
(Part2)SoK: Sanitizing for Security
**作者:**Dokyung Song, Julian Lettner, Prabhu Rajasekaran(UC Irvine)
**会议:**S&P’19
Program Instrumentation
Sanitizer 通过在程序中嵌入***inlined reference monitors(IRM)***来执行其漏洞查找策略,这些IRM会监控和调和所有可能导致漏洞的程序指令,这些指令包括(但不限于)load和store、栈帧分配和释放、调用内存分配函数(如 malloc)和系统调用。IRM可以通过compiler、linker或instrumentation framework嵌入程序中。
1. Language-level instrumentation
Sanitizer 可以嵌入到源代码或抽象语法树(AST)级别。源代码和 AST 是特定于语言的,通常包含完整的类型信息、特定于语言的语法以及编译时评估的表达式,如 const_cast 和 static_cast 类型转换。当编译器将 AST 简化为中间表示(IR)代码时,这些特定于语言的信息通常会被丢弃。
这里建议(甚至有必要)对通过指针转换做监测来检测指针类型错误的 sanitizer 进行语言级插桩。
在Language-level instrumentation的另一个优势是,编译器会在编译的早期阶段保留程序的全部语义,因此,sanitizer 可以看到程序员希望看到的语义。在编译的后期阶段,编译器可能会假设程序不包含未定义的行为,并根据这一假设对代码进行优化(例如,消除看似不必要的安全检查)。Language-level instrumentation的缺点是,必须有应用程序的全部源代码,而且代码必须用预期的语言编写。因此,这种方法不适用于与封闭源代码库链接的应用程序,也不适用于包含内联汇编代码的应用程序[80]。
2. IR-level instrumentation
在编译的后期阶段,当AST转换为IR时,也可以在此处插入sanitizer,例如LLVM 等编译器后端支持 IR 级插桩[81]。这种方法比Language-level instrumentation更通用,因为IR(大部分)独立于源语言。因此,通过在这一级别进行插桩,sanitizer可以自动支持多种源语言。另一个优势是,编译器后端实现了各种静态分析和优化传递,可被 sanitizer 使用。sanitizer 可以利用这种基础架构来优化它们嵌入到程序中的 IRM(例如,通过删除多余的或可证明安全的检查)。
IR-level instrumentation的缺点与Language-level instrumentation大体相似,即不支持闭源库和内联汇编代码(第 V-A 节)。作为例外,***AddressSanitizer(ASan)***通过检测内联汇编块中的 MOV 和 MOVAPS 指令,为内联 x86 汇编代码提供了有限的支持[31]。不过,这种方法是针对特定体系结构的,需要针对每个支持的体系结构重新实现或复制。
3. Binary-level instrumentation
***Dynamic binary translation (DBT)***框架可以支持二进制程序在运行时进行插桩。[82]–[84]
在程序执行过程中,它们会读取程序代码、检测程序代码、将程序代码转换为机器代码,并暴露出各种hook来影响程序的执行。
与compiler-based的插桩方式相比,DBT-based instrumentation的主要优势在于它们能很好地处理闭源程序。此外,DBT 框架还能对用户模式代码提供完整的检测覆盖范围,无论其来源如何。DBT 框架可以检测程序本身、第三方代码(可能是动态加载的),甚至是动态生成的代码。
DBT 的主要缺点是运行时性能开销(远高于静态工具)(见第 VIII-E 节),这种开销主要归因于运行时的指令解码和翻译。使用Static Binary Instrumentation (SBI) 框架对二进制文件进行静态插桩可以部分解决这个问题。但是,SBI 和基于 DBT 的 sanitizer 都必须在几乎不包含任何类型信息或特定语言语法的二进制文件上运行。因此,现阶段不可能嵌入指针类型错误 sanitizer。有关堆栈框架和全局数据部分布局的信息也会在二进制级别丢失,这使得使用二进制仪器插入完全精确的空间内存安全 sanitizer 变得不可能。
4. Library Interposition
另一种方法是使用 Library Interposition拦截对库函数的调用[85],尽管这种方法非常的粗粒度。 Library Interposition是一个共享库,预加载到程序中时[86],可以拦截、监控和操作程序中的所有库间函数调用。一些 sanitizer 使用这种方法拦截对内存分配函数(如 malloc 和 free)的调用。
这种方法的优点是,与基于 DBT 的插桩类似,它也适用于 COTS 二进制文件,不需要源代码或目标代码。不过,与 DBT 不同的是, Library Interposition几乎不会产生任何开销。一个缺点是, Library Interposition仅适用于库间调用。同一库中两个函数之间的调用不能被拦截。另一个缺点是, Library Interposition高度针对特定平台和目标。例如,使用 Library Interposition来拦截对 malloc 调用的 sanitizer 就不适用于有自实现的内存分配器的程序。
Metadata Management
Sanitizer 设计的一个重要方面是如何存储和查找元数据,这种元数据通常捕获程序中使用的指针或内存对象的状态信息。尽管运行时性能并不是 sanitizer 开发人员或用户最关心的问题,但大多数 sanitizer 所存储的元数据数量之大,意味着即使存储方案中存在微小的低效,也会使 sanitizer 的运行速度慢得令人无法接受。元数据存储方案在很大程度上也决定了两个 sanitizer 是否可以结合使用。如果两个独立的 sanitizer 都使用改变了程序中的指针和/或对象表示的元数据方案,那么它们往往不能一起使用。
1. Object Metadata
有些 sanitizer 使用object元数据存储方案来存储所有已分配内存对象的状态,可能包括对象的大小、类型,状态(已分配/释放、已初始化/未初始化等),分配identifier等等。
- Embedded metadata
为对象存储元数据的一个显而易见的方法是增加其分配大小,并将元数据附加或预置到对象的数据中。这种机制在现代内存分配器中非常流行,例如,它可以在实际缓冲区之前存储缓冲区的长度。
使用工具可以修改内存分配器,在请求的缓冲区大小之外为元数据透明地保留内存,然后返回一个指向分配中间的指针,这样客户端就看不到元数据了。
ASan [31] 和 Oscar [36] 等软件都使用了Embedded metadata。ASan 在每个分配对象中嵌入了有关分配上下文的信息。Oscar 将每个对象的规范地址存储为嵌入式元数据。
- Direct-mapped Shadow
Direct-mapped shadow通过一些公式将应用程序内存中的每个 n 字节块映射为一个 m 字节元数据块,例如:

ASAN为每8字节的程序内存分配1字节影子内存:
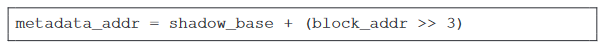
Direct-mapped Shadow易于实施并插入到应用程序中,它通常也非常高效,因为只需读取一次内存即可检索任何给定对象的元数据。不过,在某些情况下,这种方案也会导致运行时性能低下,因为它可能会使已经碎片化的地址空间中的内存碎片(以及空间位置性)更加恶化。由于影子内存区域是连续的,必须足够大才能镜像所有已分配的内存块(从最低虚拟地址到最高虚拟地址),因此也会浪费已分配的内存。
- Multi-level Shadow
Multi-level Shadow通过以目录表的形式引入额外的间接层,可以减少元数据存储的内存占用,这些目录表可以存储指向元数据表或其他目录表的指针,每个元数据表直接映射应用内存的一部分,与Direct-mapped Shadow方案类似。从整体上看,Multi-level Shadow类似于现代操作系统实现页表的方式。
有了额外的间接层,元数据存储就可以按需分配元数据表。它们只需自己分配目录表,元数据表的分配可以推迟到需要时再进行。这对于地址空间有限的系统(如 32 位系统)尤其有用,因为在这些系统中,实施Direct-mapped Shadow方案(如 ASan [31])的 sanitizer 经常会耗尽可用地址空间,导致程序终止。
需要按对象元数据(而不是按字节元数据)的工具可以使用variable-compression-ratio multilevel shadow mapping scheme,其中目录表将大小可变的对象映射为大小不变的元数据。这种方案可以帮助工具优化影子内存的使用和分配时的性能 [87]。
这种方案的主要特点是,每次元数据访问都需要多次内存访问:一次是对每一级目录表的访问,另一次是对相应元数据表的访问。这严重影响了性能,尤其是对于经常查找元数据的工具,例如边界检查工具,它的大多数内存访问都需要元数据访问。例如,TypeSan[70]就非常适合两级可变压缩比方案,因为类型元数据是按对象和大小恒定的,元数据查找并不频繁。
- Custom Data Structure
除了前面介绍的元数据方案之外,一些工具作者还选择了一系列自定义数据结构和特定工具解决方案来存储元数据。
J&K、CRED 和 D&A 等边界校验工具采用了拼接树(splay trees) [34]、[37]、[38]。
UBSan 和 CaVer 使用额外的哈希表作为缓存来存储类型检查的最新结果 [67], [69]。
DangNull 利用线程安全的红黑树来编码对象之间的关系 [58]。需要注意的是,当使用不支持并发访问的数据结构时,必须在多线程环境下使用显式锁进行保护。对于线程本地变量或堆栈变量,每线程元数据也是一种选择,例如 CaVer 针对堆栈和全局对象的每线程红黑树。
2. Pointer Metadata
- Fat Pointers:
有些 sanitizer 会用胖指针替换标准机器指针。胖指针是包含原始指针值以及与原始指针相关的元数据的结构。在许多按指针边界跟踪工具中使用的胖指针布局相当简单,只需替换如下数据结构:

- Tagged Pointers:
存储每个指针元数据的一种侵入性较小的方法是用标记指针取代普通的机器指针。标记指针将元数据嵌入指针本身,而不改变其大小。与胖指针相比,这种技术具有更好的兼容性。例如,将标记指针作为函数参数传递不需要修改标准调用约定。
3. Static Metadata
有些 sanitizer 需要编译器丢弃的某些信息,以便在运行时进行检查。
为了在运行时提供所需的编译时信息,这些 sanitizer 通常会在编译后的程序中嵌入静态元数据。例如,bad-casting sanitizer 会在编译时创建一个类型层次表(type hierarchy table),以便在运行时进行类型转换检查。HexVASAN 是一种变参函数 sanitizer,它为每个变参调用点建立静态元数据,以编码参数的数量及其类型。在运行时,被插桩的caller会将静态元数据推送到一个自定义堆栈中,被调用者会使用该堆栈检查所提供参数的有效性。
Driving a Sanitizer
Sanitizer只能在程序执行的时候检测到刚好位于执行路径上的Bug,因此在测试时达到更高的代码覆盖率,Bug检测几率就更高。
一般来说,Sanitizer可以配合unit test, integration test suite等人工手段,以及符号执行、Fuzzing等自动化手段一起使用。
Lettner 等人[95]证明了partitioned-sanitization,即在运行时根据覆盖率和执行速度等标准开启或关闭 sanitization,可以减轻sanitizer带来的运行时负担,提升测试效率。
Analysis
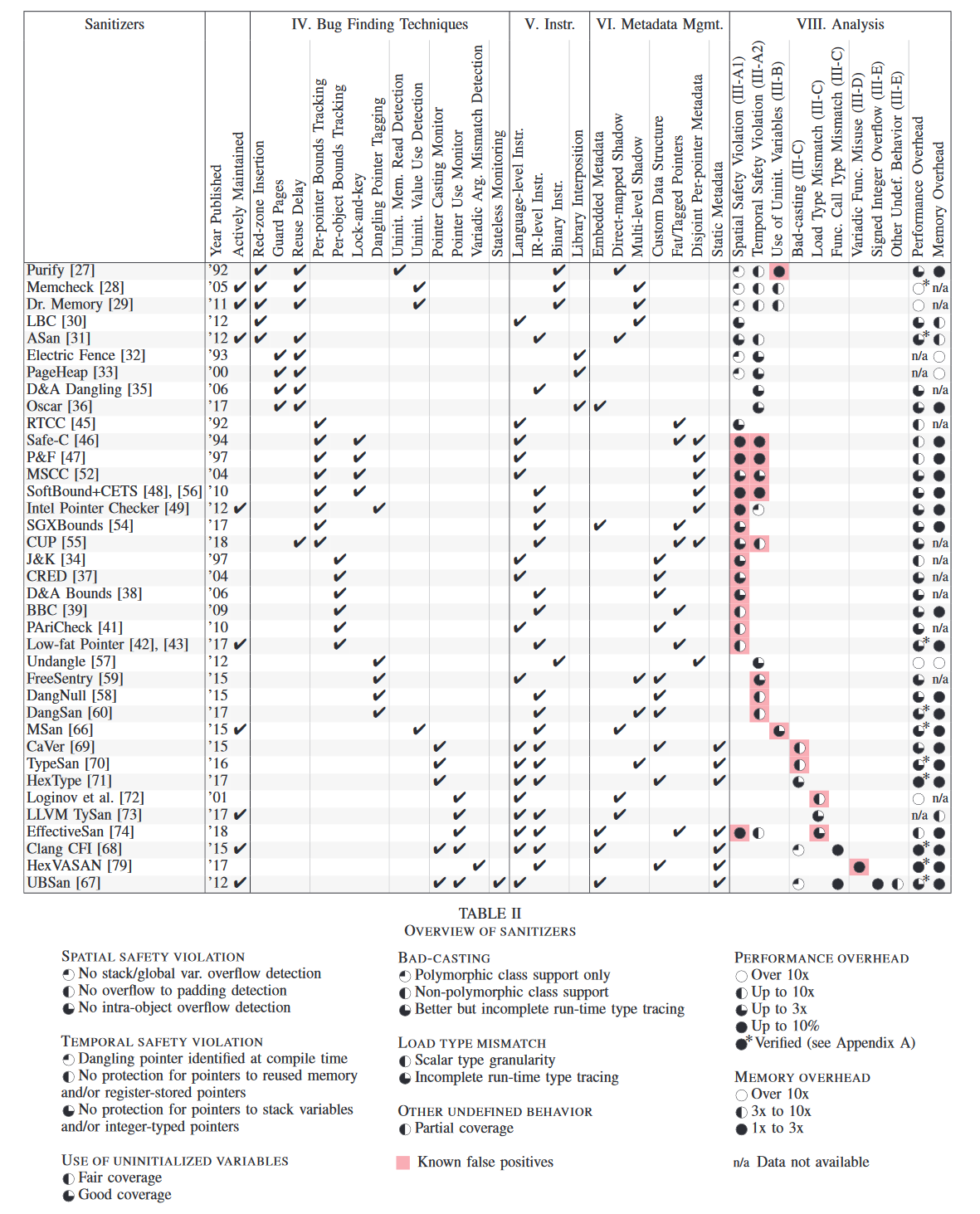
表 II 总结了正在积极维护(作为开源项目或商业产品)或在学术会议上发表的 sanitizer 的功能。我们收录的一些工具最初是作为exploit mitigation设计的,因此没有内置的错误报告机制。不过,这些工具确实符合我们对 sanitizer 的定义(参见第二节),因为它们可以精确定位漏洞代码的位置,如果与调试器结合使用,还可以提供有用的反馈。我们排除了 Intel Inspector [96]、ParaSoft Insure++ [75]、Micro Focus DevPartner [97] 和 UNICOM Global PurifyPlus [98],因为这些 sanitizer 缺乏公开信息,无法进行准确比较。
对于每一个 sanitizer,表格中都显示了它发现了哪些 bug、使用了哪些技术来发现这些 bug,以及使用了哪种元数据存储方案(如果有的话)。
饼形标记代表我们对该 sanitizer 有效性的评估,以及它在运行时间和内存开销方面的效率。彩色单元格表示该 sanitizer 会产生误报。我们将在第 VIII-A 节讨论产生误报的原因。我们在同一实验平台上使用相同的基准集运行了其中 10 种工具(即表 II 中性能开销单元标有星号的工具),验证了所报告的性能数据。我们在附录 A 中报告了这些工具的确切性能数据。
A. False Positives
对developer来说,最重要的考量因素是false positive,其次是false negative,也就是说sanitizer可以漏报,但尽可能不要误报,因为这会浪费开发者大量的时间来检查bug(与静态分析倒是完全相反的)。
最经常出现的问题是,sanitizer 实施的策略或机制往往比语言标准或事实标准更严格。事实上的标准(de facto standard)包括被广泛遵循的编程实践,而这些编程实践并不一定符合语言标准,尽管它们会产生无缺陷代码[99]。因此,我们可以认为,将不符合事实标准的行为报告为错误会构成假阳性检测。
…
[中间略]
Deployment
我们对目前使用的 sanitizer 进行了研究。我们的目标是确定 (i) 哪些sanitizers受到开发人员的青睐,(ii) 它们与那些不受青睐的sanitizers有何不同。
1. Methodology
我们编制了一份 GitHub 上前 100 个 C 和前 100 个 C++ 项目的列表,并检查了它们的build和test scripts、GitHub issues和Commit histories。我们审查的大多数 sanitizer 都需要在编译时集成到测试程序中。因此,程序的构建配置将揭示程序是否定期进行sanitizer。我们对测试套件和测试脚本的检查进一步显示了哪些 sanitizer 可以在测试过程中启用。与构建系统/配置文件相反,在运行时检测程序的 sanitizer(如 Memcheck)会在这里显示。
我们检查了 sanitizer 工具的网站,寻找使用 sanitizer 的项目的明确参考信息和对发现的错误的确认。
我们研究并比较了不同sanitizer的搜索趋势。我们将 ASan 作为搜索趋势的baseline,因为我们的研究表明它是目前使用最广泛的sanitizer。
2. Findings
- ASAN是使用最为广泛的Sanitizer;
- 其它基于LLVM的Sanitizer采用率较低;
3. Deployment Directions
更低的使用门槛、误报率都会提高Sanitizer的使用率。