
UTOPIA: Automatic Generation of Fuzz Driver using Unit Tests
**时间:**2022
**作者:**Bokdeuk Jeong、Joonun Jang(Samsung Research)、Taesoo Kim(佐治亚理工)
**会议:**S&P’2023
Abstract
Fuzzing可以说是检测软件安全漏洞的最实用方法,但采用这种方法需要付出不小的努力。要想取得成效,高质量的fuzz driver程序应首先应当包含适当的 API 序列,以便详尽地探索程序状态。为减轻这一负担,现有解决方案试图通过从用户代码(即 API 的实际使用)中推断出有效的 API 序列,或直接从样本执行中提取 API 序列来生成fuzz driver程序。遗憾的是,所有现有方法都存在一个共同问题:观察到的 API 序列(无论是静态推断还是动态监控)都与自定义应用程序逻辑混杂在一起。然而,我们观察到,单元测试是由应用程序接口的实际设计者精心制作的,以验证其正确使用,而且重要的是,在开发过程中编写单元测试是一种常见做法(例如,超过 70% 的流行 GitHub 项目)。
在本文中,我们提出了一种开源工具和分析算法–UTOPIA,它可以从现有的单元测试中自动合成有效的fuzz driver程序,几乎不需要人工参与。为了证明其有效性,我们将 UTOPIA 应用于 55 个开源项目库,包括 Tizen 和 Node.js,并从 8K 个合格的单元测试中自动生成了 5K 个fuzz driver程序。此外,我们在每个内核上执行了约 500 万小时生成的fuzzer,发现了 123 个错误。更重要的是,2.4K 个生成的fuzz driver程序被Tizen项目的持续集成流程采用,这表明了合成fuzz driver程序的质量。为了让研究人员和从业人员更广泛地采用,我们公开并维护了所提出的工具和结果。
Background
最近,研究人员一直在探索一种方法,通过自动生成或合成fuzz driver程序来减轻library fuzzing人工集成的负担[12, 16, 18, 28]。他们通过随机推断源代码中的应用程序接口依赖关系[12, 16],或通过运行时观察到的执行轨迹[18, 28],为fuzzing制定了适当的应用程序接口序列。
更具体地说,最初的项目之一 Fudge[12],侧重于从消费者代码中直接还原适当的 API 调用序列,其中 API 使用和自定义应用程序逻辑相互交织。后续项目FuzzGen[16]通过对整个程序进行分析,从多个消费者代码中推理出 API 的依赖关系,理论上可以产生合理有效的fuzz driver程序(即推断出有效的 API 调用序列)。尽管这些方法具有通用性和广泛适用性,但它们所依赖的用户代码却存在根本性的局限。特别是,混合代码最终可能会生成过于简单的 API 序列/语义上无效的状态(例如,在一个代码中分配,而在其他地方使用)。从消费者代码的统计聚合中推断有效的 API 序列和依赖关系,会产生刻板的情况,这对于寻找无效、不常见输入的模糊器来说并不理想。
与试图推断 API 依赖关系的现有项目不同,我们在单元测试 (UT) 中使用了准确的 API 调用顺序,我们观察到:
- 现有的UT明确表达了开发人员所关心的 API 的这种依赖性;
- UT检查library所提供功能的各个方面,其API(如内部API)多于消费者代码;
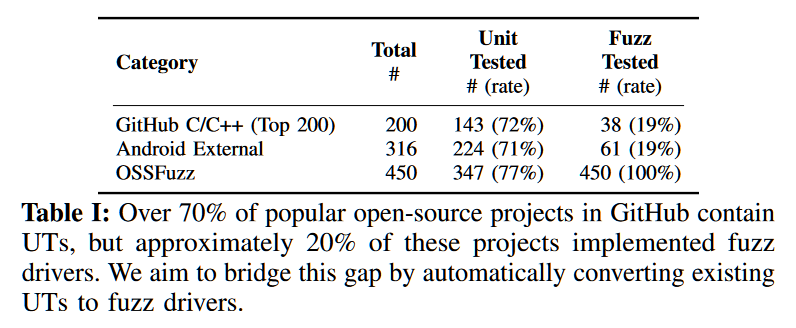
- 许多现有项目已经有了写得很好的UT–在来自 Github、Android 外部和 OSS-Fuzz的项目中占比73%。
Contribution
在本文中,我们提出了UTOPIA,利用各种技术,以自动化和可扩展的方式将现有的UT转换为有效的fuzz driver程序,UTOPIA背后的主要思想是:
利用UT的特定属性来揭示UT分析的复杂性;
执行root-definition analysis(一种新引入的技术)来追溯API参数的源头,以进行适当的fuzz input注入,从而保持开发人员所希望的程序间关系和数据流;
在fuzz input突变中反映对每个参数在其API内部可能产生的影响的分析。这样,UTOPIA 就能深入探索代码空间,避免因无效 API 使用而导致崩溃。因此,UTOPIA 可以提供一个push-button式解决方案,在没有人工参与的情况下自动合成高质量的fuzz driver程序。
本文的贡献如下:
- 我们提出了一种新的fuzz driver程序合成方法,该方法包含现有的单元测试,可自动生成fuzz driver程序;
- 我们利用 gtest 和 boost UT 框架,为 C/C++ 库实施了本方法的原型 UTOPIA,并通过经验验证,本方法可成功地将五千多的UT转化为 55 个开源项目库的有意义的fuzz driver程序;
- 我们报告了 123 个新漏洞,其中 70 个在责任披露过程中得到确认。
Model
1. 挑战
C1. 生成有效的API序列;
C2. 生成有效的API参数。
在fuzz driver中,library不仅可以因为bug崩溃,也可以是因为API的不当使用(如C1、C2),这种崩溃会严重影响fuzzing的进程。

上图是一个用OpenCV库读/写raw data的UT,UTOPIA 通过对原始 UT 代码进行细微修改,将 UT 转换为fuzz driver程序,以便将fuzz input分配给被分析为API参数来源的现有变量。
上图可以观察到UTOPIA对UT所做的改动,其将一些常数值变为了变量以将其分配给fuzzer进行改动(文章里的说法真巧妙啊:cupid:)
2. 方法
2.1 生成有效的API序列
2.1.1 先前工作的问题
如果要像以前的研究那样,对任何特定的消费者代码进行分析,则应决定对消费者代码做分析的程序。
一种可能的方法是对整个消费者代码进行分析,从而提取消费者内部的整个 API 使用模式。但是,如果遇到复杂的消费者代码,其中有大量 API 调用分散在复杂的控制流中,提取的模式可能会变得臃肿。这会导致驱动程序调用数十或数百次 API 调用,由于来自众多 API 的输入空间过于臃肿,这会阻碍驱动程序的fuzzing工作。
为了避免这种情况,一种方法是限制生成单个fuzz driver程序时所需要分析的用户代码量(例如,先前的工作[12, 16]仅对同一编译单元进行分析,以提取库 API 调用的使用情况)。虽然这缓解了之前序列臃肿的问题,但由于一些必要的 API 调用存在于不同的源文件中,这可能会导致获取的 API 序列不完整。此外,从这样的序列生成fuzz driver程序可能会产生虚假崩溃。
2.1.2 我们的方法
以前的研究侧重于从任何给定的消费者中正确重建有效的 API 序列,与此不同,我们利用单元测试中编写的显式 API 序列,完全避开了上述 API 序列合成的难题。
使用UT有两个好处:
- 在UT中为每个测试用例明确构建库状态,这意味着在生成模糊驱动程序时无需进行应用程序接口模式推理或提取;
- 这与fuzz driver程序的目的是一致的,即每个测试用例及其所包含的API序列,都是为了测试库开发人员认为必不可少的库的特定属性/变量而设计的。
在我们运行的示例中,这种方法使我们能够在代码中保持所有的 API 顺序关系,因为我们不会改变任何调用。此外,由于UT只包含测试库特定属性所需的简短API序列,UTOPIA不容易生成臃肿的API序列。
2.2 生成有效的API参数
2.2.1 Inferring inter-API semantics
有效语义的API之间的主要关系是:
- out-to-in: 一个API的输出是另一个API的输入;
- fixed: 每个 API 中的参数在所有 API 调用中都应相同;
- relative: 不同API的参数由同一值生成(x=f(y);API_1(x);z=x+g(y); API_2(z);)。
使用传统的程序内数据流分析方法,无法从一般消费者代码的使用中准确分析出应用程序间的关系,因为如果我们在输入fuzz input时不考虑程序间的数据流,就可能会忽略开发者的预期数据流,例如:
var a = 3;
b = func(a);
Target_API(b); 反之,如果只依赖程序内分析,则会将fuzz input分配给 b,而不是 a。另外,也可以通过API之间的参数类型别名来推断这种关系[16],但无法确定它们是否指的是同一个对象。在这种情况下,生成的fuzz driver程序无法反映参数之间的 API 间关系。
2.2.2 Inferring intra-API semantics
此外,还应考虑同一 API 中参数之间的关系,最常见的考虑因素包括与数组有关的因素:
- array↔length: 输入参数表示另一个输入数组参数的长度;
- array↔index: 输入参数是另一个数组输入参数的索引。
例如,Mat 类构造函数中的第一个参数(图 1 中第 14 行)要求与第二个和第四个参数中所述数组的大小相对应。如果对这两个参数进行随机fuzzing,驱动程序大多会导致故障(参数大小大于数组实际大小)或浪费精力更改未使用的fuzz input字节(参数大小小于数组实际大小)。
如果将 Fudge [12] 基于类型的模式匹配方法应用于这个示例,它将无法匹配第一个参数和第四个参数之间的逻辑关系,因为这种关系并没有明确地暴露在消费者代码中。虽然 FuzzGen [16] 的值集方法可以对应用程序接口的内部结构进行分析,但由于它推断的是单个参数的类型和值集,而不是参数之间的关系,因此在表示三个参数之间的关系时容易失败。
2.2.3 Detrimental input for fuzzing
虽然不属于滥用API,但我们注意到,有些参数在不经意地进行fuzzing时,会降低fuzzing的性能。例如,如果某个参数用于内存分配或循环计数,过大的数值经常会分别导致内存不足或超时错误。虽然这些并不是虚假崩溃,但往往同样会阻碍进一步的模糊探索。
为了保持有效的参数语义,UTOPIA 保留了 UT 中的原始数据流,并通过静态分析找到注入fuzz input(即fuzz target)的位置以及它们应该如何变异(API 属性)。为了识别注入fuzz input的合适位置,我们定义了一个新的root-definition analysis,即用常量定义变量的赋值语句。通过只在root-definition处分配fuzz input,我们可以保留原有的数据流,并自然地遵循现有的应用程序接口间语义,因为应用程序接口参数之间的流动是不间断的。在图 1 中,UTOPIA 通过在root-definition(第 23 行)中分配fuzz input,将fuzz input传递给写原始数据(writeRaw() API)中的第三个参数 rawdata(第 31 行),在根定义中,rawdata 向量的每个元素都被分配了常数。
找到根定义后,UTOPIA 会根据从根定义中获取值的 API 参数的属性分析注入模糊输入(确定属性的 API 静态分析详见第三节 B)。例如,在 Mat 类的构造函数中(图 1 中的第 18 行),UTOPIA 推断出了数组↔长度关系,并将 dim 的大小(数组属性)分配给第 18 行的第一个参数(ArrayLength 属性)和第 17 行的每个带有模糊输入的元素。
2.3 使用单元测试的独特挑战
然而,简单地将 UT 作为消费者提供给现有方法并不合适,因为使用 UT 会带来自身的一系列挑战 (UT-C)。
[……这里待更新,笔记着重了解fuzzing过程]