出,可能会覆盖同一堆栈中的其他局部变量,甚至是向上的其他堆栈帧中的局部变量,如parent_frame。因为溢出也可以写到父函数中的数据(如我们上面所示),甚至写到其他内存部分(如我们后面所示),所以这个原语比以前意识到的更强大,stack canary的使用会更重要。
4.1.2 Stack Overflow
另一种写原语是stack overflows,其由于过分或无限制的递归操作,或在stack上分配可变大小的本地buffer时,例如使用alloca,就会发生这种情况。如果攻击者控制了stack分配的大小,或者提供了违反递归函数内部假设的坏数据,就可能触发堆栈溢出。
在原生平台,stack overflows会导致栈生长触碰特殊的guard page保护页,接着导致程序crash;但在WebAssembly中,这种保护措施不存在于unmanaged stack中,所以攻击者控制的stack overflow可以用来覆盖stack中的潜在敏感数据。
4.1.3 Heap Metadata Corruption
Heap Metadata Corruption指的是对堆块中特殊数据的破坏(如prev和next指针)。
因为在WebAssembly中,host环境没有提供默认的分配器,编译器会包含一个内存分配器作为编译好的程序的一部分。由于WebAssembly module通常要在执行前从网上下载,分配器的代码量大小是一个重要的考虑因素,Emscripten会让开发者自己在默认的分配器(基于dlmalloc)和特定的分配器(emmalloc,其可以减少最终的代码大小)中间选择。类似地,Rust程序也可以在编译为Wasm时选择一个轻量级的分配器(wee_alloc)。
虽然标准的分配器,如dlmalloc,已经针对各种元数据破坏攻击进行了加固,但简化和轻量级的分配器往往容易受到传统攻击的影响。我们发现emmalloc和wee_alloc都容易受到元数据破坏的攻击,下面对emmalloc的一个版本进行说明。
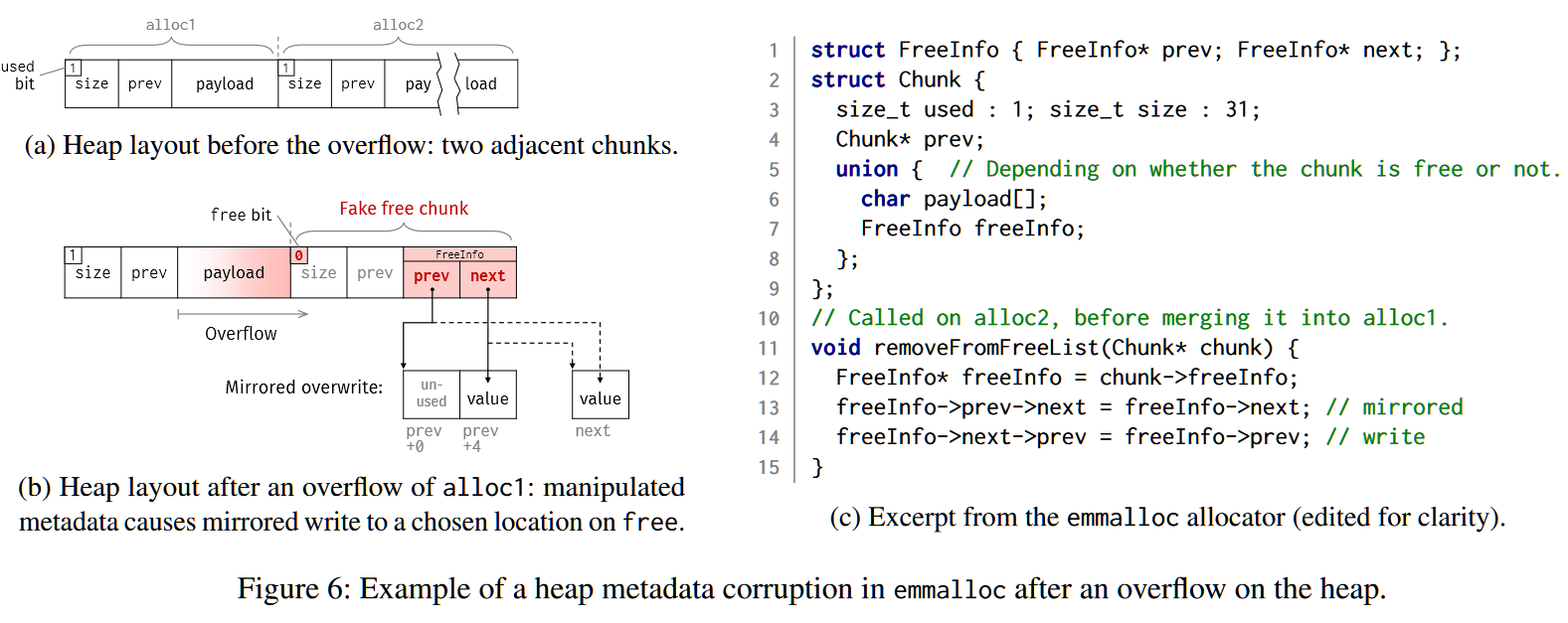
当通过调用free来释放一个内存块时,分配器会试图将尽可能多的相邻free块合并到一个更大的内存块中,以避免碎片化内存。这就导致了经典的堆溢出unlink漏洞,如上图所示,通过将相邻堆块溢出,覆盖其metadata指针。
由于emmalloc是一个first-fit分配器,它将返回空闲列表中第一个足以满足分配请求的大块,因此,两个直接跟随的分配请求在内存中就会产生两个相邻的块,如图6a中的alloc1和alloc2。图6c中emmalloc源代码的第1到9行显示,每个块的metadata开始于一个表示当前块是否空闲的位(used),该块的大小(size),一个指向前一个块的指针(*prev),最后是payload或一个FreeInfo结构。在一个正常的分配操作中,该块是空闲块的双链列表的一部分。
将alloc1中的数据溢出(例如,由于长度错误的memcpy),攻击者可以写到直接相邻的alloc2,以清除used位并建立一个 “假的 “FreeInfo结构(图6b)。最后,当alloc1被释放时,分配器检查是否有机会将新释放的块与相邻的自由块合并,alloc2会被识别为已经free了,分配器调用removeFromFreeList来解除它的链接,以准备合并这两个块。
在图6c的第13行,emmalloc在alloc2上执行unlink代码,然后将攻击者控制的下一个字段的值写入另一个FreeInfo结构的下一个字段(即,偏移量为4字节),在攻击者控制的prev中的地址。在第14行,另外还有一个镜像写到Next所指向的位置。因此,为了避免运行时错误终止执行,prev和next都必须是有效的指针。
由于Emscripten分配的默认堆栈大小为5MB,低于5×220的值很可能可以安全写入。这对于覆盖函数表索引(见第4.3.1节)来说是绰绰有余的,这些索引最多只有几千的范围。
其他可能的攻击可能利用格式字符串漏洞、UAF和双重释放漏洞、单字节缓冲区溢出,或对内存管理进行更复杂的攻击。
4.2 Overwriting Data
当给出一个写操作原语,这里讨论了什么样的数据可以被覆盖。
4.2.1 Overwriting Stack Data
线性内存中的unmanaged stack中的function-scoped数据包含:如数组、结构体或者使用地址的变量。通过一个给定的完全灵活的写操作原语,攻击者可以覆盖任何潜在的关键本地数据,包括作为函数表索引的函数指针或安全关键函数的参数。
与原生平台不同的是,unmanaged stack上没有返回地址,故简单的buffer overflow并不好直接影响控制流。然而,如果堆栈向下增长,溢出操作可以达到所有当前活动的调用帧。因为没有返回地址或堆栈canary,溢出可以覆盖所有调用函数的本地数据,反倒没有因为返回地址异常提前终止的风险。
4.2.2 Overwriting Heap Data
Heap通常包含有较长寿命的数据,并会在不同的函数中存储复杂的数据结构。在WebAssembly中,由于完全确定的内存分配,对heap数据的定向写入是很简单的。更糟糕的是,即使是足够长的基于stack的线性缓冲区溢出也会破坏堆数据(因为heap位于最上方),而且没有任何机制,如保护页,可以阻止这种方法。
对于单一的线性内存,没有办法避免stack溢出或基于stack的缓冲区溢出。如果stack本身向上增长,stack溢会无声地破坏heap的数据。即使是stack向下增长(远离heap方向),但由于缓冲区溢出的方向是向上的,Stack-based Buffer Overflow就是罪魁祸首。
4.2.3 Overwriting “Constant” Data
在原生平台下,覆盖常数基本是不可能的。将数据声明为“constant”本身就是许多平台保护数据不被覆盖的一种方式,在执行过程中常数会被放在只读的内存中。
由于WebAssembly没有办法使数据在线性内存中保持不变,一个任意的写原语就可以改变程序中任何非标量常数的值,例如所有的字符串。甚至更多的受限制的写原语允许修改常量:图4b的内存布局的堆栈溢出可以写入恒定数据;同样,Stack-based Buffer Overflow可以达到图4c的内存布局中的恒定数据,因此,具有这两种能力的攻击者可以覆盖任何所谓的常量数据。
4.3 Triggering Unexpected Behavior
给出写原语、需要覆盖的数据,有许多方法可以让攻击者触发程序的异常行为。
4.3.1 Redirecting Indirect Calls
在WebAssembly中,与本地控制流攻击最接近的攻击方法是间接函数调用的重定向,这种类型的攻击允许执行通常不会在特定环境下执行的代码。
在第2节,我们已经说明了WebAssembly中的间接函数调用,攻击者可以通过覆盖间接调用指令使用的一个整数,这个整数用作table section中的一个索引,来重定向一个间接调用。正如第4.2节所述,这个整数值可能是unmanaged stack的局部变量,heap对象的一部分,在vtable中,甚至是一个所谓的常量值。
WebAssembly有两种机制限制攻击者重定向间接调用:
- 首先,并不是所有定义在WebAssembly二进制文件中或导出到二进制文件中的函数都出现在间接调用表中,而只是那些可能被间接调用的函数在table中;
- 其次,所有的调用,包括直接和间接调用,都要进行类型检查。因此,攻击者只能在相同类型的函数的等价类中重定向调用,类似于基于类型的CFI[15]。在第6节中,我们衡量这些机制在多大程度上减少了攻击者可以选择的可用调用目标。
4.3.2 Code Injection into Host Environment
WebAssembly模块可以通过各种方式与他们的host环境互动,以引起外部可见的效果。其中一种方式是调用JavaScript主机环境中臭名昭著的eval函数,它将给定的字符串解释为代码,为了访问eval,通过Emscripten编译的WebAssembly模块可以使用,例如,emscripten_run_script(它在host环境中执行JavaScript代码,无论是在浏览器中还是在基于Node.js的服务器端代码中)。在浏览器中,任何允许向文档添加代码的函数(例如,document.write)都可以作为eval函数的等价物;在Node.js中,API的低级特性为代码注入提供了更多的选择,例如,child_process模块的exec函数。
使用第4.1节和第4.2节中描述的原语,攻击者可以通过重写传递给类似eval的函数的参数来注入恶意代码。例如,假设WebAssembly通常用一个存储在线性内存中的 “常量 “代码串来调用eval,那么攻击者可以用恶意代码覆盖该常量。
4.3.3 Application-specific Data Overwrite
根据不同的应用程序,还可以有其他敏感的数据覆盖目标。例如,一个通过导入的函数发出网络请求的WebAssembly模块,可以通过覆盖目标字符串使其与不同的主机联系,以启动cookie窃取。作为进一步的例子,一些解释器和runtime已经被编译成WebAssembly,例如,直接在浏览器中执行CIL/.NET代码[5]。这类环境包含了许多显著改变程序行为的机会,例如,通过覆盖然后由运行时解释的字节码。
5. 端到端攻击方法
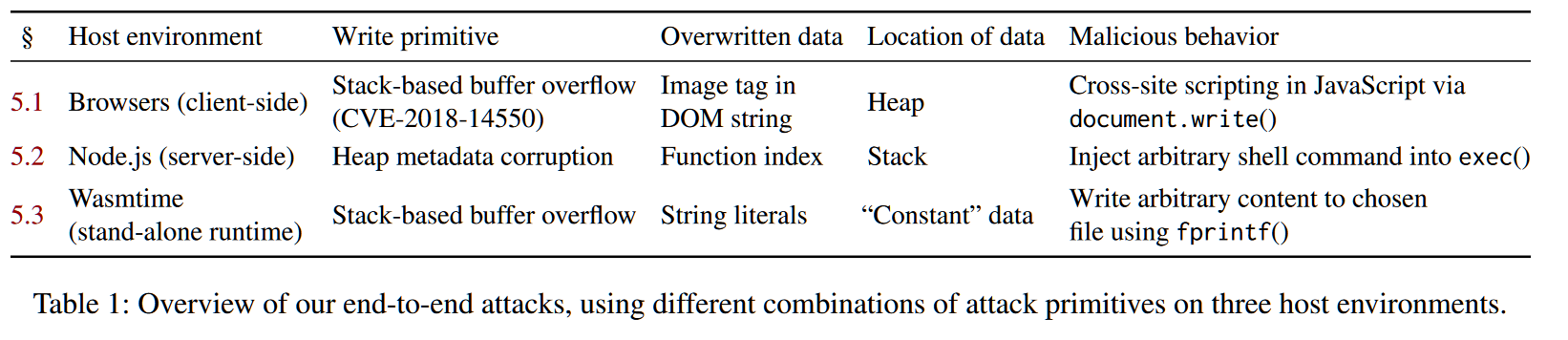
5.1 End-to-End Attacks
这一攻击表明,将编译为WebAssembly的易受攻击的代码纳入客户端Web应用程序,可以实现基于JavaScript的应用程序的已知攻击,如跨站脚本(XSS)。
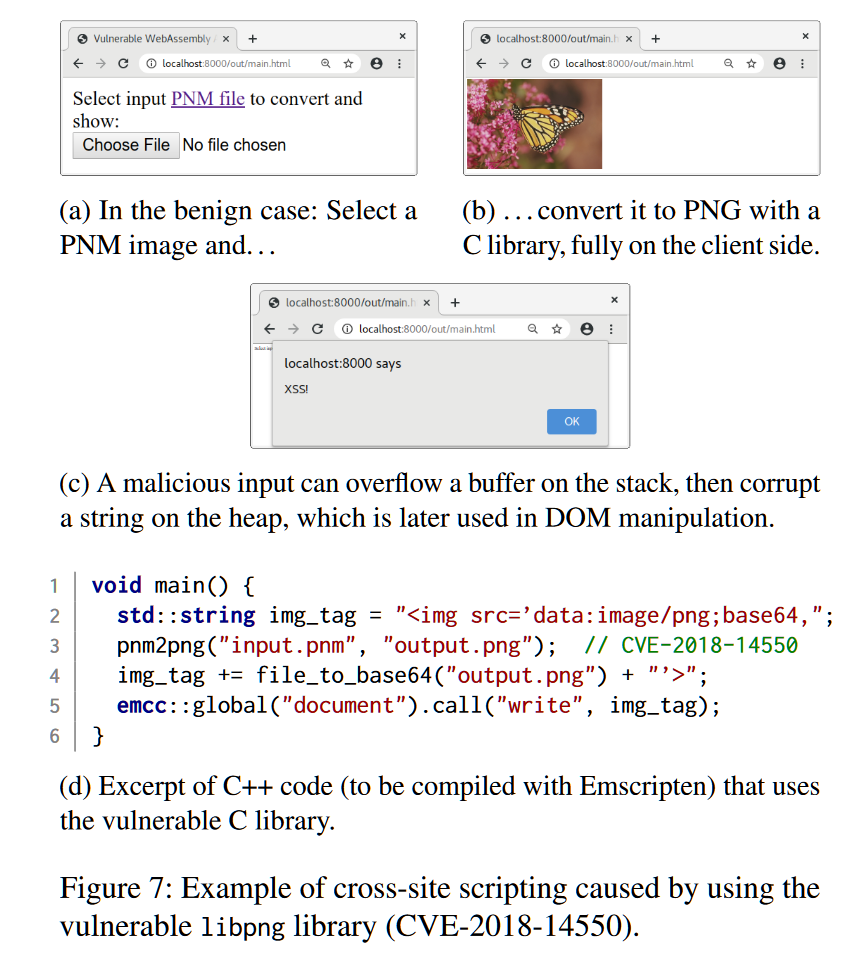
假设我们有一个图片服务网站,该服务提供了一个网络应用,其在客户端转换不同格式的图像,使用编译为WebAssembly的libpng图像编解码库。如上图所示,其可以将一个用户上传的PNM格式图像在本地转换为一个PNG格式图像,在转换完成后,通过DOM 操作函数(如document.write)展示该图片。
然而,1.6.35版本的libpng库有一个著名的buffer overflow漏洞(CVE-2018-14550),当进行图片格式PNM->PNG转换时可以被触发。在原生平台下,这个漏洞可以被stack canaries禁止,但在WASM平台下,这个漏洞可以不被限制的被利用。
具体利用方法如下:
- 攻击者提供给其他用户一个恶意图片,其被使用一个web应用输入并展示(如上图d):
- 在上图Line 3,其使用pnm2png函数转换格式;
- 在上图Line 4,将png文件编码为base64格式,并添加到img_tag中;
- 在上图Line 5,将img_tag加入document;
- 在Wasm中,字符串img_tag存储在heap中,通过stack-baesd buffer overflow可以修改它:
- 攻击者可以利用溢出将img_tag修改为一个script脚本;
- 恶意脚本会在Line 5被写入document;
- 取决于数据如何被上传,上述攻击可能导致反射型(非持久)XSS和持久型XSS,攻击者可以选择自己上传恶意脚本或者让用户上传,已达到不同的目的。
5.2 Remote Code Execution in Node.js
我们证明了在基于Node.js的应用程序中包含有漏洞的WebAssembly可以实现远程代码执行。

假设有一个记录对某些产品满意或不满意的客户的ID的服务器程序(如a),handle_request()函数接受三个input,其都可以被攻击者控制:
- input1表明顾客是否happy;
- input2表明表明input1的长度;
- input3表明顾客的id。
根据顾客的快乐程度,代码调用log_happy或log_unhappy,其通过将各自的函数分配给函数指针func来选择。如上图所示(Line 9),其通过memcpy函数来将input1的值复制进happiness数组中,但由于input2长度攻击者可控,就可以配合Line 12的free函数实现unlink exploit。通过这么操作,攻击者获得了一次写原语。
由于其通过函数指针来决定运行哪个函数,故函数指针func是存储在unmanaged stack中的,攻击者可以利用这个写原语来修改func的间接跳转目标。因为Wasm没有ASLR,故所有函数的地址都是确定的,这样的攻击非常容易实现,如图b所示,因为type类型相同,攻击者完全可以将控制流导向exec函数,并在覆盖func地址时向堆中注入一个合适的命令,然后将该命令的地址以input3传入,即可运行该命令。
5.3 Arbitrary File Write in Stand-alone VM
尽管独立的WebAssembly VM被宣传为执行C/C++代码的安全平台,但WebAssembly目前可以实现现代本地执行平台中不可能实现的攻击。

上图展示了一个将常量字符串加入一个静态已知文件的程序,只看Line 1-4,该功能明显是无害的。即使程序中有其他buffer overflow漏洞(Line 6-8),在原生平台中,其也是无害的,因为像“file.txt”这种字符串常量在x86中是存储在只读内存部分的,不可能被更改。
当运行一个WASM VM时:
- “file.txt”,“Append constant text.”等字符串都是存储在unmanaged线性内存中的data section(图b);
- 其可以被buffer overflow修改,故fopen函数就可以打开任意文件,并以任意模式写入任意内容。
6. 量化评估
为了更好地了解到目前为止所描述的攻击在实践中的真实性,我们现在对真实世界的WebAssembly二进制文件进行了定量评估。我们解决了以下研究问题:
- RQ1:有多少数据是存储在unmanaged stack上的?
- Unmanaged stack既可作为获得写原语的入口点,例如通过stack-based buffer overflow,也可作为覆写的目标,例如操纵敏感数据。
- RQ2:间接调用有多常见?有多少函数可以被间接调用涉及?
- 这个问题表明了通过重定向间接调用导致控制流被修改的风险有多大。
- RQ3:与目前的CFI相比,WebAssembly的type检查CFI防御效果如何?
- 由于WebAssembly VM对间接调用目标进行的运行时验证与CFI防御相似,我们在CFI等价类和类大小方面对两者进行了比较。
6.1 Experimental Setup and Analysis Process
Program Corpus
测试使用的二进制程序分为两部分:
真实世界的9个已部署的程序:
名称 描述 Adobe’s Document Cloud View SDK7 renders 可以在浏览器中渲染和注释PDF Figma8 一个合作的用户界面设计网络应用 1Password X 1.17 浏览器扩展插件,包含一个用于生成密码的WebAssembly组件。 Doom 3(《毁灭战士》系列) 一个大型游戏引擎移植到WebAssembly上 一组编解码器(webp, mozjpeg, optipng, hqx) 用于浏览器内的图像转换 这些二进制程序被应用在不同的领域(文档编辑、游戏、编码解码等),以及不同的语言(C、C++、Rust),所以我们相信这些样本是对真实Wasm样本分布的一个很好的初步近似。
SPEC CPU 2017基准套件中的17个C和C++程序,其被编译为WebAssembly:
SPEC CPU以前曾被用来研究WebAssembly的性能[37],它也被用来评估原生代码的CFI技术的安全性[21, 69],使我们能够解决RQ3。这些程序来自于计算量大的领域(编程语言的实现、模拟、视频编解码器、压缩),与WebAssembly的原始用例相匹配。

Static Analysis
为了解决我们的研究问题,我们开发了一个轻量静态分析工具。据我们所知,它是第一个用于WebAssembly二进制文件的安全分析工具,其是用Rust语言编写的,并且可以做到:
- 提取程序的一般信息,如指令数、函数数和它们的类型等;
- 通过推断哪个global是stack指针,哪个函数可以访问它,以及stack指针如何增减来分析unmanaged stack;
- 分析table section和其静态初始化,来查找哪些函数在其中表示,以及每个初始化table索引的函数类型;
- 分析间接调用edges,以提取允许call_indirect目标的静态编码类型,有多少函数符合该类型,对调用目标的额外限制,以及CFI等价类及其大小。
6.2 Measuring Unmanaged Stack Usage
这一节回答问题RQ1,有多少程序数据存储在unmanaged stack中。
6.2.1 Stack Analysis
我们的静态分析测量每个非import函数在unmanaged stack上的栈帧的大小,该分析在没有调试信息的优化、剥离的二进制文件上运行,就像现实中的攻击者一样,因此必须直接从字节码中推断出unmanaged stack的使用。
首先,分析需要确定stack指针。与本地二进制文件不同,这里不能使用固定寄存器(如x86上的rsp,在WebAssembly中不存在)或全局变量作为stack指针。相反,分析会提取所有修改globals的指令,并选择最经常被读写的指令。人工分析证实,这种启发式方法可靠地找到了stack指针。从确定的全局的静态初始化中,我们也知道了线性内存中unmanaged stack的基址。
其次,对于每个函数,分析推断出unmanaged stack上的栈帧的大小。在所有被分析的二进制文件中,先前确定的stack指针被修改,其协议类似于本地二进制文件中的**function prologue**和**function epilogue**。具体来说,我们的分析会匹配与下面的指令序列,并提取`delta`值,然后得出栈帧大小:

上图首先从全局变量$i读取当前的栈指针,然后增加或减少它(取决于堆栈是向上还是向下增长,见第3.2节),可以选择将它保存到一个局部变量(类似于一个基本指针),最后将修改后的值写回去。
**function prologue:**函数开头的几行汇编代码,它为堆栈和寄存器做准备,以便在函数中使用。
**function epilogue:**出现在函数的末尾的汇编代码,将堆栈和寄存器恢复到函数被调用前的状态。
6.2.2 Results
下图显示了所有被分析的二进制文件中栈帧大小的分布,包括直方图(图10a)和累积分布(图10b):
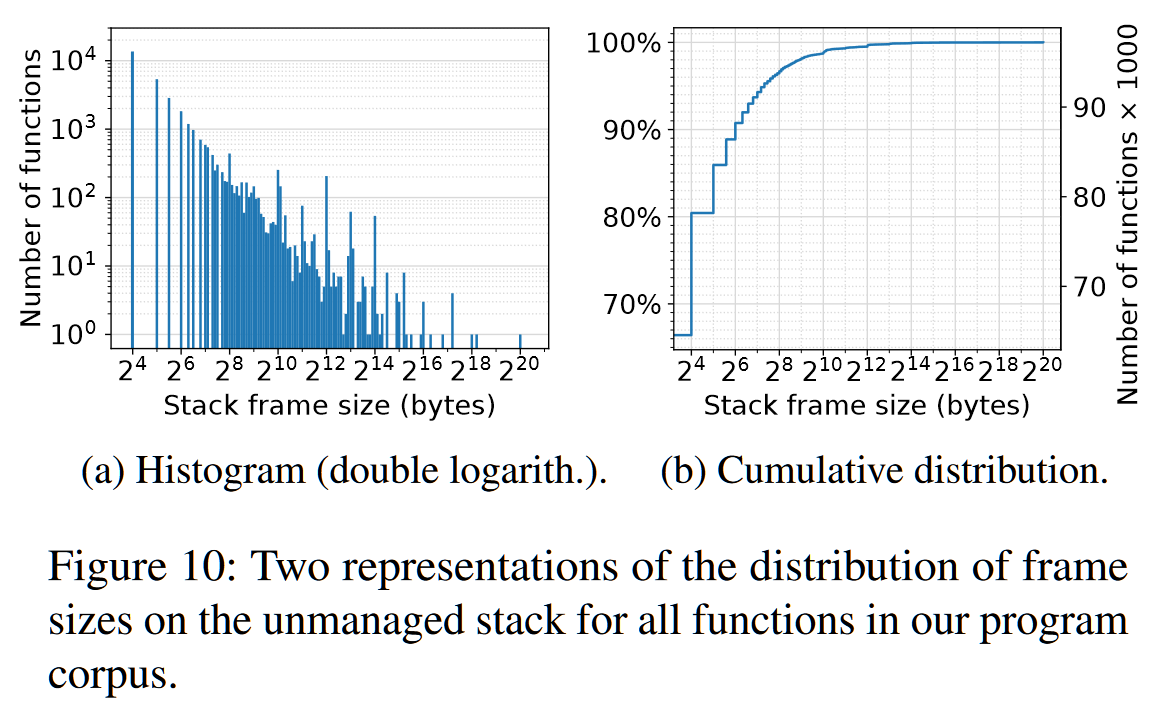
- 1/3(32,651)的函数在unmanaged stack中存储数据,最小的栈帧为16字节,由13620个函数(占所有函数的14%)分配;
- 栈帧的大小跨越从16字节到1MB的整个范围,1MB是最大的静态stack分配。从图10b的累积分布中,我们看到6%(6127)的函数在unmanaged stack上分配了128字节或更多,1.3%(1232)的函数分配了至少1KiB;
- 总的来说,许多函数使用了unmanaged stack,这不仅容易受到任意内存写入的影响,也容易受到缓冲区溢出的影响。这意味着,随着调用深度的增加,攻击者至少找到一些数据进行覆盖的机会也会迅速增加,例如,如果有10个嵌套调用(假设函数分布均匀),在unmanaged stack上会有一些数据的概率为$1-((1-0.33)^{10}) ≈ 98.2%$。
我们的结论是:
(1)Wasm 中存在大量的stack数据容易被缓冲区溢出和任意写原语覆盖;
(2)在unmanaged stack上隔离堆栈帧是很重要的,例如,使用canaries。
6.3 Measuring Indirect Calls and Targets
这一节回答问题RQ2,分析了间接调用。
6.3.1 Indirect Calls
我们对表2中的所有二进制文件进行了反汇编,并对call_indirect 指令的数量进行了统计。间接调用在所有调用中占的百分比在不同的程序中差异很大,其分布从0.6%到31.3%都有。
我们还发现,间接调用的比例与源语言是C还是C++无关,从所有26个程序的平均值来看,9.8%的调用指令是间接调用,也就是说,几乎每十个调用都有可能被转移到其他函数上。
6.3.2 Indirectly Callable Functions
想要成功地通过间接调用改变控制流,不仅需要间接调用指令,还需要找到合适的target函数(type相同,其该函数必须位于table中)。
我们的静态分析工具在程序启动时发现哪些函数在table中被初始化。Table中的条目不能被WebAssembly程序本身所操纵,原则上,host环境,如浏览器中的JavaScript,可以在运行时添加或删除条目。我们手动验证了由Emscripten生成的JavaScript代码不会修改该表,因此假设我们的分析精确地测量了间接调用的潜在目标。
表2中的“Indirectly Callable”表明了有多少函数在table中的同时至少跟一个call_indirect指令的type相吻合。可间接调用的函数的百分比从5%到77.3%不等,平均占程序corpus中所有函数的49.2%。
6.2.4 Function Pointers in Memory
上述分析给出了通过间接调用来劫持控制流的“上限”,但在实践中,如果传递给call_indirect的table索引来自一个局部变量、全局变量、或者是一连串指令运行的结果,那么攻击者可以选择的索引可能会更受限制。
为了找出这种攻击方式的“下限”,我们还测量了有多少table index是直接从内存中读取的,我们通过对间接调用之前的指令进行静态分析来获得这个数字。表2中的”Idx.from mem. “列显示了类型兼容和表内函数的数量,其中至少有一个间接调用直接从线性内存中获取其table index。
对于每个这样的函数,给定一个任意的写入线性内存的原语,一个间接调用就可以被转移以到该函数。也许令人惊讶的是,这个可达函数的“下限”与“上限”非常接近: 平均来说,48.1%的函数可以通过从线性内存中获取参数的间接调用来达到。
总的来说,我们对间接调用目标的分析显示了控制流劫持攻击的巨大潜力。许多函数是可以间接调用的(平均49.2%),而且大多数函数可以通过简单地覆盖存储在线性内存中的索引来达到(48.1%)。我们得出结论,间接函数调用对WebAssembly中控制流的完整性构成严重威胁。
6.4 Comparing with Existing CFI Policies
Wasm对于间接调用的type检查可以看做一种CFI,这里将WebAssembly的类型检查与最先进的本地二进制文件的CFI防御进行比较(RQ3)。
6.4.1 Equivalence Classes
按照先前关于CFI的工作[21],我们通过分析一个间接转移可能(根据CFI机制)被转移到的目标集合来衡量其有效性,这个集合就是CFI equivalence class。为了评估CFI防御的有效性,我们使用两个衡量标准:
- 类的数量,即存在多少个不同的类;
- 类的数量如果很小意味着CFI对目标的区分很小,给了攻击者更多控制流转移的选择。
- 类的大小,即每个类中有多少个目标;
- 类的大小如果很大意味着大量的target都可以由一个间接调用指令到达,也是不安全的。
对于WebAssembly,我们通过分析可间接调用的函数的类型签名来衡量CFI的等价类,将所有具有相同类型签名的函数分配到一个等价类。此外,我们还分析了间接调用之前的指令,以确定它们是否将表的索引限制在较小的范围内,例如,通过比特掩码。
表2的最后一列显示了分析结果,平均来说,每个程序有62个等价类,每个类包含33.2个函数。最大的等价类,在Blender程序中,包含超过5300个函数。总的来说,这表明攻击者有大量的调用目标可以选择。
6.4.2 Comparing with Native CFI Defenses
为了正确看待关于等价类的结果,我们将其与本地CFI的结果进行比较[21]。
如下图11a和图11b中的表格分别比较了等价类的数量和大小。例如,MCFI[48]和πCFI[49]将xalancbmk的控制流目标分别划分为1534和1200个类,而WebAssembly的间接调用目标限制只产生77个这样的类。关于等价类的大小,WebAssembly对omnetpp和xalancbmk的等价类特别大,而对其他程序的等价类大小与本地防御相似。
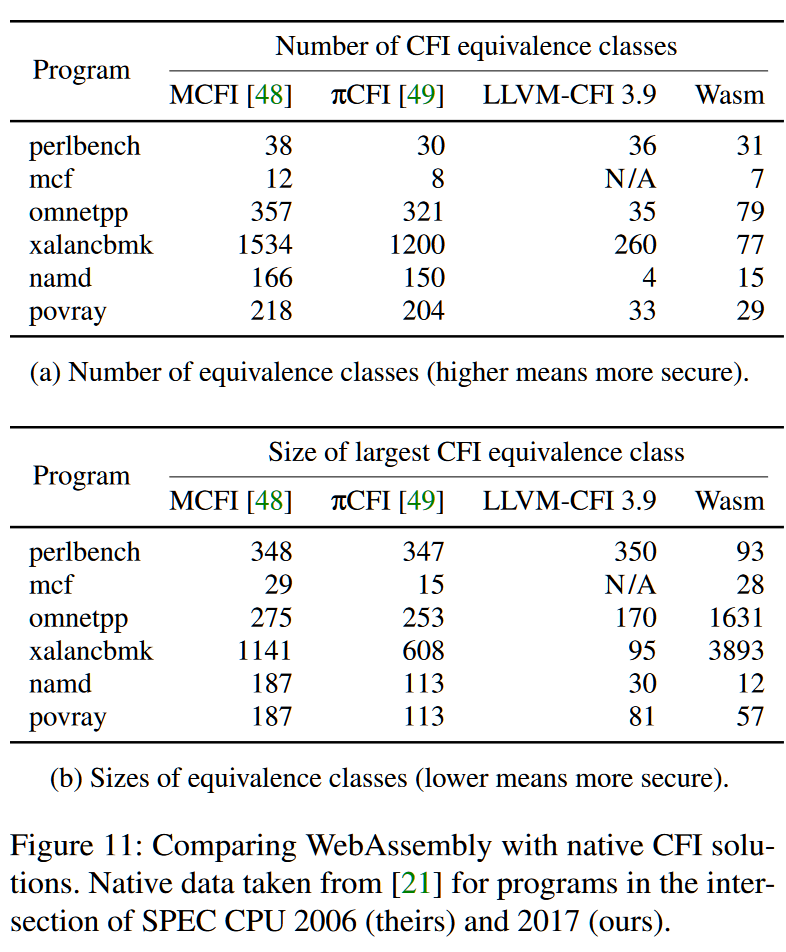
有趣的是,omnetpp和xalancbmk是大量使用虚拟函数的面向对象编程的C++程序。源码级的类型信息,例如关于类的层次结构,可以帮助基于编译器的CFI方法识别更精确的,从而限制的等价类。相比之下,WebAssembly的类型检查只有四种低级原始类型(组合)来处理,这可能解释了与本地方案的明显区别。
总的来说,WebAssembly的类型检查往往不如本地二进制文件的现代CFI防御措施有效。尽管与没有任何CFI防御措施相比,类型检查的间接调用当然是一个进步,但适应更复杂的CFI防御措施可以大大加强目前生产的二进制文件。例如,Clang的CFI方案使用源码级信息,在编译成WebAssembly时,也可以通过传递-fsanitize=cfi来使用。
7. 关于缓解措施的讨论
下面讨论了几种可以击败本文提出的攻击的缓解措施,例如,通过修改语言规范、更新编译器,或者由应用程序和库的开发者来实现。
7.1 WebAssembly Language
一些关于扩展核心WebAssembly语言的建议可以解决我们的一些攻击原语。
多存储器方案[54]给了一个模块拥有多个线性内存的选择。在该提议下,内存操作静态地编码它们操作的内存,例如,i32.load $mem2指令只能从内存2加载数据。多个内存将使堆栈、堆和常量数据分离。因此,一个内存部分的溢出将不再影响另一个内存的数据。
另外,指向heap的指针不能再被伪造成指向stack,反之亦然。最后,如果编译器只对一个特定的内存区发出加载指令,它就会变成有效的只读区域,因为对其他内存的存储不能修改它,这将防止对常量的修改。这个建议的一个挑战是,对多个内存进行编译并不简单。由于内存访问被静态地限制在某个内存中,必须处理不同区域指针的代码必须在内存之间重复或明确地复制对象。
参考类型方案[55]允许模块有多个表用于间接调用。我们的调用重定向攻击之所以强大,只是因为目前所有可间接调用的函数都在同一个表中。多个table可以实现更细化的防御,一种选择是定义不同的保护域,例如,每个静态链接库一个,并为每个保护域保留一个单独的表;另一个选择是将调用目标分成等价类,类似于现有的本地二进制文件的CFI技术,并为每个等价类保留一个单独的表。
MS-Wasm方案[26]明确地针对内存安全,它建议在WebAssembly中增加所谓的段(segment),即具有定义的大小和寿命的内存区域。进入这些段的处理程序被提升为第一类类型,有自己的分配和分片操作,这需要主机的一些实现工作,除非提供内存安全的硬件支持,否则可能会产生性能开销。
7.2 Compilers and Tooling
防止我们许多攻击原语的最简单方法是对编译器插桩,使编译器、链接器和分配器支持已经为本地编译目标提供的安全功能。几十年来对二进制安全的研究[61]已经产生了一些可以应用于WebAssembly的缓解措施。有利于 WebAssembly 编译器的例子是类似 FORTIFY_SOURCE 的代码重写、堆栈canaries、CFI 防御和内存分配器中的安全unlink。特别是对于堆栈canaries和overwirte通常被利用的C语言字符串函数,我们认为在部署上没有原则性的障碍。我们希望它们能在未来被编译器实现,因为它们能以相对较少的变化给生态系统带来良好的安全效益,而不像语言变化那样。
编译器中的一个较长期的缓解措施是使用上面讨论的WebAssembly语言扩展,一旦它们可用。例如,当把C/C++编译成WebAssembly时,多个内存可以模仿本地代码中页面保护所提供的一些安全功能。
7.3 Application and Library Developers
WebAssembly应用程序的开发者可以通过尽可能少地使用 “不安全 “语言(如C)的代码来降低风险。为了减少攻击面,开发者还应该确保只从主机环境中导入那些绝对必要的API。例如,调用关键的主机函数,如eval或exec是不可能的,除非这些函数在WebAssembly模块中被导入。