
【书籍阅读】《统计学习方法》一. 统计学习方法概论: 首先,要明确计算机科学中存在三个维度:系统,计算,与信息。统计学习方法(机器学习)主要属于信息这一维度,并在其中扮演者核心角色。
1. 监督学习概念: 监督学习,Supervised learning,指在已经做好标注的训练集上学习,为了叙述方便,定义以下基本概念:
**输入空间(X),输出空间(Y):**输入所有可能取值,输出所有可能取值;
**特征空间:**输入一般由特征向量表示,所有特征向量存在的空间称为特征空间,输入空间与特征空间并不完全等价,有时需要映射;
上标 x^i^ :表示一个输入的第 i 个特征;
**下标 xj:**表示第 j 个输入。
**回归问题:**输入输出都为连续型变量;
**分类问题:**输出变量为有限个离散型变量;
**标注问题:**输入与输出变量都为变量序列。
**假设空间:**所有可能的模型的集合,也就是学习的范围。
使用训练集学习—->对未知数据进行预测
AD nlp Survey
【论文阅读】AD nlp Survey
作者:Wei Emma Zhang(阿德莱德大学,澳大利亚)
QUAN Z. SHENG(麦考瑞大学,澳大利亚)
AHOUD ALHAZMI(麦考瑞大学,澳大利亚)
李晨亮(武汉大学,中国)
1. 关键词:DNN,对抗样本,文本数据(textual data),NLP2. 摘要:
传统对抗样本基本都针对计算机视觉领域;
本调查提供针对基于DNNs的NLP对抗样本攻击;
由于CV与NLP本身不同,方法不能直接移植;
集成了截止2017年所有的相关成果,综合性地总结,分析,讨论了40个代表性工作;
简单介绍了CV和NLP相关知识。
A Benchmark API Call Dataset For Windows PE Malware Classification
【论文阅读】A Benchmark API Call Dataset For Windows PE Malware Classification
作者:Ferhat Ozgur Catak(土耳其)
Ahmet Faruk Yazi(土耳其)
时间:2021.2.23
关键词:恶意软件分析,网络空间安全,数据集,沙箱环境,恶意软件分类
1. Abstract 在Windows操作系统中,系统API调用的使用在监控恶意PE程序中是一个很有前途的方法。这个方法被定义为在安全隔离的沙箱环境中运行恶意软件,记录其调用的Windows系统API,再顺序分析这些调用。 在这里,我们在隔离沙箱中分析了7107个属于不同家族(病毒,后门,木马等)的恶意软件,并把这些分析结果转化为了不同分类算法和方法可以使用的形式。 首先,我们会解释如何得到这些恶意软件;其次,我们会解释如何将这些软件捆绑至家族中;**最后,**我们会描述如何使用这些数据集来通过不同的方法实现恶意软件的分类。
A novel Android malware detection system-adaption of flter‑based feature selection methods
【论文阅读】A novel Android malware detection system: adaption of flter‑based feature selection methods
**时间:**2021
作者: Durmuş Özkan Şahin Oğuz Emre Kural · Sedat Akleylek Erdal Kılıç
总结:
二分类,静态代码检测;
创新点主要在特征提取(已经有的方法+文本分类的方法)上,分类器用的各种现成的方法;
Abstract: 在本研究中,提出了一个基于过滤器特征选择方法的,原创的安卓端恶意软件追踪系统。
该方法是一个在机器学习的基础上的静态安卓恶意软件追踪方法。在所开发的系统中,使用应用程序文件中提取的权限作为特征。八个不同的特征选择方法被用于维度降低,以减少运行时间,提升机器学习算法的效率。
其中四种方法应用于安卓恶意样本分类,其余四种方法是从文本分类研究中采用的,其从提取特征和分类结果两方面对方法进行了比较,在对结果进行检验时,表明所采用的方法提高了分类算法的效率,可以在本领域中使用。
Automatically Evading Classififiers----A Case Study on PDF Malware Classififiers
【论文阅读】Automatically Evading Classififiers—-A Case Study on PDF Malware Classififiers
时间:2016
作者:Weilin Xu, Yanjun Qi, and David Evans 弗吉尼亚大学
会议:NDSS
总结:
白盒黑盒?
黑盒攻击,需要知道生成样本在目标模型中的输出(分类分数)和目标模型所使用的特征(粗略知道);
针对什么目标?
仅仅使用表层特征的分类器;
攻击方法?
3.1 如何制造对抗样本?
使用**遗传算法(GP-BASED)**进行随机扰动
3.2 如何判别对抗样本的恶意能力?
使用oracle
Abstract:
在本文,我们提出了一个一般化的方法来检验分类器的鲁棒性,通过在两个PDF恶意样本分类器,PDFrate和Hidost上来检验。其关键就是随机控制一个恶意样本来找到一个对抗样本。
我们的方法可以自动地对500个恶意样本种子中找到对于两个PDF分类器的对抗样本,我们的结果提出了一个严重的疑问,基于表面特征的分类器在面对对抗样本时是否还有效?
1. Introduction:
主要贡献:
1. 提出了一个一般化的方法用于自动寻找分类器的对抗样本;
2. 制作了一个原型系统用于自动生成对抗样本;
3. 我们的系统在对500个恶意样本种子寻找对抗样本的过程中,达到了100%的准确率。
2. Overview:
2.1 Finding Evasive Samples:
整体思路:
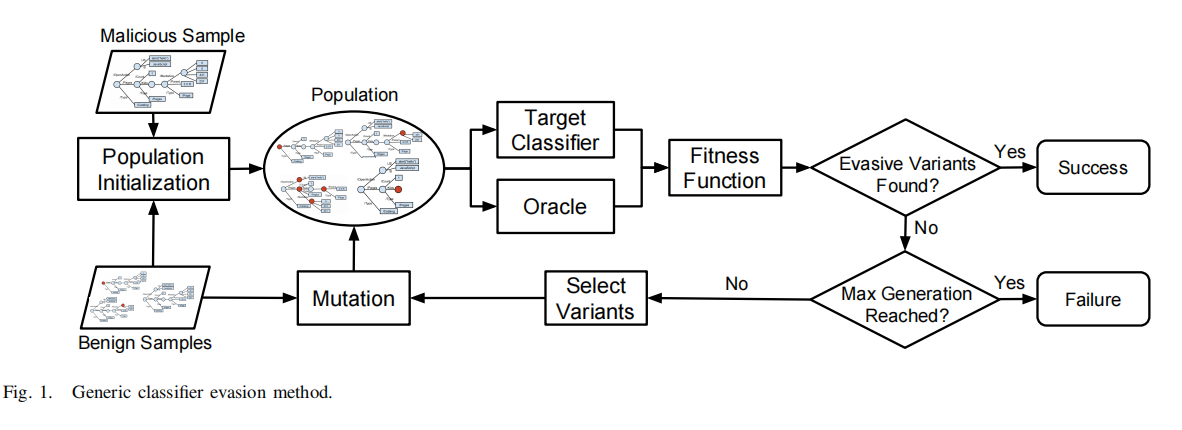
oracle用于判断一个样本是否具有恶意行为;
3. PDF Malware and Classifiers
3.1 PDFmalware:
PDF文件的整体结构:
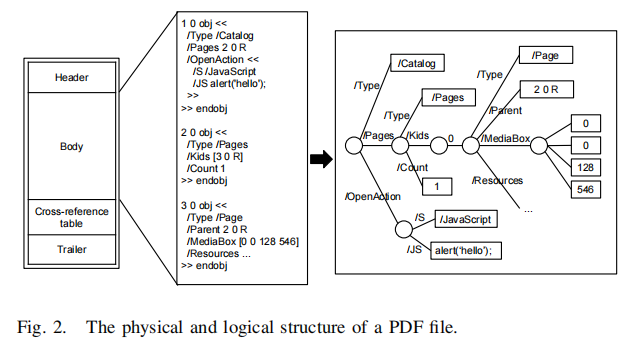
早些的PDF恶意样本一般使用JavaScript嵌入,用户双击打开时出发执行恶意脚本。
因为不是所有的PDF恶意样本都是嵌入了JavaScript代码,最近的一些PDF恶意分类器就着重于PDF文件的结构化特征。在本文,我们的目标就是攻击这些有代表性的基于文件结构化特征的分类器。
3.2 Target Classififiers:
**PDFrate:**一个使用随机森林算法的分类器。
**Hidost:**一个SVM分类器。
4. Evading PDF Malware Classifiers:
5. Experiment:
5.1 Dataset:

5.2 Test:
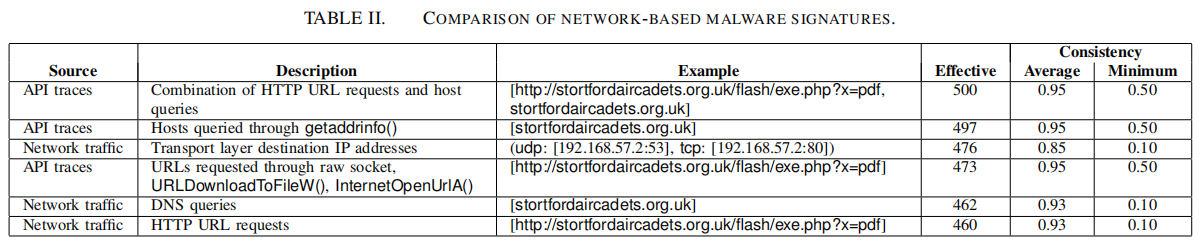
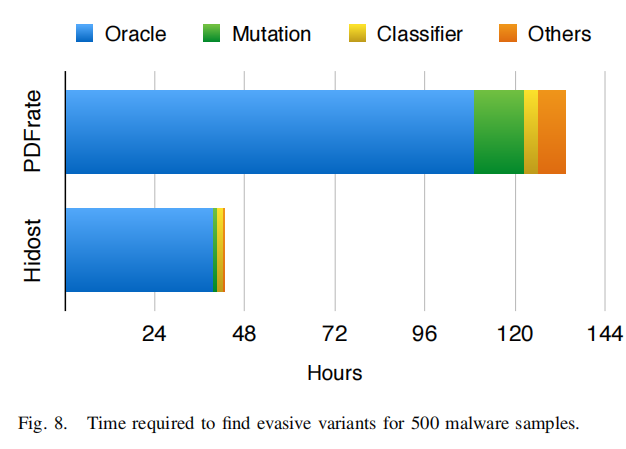
Black-Box Attacks against RNN based Malware Detection Algorithms
【论文阅读】Black-Box Attacks against RNN based Malware Detection Algorithms
时间:2017
作者: Weiwei Hu 北京大学
Ying Tan 北京大学
Abstract: 1. 原文:
最近的研究表明,基于机器学习的恶意软件分类算法在面对对抗样本攻击时表现的十分脆弱。这些工作主要集中于那些利用了混合维度的特征的追踪算法,但一些研究者已经开始使用RNN,基于API特征序列来辨识恶意软件。
这篇文章提出了一种用于生成对抗样本序列的原创算法,它被用于攻击基于RNN的恶意软件分类系统。对于攻击者来说,通常,知晓目标RNN的内部结构和权重是很难的。于是一个替代的用于近似目标RNN的RNN模型就被训练了出来,接着我们利用这个RNN来从原始序列输入中生成对抗样本序列。
权威结果表明基于RNN的恶意软件分类算法不能追踪大多数我们所生成的恶意对抗样本,这意味着我们生成的模型可以很有效的规避追踪算法。
2. 总结:
一个对基于RNN的恶意样本分类器的灰盒攻击,有三个RNN,受害者RNN(源RNN),替代RNN,对抗样本生成RNN。
Deep Text Classifification Can be Fooled
【论文阅读】Deep Text Classifification Can be Fooled
**时间:**2017
**作者:**Bin Liang, Hongcheng Li, Miaoqiang Su, Pan Bian, Xirong Li and Wenchang Shi 中国人民大学
Abstract: 在这篇文章,我们提出了一种有效的生成文本对抗样本的方法,并且揭示了一个很重要但被低估的事实:基于DNN的文本分类器很容易被对抗样本攻击。
具体来说,面对不同的对抗场景,通过计算输入的代价梯度(白盒攻击)或生成一系列被遮挡的测试样本(黑盒攻击)来识别对分类重要的文本项。(这句不是很懂,什么叫’ the text items that are important for classifification‘?)
基于这些项目,我们设计了三种扰动策略,insertion,modification,removal,用于生成对抗样本。实验结果表明基于我们的方法生成的对抗样本可以成功地欺骗主流的在字符等级和单词等级的DNN文本分类器。
对抗样本可以被扰动到任意理想的类中而不降低其效率。(?)同时,被引入的扰动很难被察觉。
Generic Black-Box End-to-End Attack Against State of the art API Call Based Malware Classifiers
【论文阅读】Generic Black-Box End-to-End Attack Against State of the art API Call Based Malware Classifiers
**作者:Ishai Rosenberg **
大学:Ben-Gurion University of the Negev
时间:2018.6.4
1. 做了什么?
对一个通过机器学习训练的,通过API调用来分类恶意软件的分类器的攻击。
这个攻击可以使分类器不能成功识别恶意软件,并且不改变原有软件的功能。
实现了GADGET,一个可以直接将二进制恶意软件文件转换为分类器无法检测的二进制文件,并不需要访问文件源代码。
2. 一些概念:
2.1 Machine learning malware classififiers(基于机器学习的恶意软件分类器)
优点:1. 可以自动训练,节省时间;
2. 只要分类器并不是基于指纹特征或者某个特定的特征(如Hash值)来分类,面对不可见威胁时泛化能力较强。
2.2 Adversarial Examples(对抗样本)
对输入样本故意添加一些人无法察觉的细微的干扰,导致模型以高置信度给出一个错误的输出。
- 可以针对一张已经有正确分类的image,对其进行细微的像素修改,可以在DNN下被错分为其他label。

样本x的label为熊猫,在对x添加部分干扰后,在人眼中仍然分为熊猫,但对深度模型,却将其错分为长臂猿,且给出了高达99.3%的置信度。

像素攻击:改动图片上的一个像素,就能让神经网络认错图,甚至还可以诱导它返回特定的结果。
改动图片上的一个像素,就能让神经网络认错图,甚至还可以诱导它返回特定的结果
2. 同样,根据DNN,很容易产生一张在人眼下毫无意义的image,但是在DNN中能够获得高confidence的label。

两种EA算法生成的样本,这些样本人类完全无法识别,但深度学习模型会以高置信度对它们进行分类,例如将噪声识别为狮子。
2.2.1: Adversarial examples for API sequences(生成API序列对抗样本与生成图像对抗样本并不同):
- API序列由长度可变的离散符号组成,但图像可以用固定维度的矩阵表示为矩阵,且矩阵的值是连续的。
- 对于对抗API序列,其必须验证原始的恶意功能是完整的。
- 对抗样本的迁移性:针对一种模型的对抗样本通常对另一种模型也奏效,即使这两个模型不是用同一数据集训练的。
2.3 几种攻击方法:
White-box attack:白盒攻击,对模型和训练集完全了解。
Black-box attack:黑盒攻击:对模型不了解,对训练集不了解或了解很少。
Real-word attack:在真实世界攻击。如将对抗样本打印出来,用手机拍照识别。
targeted attack:使得图像都被错分到给定类别上。
non-target attack:事先不知道需要攻击的网络细节,也不指定预测的类别,生成对抗样本来欺骗防守方的网络。
mimicry attack: 编写恶意的exploit,该exp模拟良性代码系统调用的痕迹,因为能够逃逸检测。
disguise attack: 仅修改系统调用的参数使良性系统调用生成恶意行为 。
No-op attack: 添加语义的no-ops-系统调用,其没有影响,或者是不相干的影响,即,打开一个不存在的文件。
Equivalence attack: 使用一个不同的系统调用来达到恶意的目的.
2.4 decision boundary(决策界限)
2.5 end-to-end:
2.6 结果分类:
虑一个二分问题,即将实例分成正类(positive)或负类(negative)。对一个二分问题来说,会出现四种情况。如果一个实例是正类并且也被 预测成正类,即为真正类(True positive),如果实例是负类被预测成正类,称之为假正类(False positive)。相应地,如果实例是负类被预测成负类,称之为真负类(True negative),正类被预测成负类则为假负类(false negative)。
列联表如下表所示,1代表正类,0代表负类。(预测正确:true,预测是正类:positive)
| 预测 | ||||
|---|---|---|---|---|
| 1 | 0 | 合计 | ||
| 实际 | 1 | True Positive(TP) | False Negative(FN) | Actual Positive(TP+FN) |
| 0 | False Positive(FP) | True Negative(TN) | Actual Negative(FP+TN) | |
| 合计 | Predicted Positive(TP+FP) | Predicted Negative(FN+TN) | TP+FP+FN+TN |
从列联表引入两个新名词。
其一是真正类率(true positive rate ,TPR), 计算公式为 TPR=TP/ ( TP+ FN),刻画的是分类器所识别出的 正实例占所有正实例的比例。
另外一个是负正类率(false positive rate, FPR),计算公式为 *FPR= FP / (FP + TN),*计算的是分类器错认为负类的正实例占所有负实例的比例。
还有一个真负类率(True Negative Rate,TNR),也称为specificity,计算公式为TNR= TN/ ( FP+ TN) = 1 - FPR。
3. 如何实现?
一些问题:程序调用API的过程;