
Semantic Host-free Trojan Attack
作者:Haripriya Harikumar , Kien Do, Santu Rana , Sunil Gupta , Svetha Venkatesh(迪肯大学.澳大利亚)
时间:2021.10.27
ABSTRACT 在本文中,我们提出了一种新颖的host-free木马攻击,其触发器(trigger)固定在语义空间(semantic),但不一定在像素空间(pixel)。
与现有的木马攻击使用干净的输入图像作为宿主来携带小的、没有意义的trigger不同,我们的攻击将trigger看作是属于语义上有意义的对象类的整个图像。
由于在我们的攻击中,与任何特定的固定模式相比,分类器被鼓励记忆触发图像的抽象语义。因此它可以在以后由语义相似但看起来不同的图像触发。这使得我们的攻击更实际地被应用于现实世界中,更难以防御。广泛的实验结果表明,仅用少量的特洛伊木马模式进行训练,我们的攻击能很好地推广到同一特洛伊木马类的新模式,并且可以绕过目前的防御方法。
Intrusion detection system-A comprehensive review
Intrusion detection system: A comprehensive review
作者:Hung-Jen Liao a , Chun-Hung Richard Lin a,n , Ying-Chih Lin a,b , Kuang-Yuan Tung a(国立中山大学,正修科技大学)
时间:2012
ABSTRACT 一个IDS综述。
PS:(17条消息) 防火墙、IDS和IPS之间的区别(浅谈)_淡风wisdon-大大的博客-CSDN博客
Def-IDS An Ensemble Defense Mechanism Against Adversarial Attacks for Deep Learning-based Network Intrusion Detection
Def-IDS: An Ensemble Defense Mechanism Against Adversarial Attacks for Deep Learning-based Network Intrusion Detection
作者:Jianyu Wang,Jianli Pan,Ismail AlQerm,(密苏里大学圣路易斯分校,重庆大学)
时间:2021
ICCCN,ccf–C类
ABSTRACT 提出了Def-IDS,一个为NIDS准备的组合防御机制。它是一个由两个模块组成的训练框架,组合了multi-class generative adversarial networks**(MGANs)**和multi-soutce adversarial retraining(MAT)。
在CSE-CIC-IDS2018数据集上测试了该机制,并与3个其它方法进行了比较。结果表明Def-IDS可以以更高的precision, recall, F1 score, and accuracy来识别对抗样本。
Crafting Adversarial Example to Bypass Flow-&ML- based Botnet Detector via RL
Crafting Adversarial Example to Bypass Flow-&ML- based Botnet Detector via RL
作者:Junnan Wang,Qixu Liu,Di Wu,Ying Dong,Xiang Cui(中国科学院大学,华为科技,北京维纳斯纲科技,广州大学)
时间:2021.10.6
会议:RAID(CCF_B)
1. Botnet(僵尸网络):1.1 定义: Botnet = robot + network。
—-参考《软件安全》.彭国军
1.2 如何攻击? 一个僵尸网络的生存周期包括**形成、C&C、攻击、后攻击**四个阶段。
形成阶段由攻击者入侵有漏洞的主机,并在其上执行恶意程序,使之成为僵尸主机。
一旦成为僵尸主机之后,botmaster会通过各种方式与之通信。
之后根据botmaster的指令执行攻击行为。后攻击阶段是指botmaster对僵尸网络进行升级更新。
2. Botnet Detector(僵尸网络检测器):2.1 传统方法: 从检测原理上来说,大致可以分为三类方法:
·行为特征统计分析
·bot行为仿真以监控
·流量数据特征匹配
传统的检测僵尸网络的方法一般在形成、攻击阶段,利用僵尸主机存在的行为特征,例如通信的数据内容。一些基于网络流量行为分析的方法可以检测僵尸网络,主要是从通信流量特征的角度去检测的,例如流量的通信周期,这种方法可以检测出一些加密的僵尸主机流量,同时还可以检测出新型的僵尸网络。
—-参考:解析:僵尸网络(Botnet)的检测方法-西湖泛舟-ChinaUnix博客
ABSTRACT 提出了一个基于RL的方法来对基于ML的僵尸网络追踪器做逃逸攻击,并且可以保留僵尸网络的恶意功能。
黑盒攻击,不用改变追踪器本身。
《最后的问题》
THE LAST QUESTION最后的问题第一次被半开玩笑地提出是在2061年的5月21日。那时人类文明刚刚步入曙光中。这个问题源起于酒酣之中一个五美元的赌,它是这么发生的:
亚历山大•阿代尔与贝特伦•卢泊夫是Multivac的两个忠实的管理员。像任何其他人一样,他们知道在那台巨大的计算机数英里冰冷、闪烁、滴答作响的面庞后藏着什么。那些电子回路早已发展到任何个别的人都无法完全掌握的地步,但他们至少对它的大致蓝图有个基本的概念。
Multivac能自我调节和自我修正。这对它是必要的,因为人类当中没有谁能够快甚至够好地对它进行调节和修正。所以实际上阿代尔与卢泊夫对这个庞然大 物只进行一些非常轻松和肤浅的管理,任何其他人也都只能做到这个程度。他们给它输送数据,根据它所需的格式修改问题,然后翻译给出的答案。当然,他们以及 其他管理员们完全有资格分享属于Multivac的荣誉。
几十年中,在Multivac的帮助下人类建造了宇宙飞船,计算出航行路径,从而得以登陆月球、火星和金星。但是更远的航行需要大量的能量,地球上可怜的资源不足以支持这些飞船。尽管人类不断地提高煤炭和核能的利用效率,但煤和铀都是有限的。
但是慢慢地Multivac学会了如何从根本上解决某些深层次问题。2061年5月14日,理论成为了现实。
太阳的能量被储存和转化,得以被全球规模地直接利用。整个地球熄灭了燃烧的煤炭,关闭了核反应炉,打开了连接到那个小小的太阳能空间站的开关。这个空间站直径一英里,在到月球的距离一半处环绕着地球。看不见的太阳的光束支撑着整个地球社会的运行。
七天的庆祝还不足以暗淡这创举的光辉。阿代尔与卢泊夫总算逃脱了公众事务,悄悄地相聚在这个谁也想不到的荒僻的地下室。在这里Multivac埋藏着的庞 大身躯露出了一部分。它正独自闲暇地整理着数据,发出满足的、慵懒的滴答声——它也得到了假期。他们了解这一点,一开始他们并没打算打扰它。
他们带来了一瓶酒。这会儿他们想做的只是在一起,喝喝酒,放松放松。
你想一想就会觉得很神奇,”阿代尔说。他宽阔的脸庞已有了疲倦的纹路。他慢慢地用玻璃棒搅动着酒,看着冰块笨拙地滑动。“从此我们所用的所有能量都是免费的。只要我们愿意,我们能把地球熔化成一颗液态大铁球——还能毫不在乎花掉的能量。够我们永远永远永远用下去的能量。”
卢泊夫将头歪向一边,这是当他想要反驳对方时的习惯动作。他现在确实想要反驳,部分原因是他在负责拿着冰和杯子。他说:“不是永远。”
“哦去你的,差不多就是永远。直到太阳完蛋,老贝。”
“那就不是永远。”
“好吧。几十亿年,可能一百亿年,满意了吧?”
卢泊夫用手梳着他稀薄的头发,仿佛要确认还剩下了一些。他缓缓地抿着自己的酒说,“一百亿年也不是永远。”
“但对我们来说是够了,不是吗?”
“煤和铀对我们来说也够了。”
“好好好,但是现在我们能把宇宙飞船连接到太阳能电站,然后飞到冥王星又飞回来一百万次而不用担心燃料。靠煤和铀你就做不到。不信去问问Multivac。”
“我不用问它。我知道。”
Learning Multiagent Communication with Backpropagation
【论文阅读】Learning Multiagent Communication with Backpropagation
作者: Sainbayar Sukhbaatar,Rob Fergus, Arthur Szlam(纽约大学,FacebookAI)
**时间:**2016
**出版社:**NIPS
Abstract 在AI领域许多任务都需要智能体之间的同心合作,一般地,代理之间的通信协议是人为指定的,其并不在训练过程中改变。在这篇文章中,我们提出了一个简单的神经模型CommNet,其使用持续不断的通信来完成完全合作的任务。该模型由许多代理组成,他们之间的通信基于设定的策略学习,我们将此模型应用于一系列不同的任务中,显示了代理学会相互通信的能力,从而比非通信代理的模型和baselines有更好的性能。
Learning to Communicate with Deep Multi-Agent Reinforcement Learning
【论文阅读】Learning to Communicate with Deep Multi-Agent Reinforcement Learning
作者:Jakob N. Foerster ,Yannis M. Assael ,Nando de Freitas,Shimon Whiteson(哈佛大学,Google Deepmind)
时间:2017
Abstract: 我们考虑这样一个问题:多个智能体在环境中通过感知和行动来最大化他们的分享能力。在这些环境中, 智能体必须学习共同协议以此来分享解决问题的必要信息。通过引入深度神经网络,我们可以成功地演示在复杂的环境中的端对端协议学习。我们提出了两种在这个领域学习的方法:**Reinforced Inter-Agent Learning (RIAL) **和 Differentiable Inter-Agent Learning (DIAL)。
前者使用深度Q-learning,后者揭示了在学习过程中智能体可以通过communication channels反向传播错误的梯度,因此,这种方法使用集中学习(centralised learning),分散执行(decentralised execution)。
我们的实验介绍了用于学习通信协议的新环境,展示了一系列工程上的创新。
PS:
1. 端对端(end-to-end,e2e), 将多步骤/模块的任务用一个步骤/模型解决的模型。
可以理解为从输入端到输出端中间只用一个步骤或模块,比如神经网络训练的过程就是一个典型的端对端学习,我们只能知道输入端与输出端的信息,中间的训练过程就是一个黑盒,我们知晓中间的训练过程。
2.centralised learning* but *decentralised execution,中心化学习但是分散执行。
近似误差与估计误差
【随手写】近似误差与估计误差
在读《统计学习方法》中关于k-邻近算法的介绍时,发现了这么一段话:

近似误差(Approximation Error): 训练时,训练集与当前模型的误差;
估计误差(Estimation Error): 训练完成后,所选择的模型已经固定,模型对未知数据拟合时的误差。
近似误差与估计误差二者不可兼得,此消彼长,需要取其平衡。
极大似然估计
【随写】极大似然估计(Maximum Likelihood Estimate,MLE)
“模型已定,参数未知。”
极大似然估计,就是利用已知的样本结果信息,反推最具有可能(最大概率)导致这些样本结果出现的模型参数值。
对于这个函数:$P(x|θ)$,
输入有两个:x表示某一个具体的数据;θ表示模型的参数。
如果θ是已知确定的,x是变量,这个函数叫做概率函数(probability function),它描述对于不同的样本点x,其出现概率是多少。
如果x是已知确定的,θ 是变量,这个函数叫做似然函数(likelihood function), 它描述对于不同的模型参数,出现x这个样本点的概率是多少。
一般说来,事件A发生的概率与某一未知参数θ有关,θ取值不同,则事件A发生的概率$P(A|θ)$也不同,当我们在一次试验中事件A发生了,则认为此时的θ值应是t的一切可能取值中使$P(A|θ)$达到最大的那一个,极大似然估计法就是要选取这样的t值作为参数t的估计值,使所选取的样本在被选的总体中出现的可能性为最大。
Adversarial Training with Fast Gradient Projection Method against Synonym Substitution Based Text Attacks
【论文阅读】Adversarial Training with Fast Gradient Projection Method against Synonym Substitution Based Text Attacks
时间:2020
**作者:王晓森,杨逸辰等 **华中科技大学
会议:AAAI
总结:
做了什么?
提出了一种速度更快的,更容易应用在复杂神经网络和大数据集上的,基于同义词替换的NLP对抗样本生成方法,FGPM;
将FGPM纳入对抗训练中,以提高深度神经网络的鲁棒性。
怎么做的?
实验结果?
- FGPM的效果不是最高的,但也跟最高的差不多,但生成对抗样本的时间对比同类方法,缩减了1-3个数量级。
- ATFL的对抗样本防御能力和抗转移能力很强。
Abstract:
对抗训练是对于提升图像分类深度神经网络鲁棒性的,基于实验的最成功的进步所在。
然而,对于文本分类,现有的基于同义词替换的对抗样本攻击十分奏效,但却没有被很有效地合并入实际的文本对抗训练中。
基于梯度的攻击对于图像很有效,但因为文本的词汇,语法,语义结构的限制以及离散的文本输入空间,不能很好的应用于基于近义词替换的文本攻击中。
因此,我们提出了一个基于同义词的替换的快速的文本对抗抗攻击方法名为Fast Gradient Projection Method (FGPM)。它的速度是已有文本攻击方法的20余倍,攻击效果也跟这些方法差不多。
我们接着将FGPM合并入对抗训练中,提出了一个文本防御方法,Adversarial Training with FGPM enhanced by Logit pairing(ATFL)。
实验结果表明ATFL可以显著提高模型的鲁棒性,破坏对抗样本的可转移性。
1 Introduction:
现有的针对NLP的攻击方法包括了:字符等级攻击,单词等级攻击,句子等级攻击。
对于字符等级的攻击,最近的工作(Pruthi, Dhingra, and Lipton 2019)表明了拼写检查器很容易修正样本中的扰动;
对于句子等级的攻击,其一般需要基于改述,故需要更长的时间来生成对抗样本;
对于单词等级的攻击,基于嵌入扰动的替换(replacing word based on embedding perturbation),添加,删除单词都会很容易改变句子的语法语义结构与正确性,故同义词替换的方法可以更好的处理上述问题,同时保证对抗样本更难被人类观察者发现。
但不幸的是,基于同义词替换的攻击相较于如今对图像的攻击展现出了更低的功效。
据我们所知,对抗训练,对图像数据最有效的防御方法之一,并没有在对抗基于同义词替换的攻击上很好的实施过。
一方面,现有的基于同义词替换的攻击方法通常效率要低得多,难以纳入对抗训练。另一方面,尽管对图像的方法很有效,但其并不能直接移植到文本数据上。
1.1 Adversarial Defense:
有一系列工作对词嵌入进行扰动,并将扰动作为正则化策略用于对抗训练(Miyato, Dai, and Goodfellow
2016; Sato et al. 2018; Barham and Feizi 2019) 。这些工作目的是提高模型对于原始数据集的表现,并不是为了防御对抗样本攻击,因此,我们不会考虑这些工作。
不同于如今现有的防御方法,我们的工作聚焦于快速对抗样本生成,容易应用在复杂的神经网络和大数据集上的防御方法。
2 Fast Gradient Projection Method(FGPM):

3 Adversarial Training with FGPM:
具体算法中文描述见:
《基于同义词替换的快速梯度映射(FGPM)文本对抗攻击方法》阅读笔记 - 知乎 (zhihu.com)
4 Experimental Results:
我们衡量FGPM使用四种攻击准则,衡量ATFL使用两种防御准则。
我们在三个很受欢迎的基准数据集上,同时包括CNN和RNN模型上进行测试,代码开源:https://github.com/JHL-HUST/FGPM
4.1 Baselines:
为了评估FGPM的攻击效能,我们将其与Papernot’、GSA ( Kuleshov等人的4种对抗性攻击进行了比较。2018 )、PWWS ( Ren et al . 2019 )和Iga ( Wang,jin,and he 2019 )。
此外,为了验证我们的ATFL的防御能力,我们采用了SEM ( Wang,Jin,He 2019 )和IBP ( Jia et al . 2019 ),针对上述Word-Level攻击。由于攻击基线的效率很低,我们在每个数据集上随机抽取200个示例,并在各种模型上生成对抗样本。
4.2 Datasets:
AG’s News, DBPedia ontology and Yahoo! Answers (Zhang,Zhao, and LeCun 2015).
4.3 Models:
我们使用了CNNs,RNNs,来达到主流的文本分类表现,所有模型的嵌入维度均为300。
4.4 Evaluation on Attack Effectiveness:
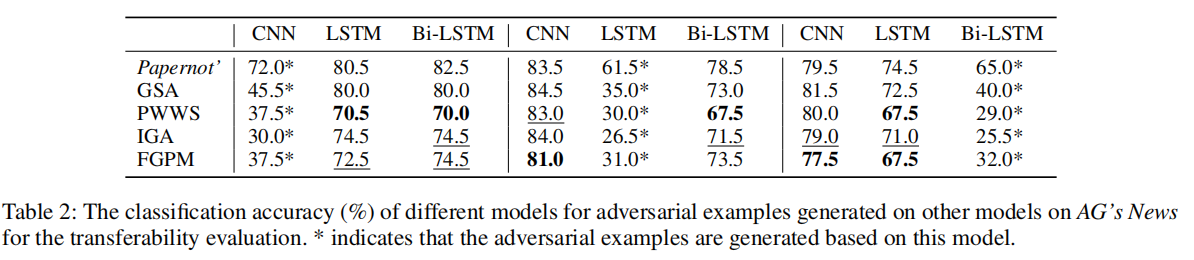
我们评估模型在攻击下的准确率和转移率:
准确率:
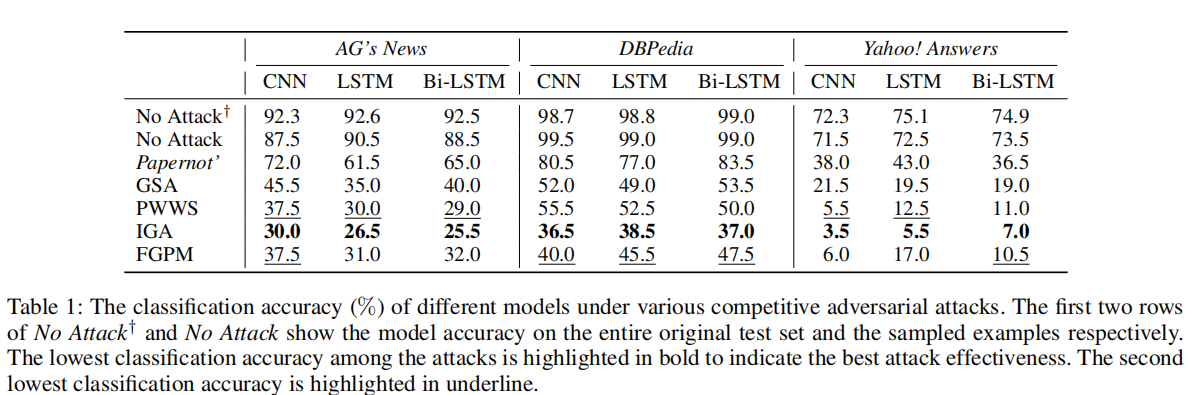
转移率:
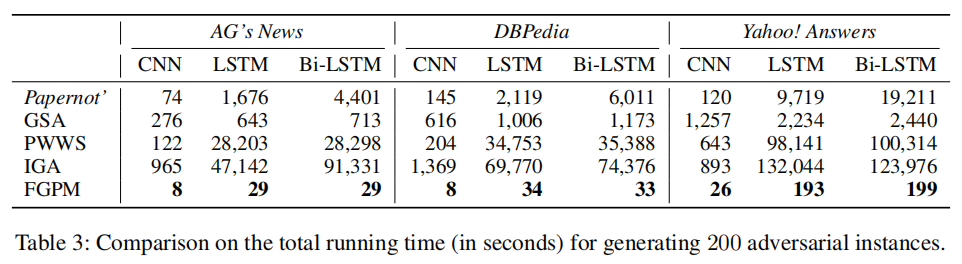
4.4 Evaluation on Attack Efficiency:
对抗训练需要高效率的生成对抗样本以有效地提升模型鲁棒性。因此,我们评估了不同攻击方法在三个数据集上生成生成200个对抗样本的总时间。
4.5 Evaluation on Adversarial Training:
我们评估ATFL的对抗样本防御能力和抗转移能力:
对抗样本防御能力:

抗转移能力:
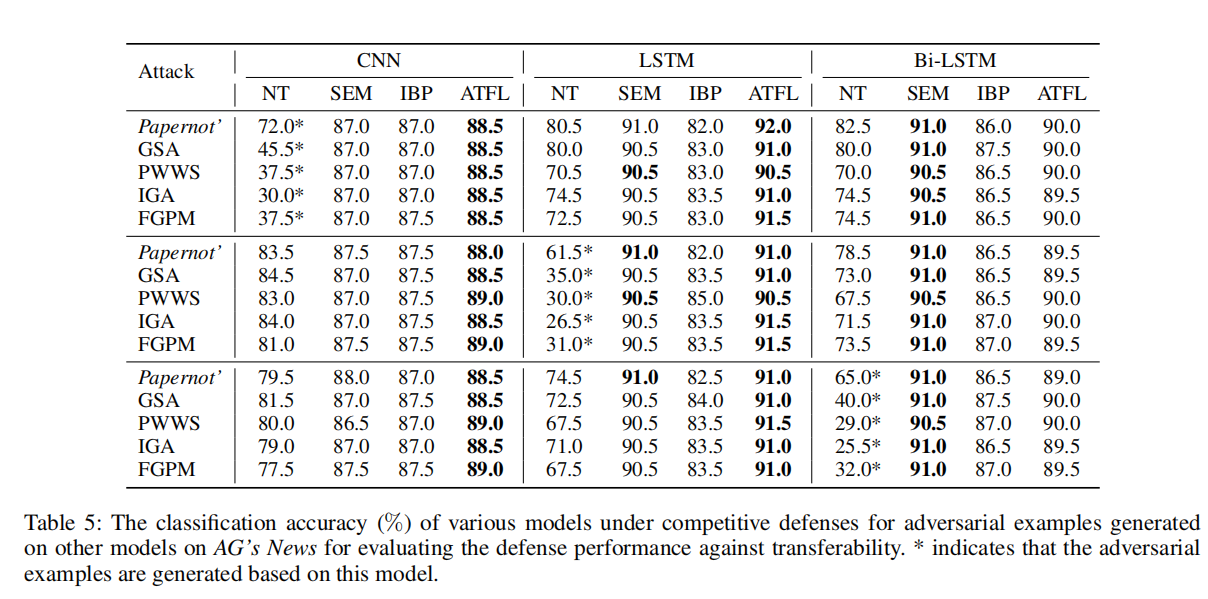
4.6 Evaluation on Adversarial Training Variants:
许多对抗训练的变体,例如CLP和ALP,TRADES等,已经尝试采用不同的正则化方法来提高针对图像数据的对抗训练准确率。
在这里,我们回答一个问题:这些变体方法也可以提高文本数据准确率吗?
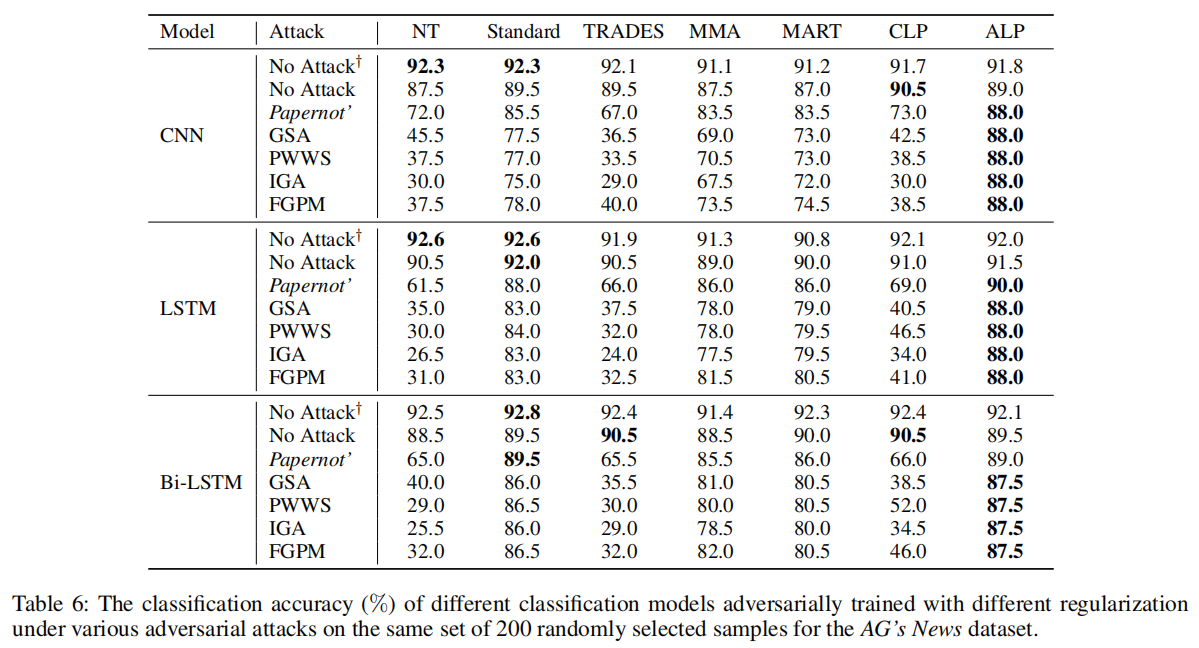
从表中可以看出,只有ALP可以长远地提升对抗训练的表现。